 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite-Dimensional Operator/Block Kaczmarz Algorithms: Regret Bounds and $λ$-Effectiveness
Nov 10, 2025We present a variety of projection-based linear regression algorithms with a focus on modern machine-learning models and their algorithmic performance. We study the role of the relaxation parameter in generalized Kaczmarz algorithms and establish a priori regret bounds with explicit $λ$-dependence to quantify how much an algorithm's performance deviates from its optimal performance. A detailed analysis of relaxation parameter is also provided. Applications include: explicit regret bounds for the framework of Kaczmarz algorithm models, non-orthogonal Fourier expansions, and the use of regret estimates in modern machine learning models, including for noisy data, i.e., regret bounds for the noisy Kaczmarz algorithms. Motivated by machine-learning practice, our wider framework treats bounded operators (on infinite-dimensional Hilbert spaces), with updates realized as (block) Kaczmarz algorithms, leading to new and versatile results.
Beyond Discreteness: Finite-Sample Analysis of Straight-Through Estimator for Quantization
May 23, 2025Training quantized neural networks requires addressing the non-differentiable and discrete nature of the underlying optimization problem. To tackle this challenge, the straight-through estimator (STE) has become the most widely adopted heuristic, allowing backpropagation through discrete operations by introducing surrogate gradients. However, its theoretical properties remain largely unexplored, with few existing works simplifying the analysis by assuming an infinite amount of training data. In contrast, this work presents the first finite-sample analysis of STE in the context of neural network quantization. Our theoretical results highlight the critical role of sample size in the success of STE, a key insight absent from existing studies. Specifically, by analyzing the quantization-aware training of a two-layer neural network with binary weights and activations, we derive the sample complexity bound in terms of the data dimensionality that guarantees the convergence of STE-based optimization to the global minimum. Moreover, in the presence of label noises, we uncover an intriguing recurrence property of STE-gradient method, where the iterate repeatedly escape from and return to the optimal binary weights. Our analysis leverages tools from compressed sensing and dynamical systems theory.
Robust Fourier Neural Networks
Sep 03, 2024



Fourier embedding has shown great promise in removing spectral bias during neural network training. However, it can still suffer from high generalization errors, especially when the labels or measurements are noisy. We demonstrate that introducing a simple diagonal layer after the Fourier embedding layer makes the network more robust to measurement noise, effectively prompting it to learn sparse Fourier features. We provide theoretical justifications for this Fourier feature learning, leveraging recent developments in diagonal networks and implicit regularization in neural networks. Under certain conditions, our proposed approach can also learn functions that are noisy mixtures of nonlinear functions of Fourier features. Numerical experiments validate the effectiveness of our proposed architecture, supporting our theory.
Stochastic gradient descent for streaming linear and rectified linear systems with Massart noise
Mar 02, 2024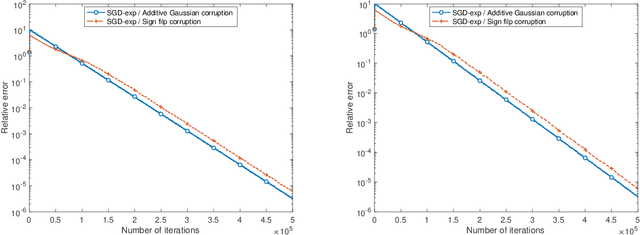
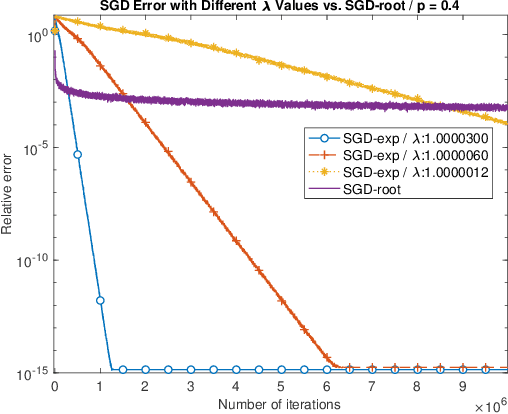
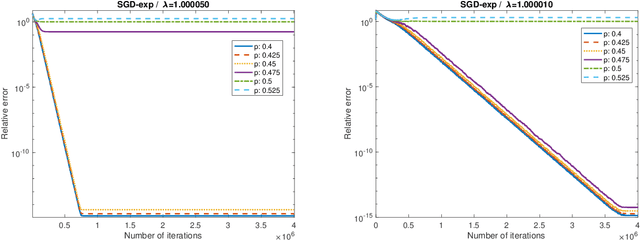
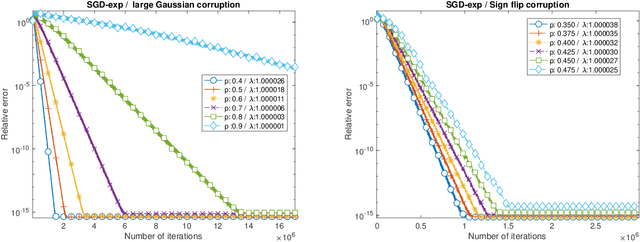
We propose SGD-exp, a stochastic gradient descent approach for linear and ReLU regressions under Massart noise (adversarial semi-random corruption model) for the fully streaming setting. We show novel nearly linear convergence guarantees of SGD-exp to the true parameter with up to $50\%$ Massart corruption rate, and with any corruption rate in the case of symmetric oblivious corruptions. This is the first convergence guarantee result for robust ReLU regression in the streaming setting, and it shows the improved convergence rate over previous robust methods for $L_1$ linear regression due to a choice of an exponentially decaying step size, known for its efficiency in practice. Our analysis is based on the drift analysis of a discrete stochastic process, which could also be interesting on its own.
Linear Convergence of Reshuffling Kaczmarz Methods With Sparse Constraints
Apr 20, 2023



