 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating AI Grading on Real-World Handwritten College Mathematics: A Large-Scale Study Toward a Benchmark
Mar 01, 2026Grading in large undergraduate STEM courses often yields minimal feedback due to heavy instructional workloads. We present a large-scale empirical study of AI grading on real, handwritten single-variable calculus work from UC Irvine. Using OCR-conditioned large language models with structured, rubric-guided prompting, our system produces scores and formative feedback for thousands of free-response quiz submissions from nearly 800 students. In a setting with no single ground-truth label, we evaluate performance against official teaching-assistant grades, student surveys, and independent human review, finding strong alignment with TA scoring and a large majority of AI-generated feedback rated as correct or acceptable across quizzes. Beyond calculus, this setting highlights core challenges in OCR-conditioned mathematical reasoning and partial-credit assessment. We analyze key failure modes, propose practical rubric- and prompt-design principles, and introduce a multi-perspective evaluation protocol for reliable, real-course deployment. Building on the dataset and evaluation framework developed here, we outline a standardized benchmark for AI grading of handwritten mathematics to support reproducible comparison and future research.
Deep Image Prior with L0 Gradient Regularizer for Image Smoothing
Jan 19, 2026Image smoothing is a fundamental image processing operation that preserves the underlying structure, such as strong edges and contours, and removes minor details and textures in an image. Many image smoothing algorithms rely on computing local window statistics or solving an optimization problem. Recent state-of-the-art methods leverage deep learning, but they require a carefully curated training dataset. Because constructing a proper training dataset for image smoothing is challenging, we propose DIP-$\ell_0$, a deep image prior framework that incorporates the $\ell_0$ gradient regularizer. This framework can perform high-quality image smoothing without any training data. To properly minimize the associated loss function that has the nonconvex, nonsmooth $\ell_0$ ``norm", we develop an alternating direction method of multipliers algorithm that utilizes an off-the-shelf $\ell_0$ gradient minimization solver. Numerical experiments demonstrate that the proposed DIP-$\ell_0$ outperforms many image smoothing algorithms in edge-preserving image smoothing and JPEG artifact removal.
SEMA: a Scalable and Efficient Mamba like Attention via Token Localization and Averaging
Jun 10, 2025Attention is the critical component of a transformer. Yet the quadratic computational complexity of vanilla full attention in the input size and the inability of its linear attention variant to focus have been challenges for computer vision tasks. We provide a mathematical definition of generalized attention and formulate both vanilla softmax attention and linear attention within the general framework. We prove that generalized attention disperses, that is, as the number of keys tends to infinity, the query assigns equal weights to all keys. Motivated by the dispersion property and recent development of Mamba form of attention, we design Scalable and Efficient Mamba like Attention (SEMA) which utilizes token localization to avoid dispersion and maintain focusing, complemented by theoretically consistent arithmetic averaging to capture global aspect of attention. We support our approach on Imagenet-1k where classification results show that SEMA is a scalable and effective alternative beyond linear attention, outperforming recent vision Mamba models on increasingly larger scales of images at similar model parameter sizes.
Beyond Discreteness: Finite-Sample Analysis of Straight-Through Estimator for Quantization
May 23, 2025Training quantized neural networks requires addressing the non-differentiable and discrete nature of the underlying optimization problem. To tackle this challenge, the straight-through estimator (STE) has become the most widely adopted heuristic, allowing backpropagation through discrete operations by introducing surrogate gradients. However, its theoretical properties remain largely unexplored, with few existing works simplifying the analysis by assuming an infinite amount of training data. In contrast, this work presents the first finite-sample analysis of STE in the context of neural network quantization. Our theoretical results highlight the critical role of sample size in the success of STE, a key insight absent from existing studies. Specifically, by analyzing the quantization-aware training of a two-layer neural network with binary weights and activations, we derive the sample complexity bound in terms of the data dimensionality that guarantees the convergence of STE-based optimization to the global minimum. Moreover, in the presence of label noises, we uncover an intriguing recurrence property of STE-gradient method, where the iterate repeatedly escape from and return to the optimal binary weights. Our analysis leverages tools from compressed sensing and dynamical systems theory.
