 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdam-HNAG: A Convergent Reformulation of Adam with Accelerated Rate
Apr 09, 2026Adam has achieved strong empirical success, but its theory remains incomplete even in the deterministic full-batch setting, largely because adaptive preconditioning and momentum are tightly coupled. In this work, a convergent reformulation of full-batch Adam is developed by combining variable and operator splitting with a curvature-aware gradient correction. This leads to a continuous-time Adam-HNAG flow with an exponentially decaying Lyapunov function, as well as two discrete methods: Adam-HNAG, and Adam-HNAG-s, a synchronous variant closer in form to Adam. Within a unified Lyapunov analysis framework, convergence guarantees are established for both methods in the convex smooth setting, including accelerated convergence. Numerical experiments support the theory and illustrate the different empirical behavior of the two discretizations. To the best of our knowledge, this provides the first convergence proof for Adam-type methods in convex optimization.
Neural Modular Physics for Elastic Simulation
Dec 17, 2025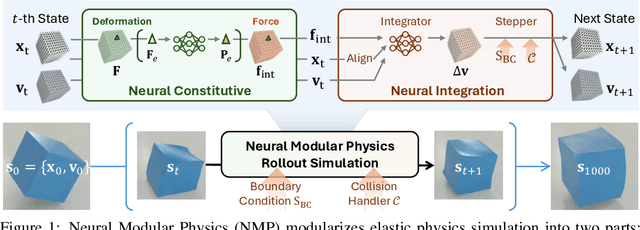
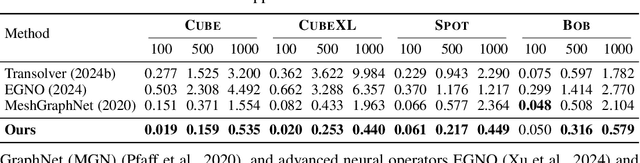
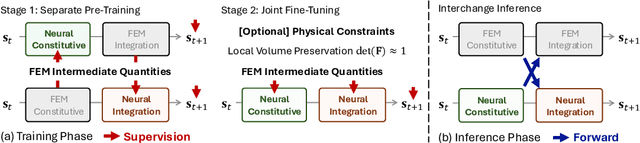
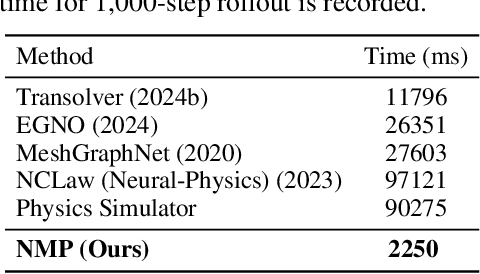
Learning-based methods have made significant progress in physics simulation, typically approximating dynamics with a monolithic end-to-end optimized neural network. Although these models offer an effective way to simulation, they may lose essential features compared to traditional numerical simulators, such as physical interpretability and reliability. Drawing inspiration from classical simulators that operate in a modular fashion, this paper presents Neural Modular Physics (NMP) for elastic simulation, which combines the approximation capacity of neural networks with the physical reliability of traditional simulators. Beyond the previous monolithic learning paradigm, NMP enables direct supervision of intermediate quantities and physical constraints by decomposing elastic dynamics into physically meaningful neural modules connected through intermediate physical quantities. With a specialized architecture and training strategy, our method transforms the numerical computation flow into a modular neural simulator, achieving improved physical consistency and generalizability. Experimentally, NMP demonstrates superior generalization to unseen initial conditions and resolutions, stable long-horizon simulation, better preservation of physical properties compared to other neural simulators, and greater feasibility in scenarios with unknown underlying dynamics than traditional simulators.
AMR-Transformer: Enabling Efficient Long-range Interaction for Complex Neural Fluid Simulation
Mar 13, 2025



Accurately and efficiently simulating complex fluid dynamics is a challenging task that has traditionally relied on computationally intensive methods. Neural network-based approaches, such as convolutional and graph neural networks, have partially alleviated this burden by enabling efficient local feature extraction. However, they struggle to capture long-range dependencies due to limited receptive fields, and Transformer-based models, while providing global context, incur prohibitive computational costs. To tackle these challenges, we propose AMR-Transformer, an efficient and accurate neural CFD-solving pipeline that integrates a novel adaptive mesh refinement scheme with a Navier-Stokes constraint-aware fast pruning module. This design encourages long-range interactions between simulation cells and facilitates the modeling of global fluid wave patterns, such as turbulence and shockwaves. Experiments show that our approach achieves significant gains in efficiency while preserving critical details, making it suitable for high-resolution physical simulations with long-range dependencies. On CFDBench, PDEBench and a new shockwave dataset, our pipeline demonstrates up to an order-of-magnitude improvement in accuracy over baseline models. Additionally, compared to ViT, our approach achieves a reduction in FLOPs of up to 60 times.
AFIDAF: Alternating Fourier and Image Domain Adaptive Filters as an Efficient Alternative to Attention in ViTs
Jul 16, 2024We propose and demonstrate an alternating Fourier and image domain filtering approach for feature extraction as an efficient alternative to build a vision backbone without using the computationally intensive attention. The performance among the lightweight models reaches the state-of-the-art level on ImageNet-1K classification, and improves downstream tasks on object detection and segmentation consistently as well. Our approach also serves as a new tool to compress vision transformers (ViTs).
Learning Physical Simulation with Message Passing Transformer
Jun 10, 2024Machine learning methods for physical simulation have achieved significant success in recent years. We propose a new universal architecture based on Graph Neural Network, the Message Passing Transformer, which incorporates a Message Passing framework, employs an Encoder-Processor-Decoder structure, and applies Graph Fourier Loss as loss function for model optimization. To take advantage of the past message passing state information, we propose Hadamard-Product Attention to update the node attribute in the Processor, Hadamard-Product Attention is a variant of Dot-Product Attention that focuses on more fine-grained semantics and emphasizes on assigning attention weights over each feature dimension rather than each position in the sequence relative to others. We further introduce Graph Fourier Loss (GFL) to balance high-energy and low-energy components. To improve time performance, we precompute the graph's Laplacian eigenvectors before the training process. Our architecture achieves significant accuracy improvements in long-term rollouts for both Lagrangian and Eulerian dynamical systems over current methods.