The Kaczmarz method (KZ) and its variants, which are types of stochastic gradient descent (SGD) methods, have been extensively studied due to their simplicity and efficiency in solving linear equation systems. The iterative thresholding (IHT) method has gained popularity in various research fields, including compressed sensing or sparse linear regression, machine learning with additional structure, and optimization with nonconvex constraints. Recently, a hybrid method called Kaczmarz-based IHT (KZIHT) has been proposed, combining the benefits of both approaches, but its theoretical guarantees are missing. In this paper, we provide the first theoretical convergence guarantees for KZIHT by showing that it converges linearly to the solution of a system with sparsity constraints up to optimal statistical bias when the reshuffling data sampling scheme is used. We also propose the Kaczmarz with periodic thresholding (KZPT) method, which generalizes KZIHT by applying the thresholding operation for every certain number of KZ iterations and by employing two different types of step sizes. We establish a linear convergence guarantee for KZPT for randomly subsampled bounded orthonormal systems (BOS) and mean-zero isotropic sub-Gaussian random matrices, which are most commonly used models in compressed sensing, dimension reduction, matrix sketching, and many inverse problems in neural networks. Our analysis shows that KZPT with an optimal thresholding period outperforms KZIHT. To support our theory, we include several numerical experiments.
Federated Gradient Matching Pursuit
Feb 20, 2023



Traditional machine learning techniques require centralizing all training data on one server or data hub. Due to the development of communication technologies and a huge amount of decentralized data on many clients, collaborative machine learning has become the main interest while providing privacy-preserving frameworks. In particular, federated learning (FL) provides such a solution to learn a shared model while keeping training data at local clients. On the other hand, in a wide range of machine learning and signal processing applications, the desired solution naturally has a certain structure that can be framed as sparsity with respect to a certain dictionary. This problem can be formulated as an optimization problem with sparsity constraints and solving it efficiently has been one of the primary research topics in the traditional centralized setting. In this paper, we propose a novel algorithmic framework, federated gradient matching pursuit (FedGradMP), to solve the sparsity constrained minimization problem in the FL setting. We also generalize our algorithms to accommodate various practical FL scenarios when only a subset of clients participate per round, when the local model estimation at clients could be inexact, or when the model parameters are sparse with respect to general dictionaries. Our theoretical analysis shows the linear convergence of the proposed algorithms. A variety of numerical experiments are conducted to demonstrate the great potential of the proposed framework -- fast convergence both in communication rounds and computation time for many important scenarios without sophisticated parameter tuning.
Sub-Gaussian Matrices on Sets: Optimal Tail Dependence and Applications
Jan 28, 2020Random linear mappings are widely used in modern signal processing, compressed sensing and machine learning. These mappings may be used to embed the data into a significantly lower dimension while at the same time preserving useful information. This is done by approximately preserving the distances between data points, which are assumed to belong to $\mathbb{R}^n$. Thus, the performance of these mappings is usually captured by how close they are to an isometry on the data. Random Gaussian linear mappings have been the object of much study, while the sub-Gaussian settings is not yet fully understood. In the latter case, the performance depends on the sub-Gaussian norm of the rows. In many applications, e.g., compressed sensing, this norm may be large, or even growing with dimension, and thus it is important to characterize this dependence. We study when a sub-Gaussian matrix can become a near isometry on a set, show that previous best known dependence on the sub-Gaussian norm was sub-optimal, and present the optimal dependence. Our result not only answers a remaining question posed by Liaw, Mehrabian, Plan and Vershynin in 2017, but also generalizes their work. We also develop a new Bernstein type inequality for sub-exponential random variables, and a new Hanson-Wright inequality for quadratic forms of sub-Gaussian random variables, in both cases improving the bounds in the sub-Gaussian regime under moment constraints. Finally, we illustrate popular applications such as Johnson-Lindenstrauss embeddings, randomized sketches and blind demodulation, whose theoretical guarantees can be improved by our results in the sub-Gaussian case.