AFIDAF: Alternating Fourier and Image Domain Adaptive Filters as an Efficient Alternative to Attention in ViTs
Jul 16, 2024We propose and demonstrate an alternating Fourier and image domain filtering approach for feature extraction as an efficient alternative to build a vision backbone without using the computationally intensive attention. The performance among the lightweight models reaches the state-of-the-art level on ImageNet-1K classification, and improves downstream tasks on object detection and segmentation consistently as well. Our approach also serves as a new tool to compress vision transformers (ViTs).
An Image Segmentation Model with Transformed Total Variation
Jun 04, 2024Based on transformed $\ell_1$ regularization, transformed total variation (TTV) has robust image recovery that is competitive with other nonconvex total variation (TV) regularizers, such as TV$^p$, $0<p<1$. Inspired by its performance, we propose a TTV-regularized Mumford--Shah model with fuzzy membership function for image segmentation. To solve it, we design an alternating direction method of multipliers (ADMM) algorithm that utilizes the transformed $\ell_1$ proximal operator. Numerical experiments demonstrate that using TTV is more effective than classical TV and other nonconvex TV variants in image segmentation.
Global Well-posedness and Convergence Analysis of Score-based Generative Models via Sharp Lipschitz Estimates
May 25, 2024We establish global well-posedness and convergence of the score-based generative models (SGM) under minimal general assumptions of initial data for score estimation. For the smooth case, we start from a Lipschitz bound of the score function with optimal time length. The optimality is validated by an example whose Lipschitz constant of scores is bounded at initial but blows up in finite time. This necessitates the separation of time scales in conventional bounds for non-log-concave distributions. In contrast, our follow up analysis only relies on a local Lipschitz condition and is valid globally in time. This leads to the convergence of numerical scheme without time separation. For the non-smooth case, we show that the optimal Lipschitz bound is O(1/t) in the point-wise sense for distributions supported on a compact, smooth and low-dimensional manifold with boundary.
COMQ: A Backpropagation-Free Algorithm for Post-Training Quantization
Mar 11, 2024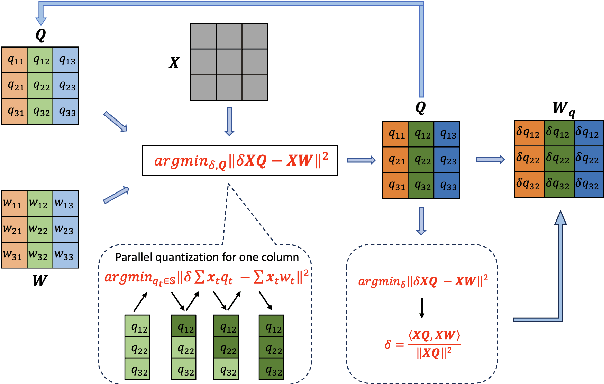
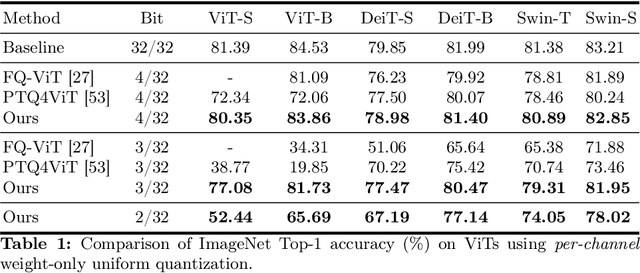
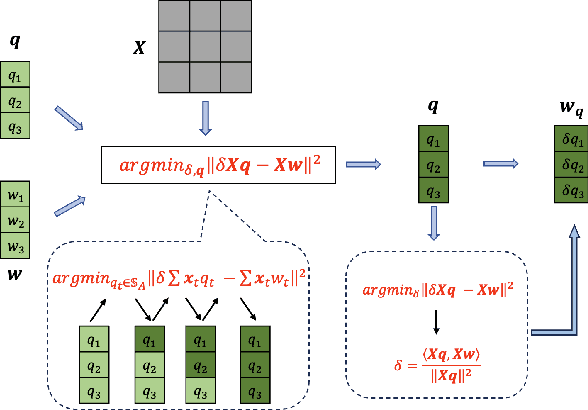
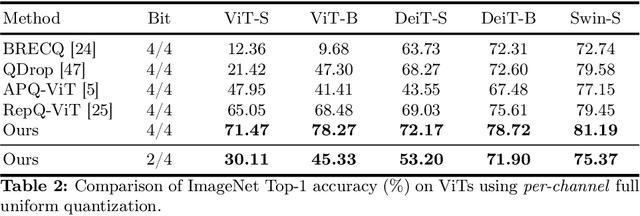
Post-training quantization (PTQ) has emerged as a practical approach to compress large neural networks, making them highly efficient for deployment. However, effectively reducing these models to their low-bit counterparts without compromising the original accuracy remains a key challenge. In this paper, we propose an innovative PTQ algorithm termed COMQ, which sequentially conducts coordinate-wise minimization of the layer-wise reconstruction errors. We consider the widely used integer quantization, where every quantized weight can be decomposed into a shared floating-point scalar and an integer bit-code. Within a fixed layer, COMQ treats all the scaling factor(s) and bit-codes as the variables of the reconstruction error. Every iteration improves this error along a single coordinate while keeping all other variables constant. COMQ is easy to use and requires no hyper-parameter tuning. It instead involves only dot products and rounding operations. We update these variables in a carefully designed greedy order, significantly enhancing the accuracy. COMQ achieves remarkable results in quantizing 4-bit Vision Transformers, with a negligible loss of less than 1% in Top-1 accuracy. In 4-bit INT quantization of convolutional neural networks, COMQ maintains near-lossless accuracy with a minimal drop of merely 0.3% in Top-1 accuracy.
FWin transformer for dengue prediction under climate and ocean influence
Mar 10, 2024Dengue fever is one of the most deadly mosquito-born tropical infectious diseases. Detailed long range forecast model is vital in controlling the spread of disease and making mitigation efforts. In this study, we examine methods used to forecast dengue cases for long range predictions. The dataset consists of local climate/weather in addition to global climate indicators of Singapore from 2000 to 2019. We utilize newly developed deep neural networks to learn the intricate relationship between the features. The baseline models in this study are in the class of recent transformers for long sequence forecasting tasks. We found that a Fourier mixed window attention (FWin) based transformer performed the best in terms of both the mean square error and the maximum absolute error on the long range dengue forecast up to 60 weeks.
Fourier-Mixed Window Attention: Accelerating Informer for Long Sequence Time-Series Forecasting
Jul 02, 2023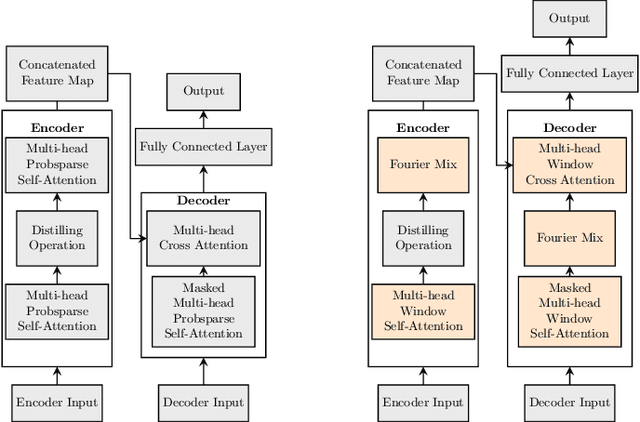

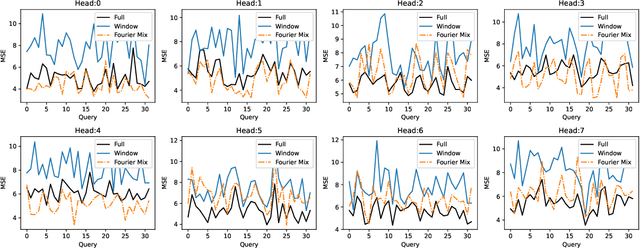

We study a fast local-global window-based attention method to accelerate Informer for long sequence time-series forecasting. While window attention is local and a considerable computational saving, it lacks the ability to capture global token information which is compensated by a subsequent Fourier transform block. Our method, named FWin, does not rely on query sparsity hypothesis and an empirical approximation underlying the ProbSparse attention of Informer. Through experiments on univariate and multivariate datasets, we show that FWin transformers improve the overall prediction accuracies of Informer while accelerating its inference speeds by 40 to 50 %. We also show in a nonlinear regression model that a learned FWin type attention approaches or even outperforms softmax full attention based on key vectors extracted from an Informer model's full attention layer acting on time series data.