 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLoQ: Enhancing Fine-Tuning of Quantized LLMs via Calibrated LoRA Initialization
Jan 30, 2025



Fine-tuning large language models (LLMs) using low-rank adaptation (LoRA) has become a highly efficient approach for downstream tasks, particularly in scenarios with limited computational resources. However, applying LoRA techniques to quantized LLMs poses unique challenges due to the reduced representational precision of quantized weights. In this paper, we introduce CLoQ (Calibrated LoRA initialization for Quantized LLMs), a simplistic initialization strategy designed to overcome these challenges. Our approach focuses on minimizing the layer-wise discrepancy between the original LLM and its quantized counterpart with LoRA components during initialization. By leveraging a small calibration dataset, CLoQ quantizes a pre-trained LLM and determines the optimal LoRA components for each layer, ensuring a strong foundation for subsequent fine-tuning. A key contribution of this work is a novel theoretical result that enables the accurate and closed-form construction of these optimal LoRA components. We validate the efficacy of CLoQ across multiple tasks such as language generation, arithmetic reasoning, and commonsense reasoning, demonstrating that it consistently outperforms existing LoRA fine-tuning methods for quantized LLMs, especially at ultra low-bit widths.
MagR: Weight Magnitude Reduction for Enhancing Post-Training Quantization
Jun 02, 2024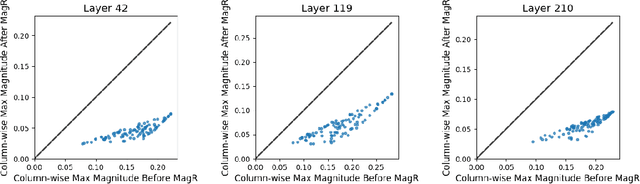
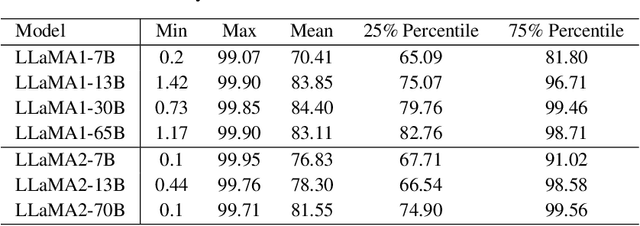
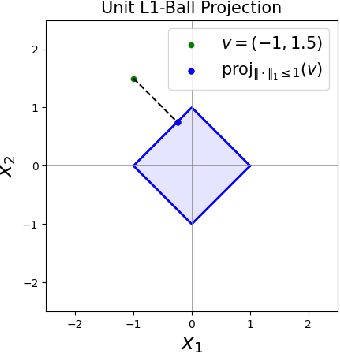
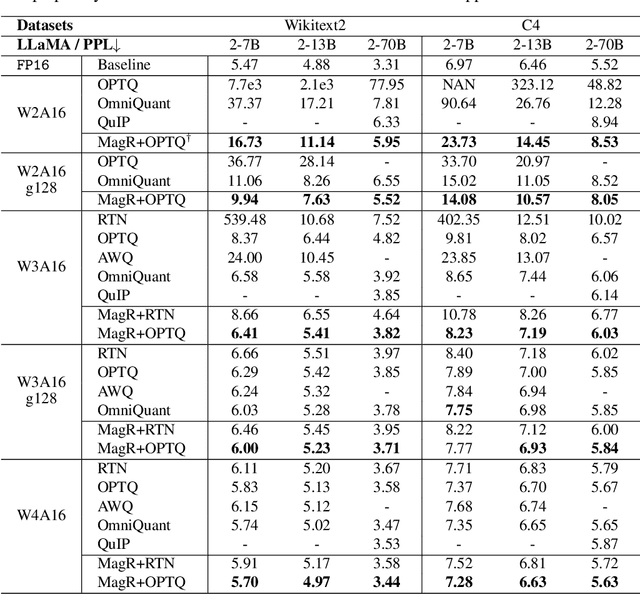
In this paper, we present a simple optimization-based preprocessing technique called Weight Magnitude Reduction (MagR) to improve the performance of post-training quantization. For each linear layer, we adjust the pre-trained floating-point weights by solving an $\ell_\infty$-regularized optimization problem. This process greatly diminishes the maximum magnitude of the weights and smooths out outliers, while preserving the layer's output. The preprocessed weights are centered more towards zero, which facilitates the subsequent quantization process. To implement MagR, we address the $\ell_\infty$-regularization by employing an efficient proximal gradient descent algorithm. Unlike existing preprocessing methods that involve linear transformations and subsequent post-processing steps, which can introduce significant overhead at inference time, MagR functions as a non-linear transformation, eliminating the need for any additional post-processing. This ensures that MagR introduces no overhead whatsoever during inference. Our experiments demonstrate that MagR achieves state-of-the-art performance on the Llama family of models. For example, we achieve a Wikitext2 perplexity of 5.95 on the LLaMA2-70B model for per-channel INT2 weight quantization without incurring any inference overhead.
COMQ: A Backpropagation-Free Algorithm for Post-Training Quantization
Mar 11, 2024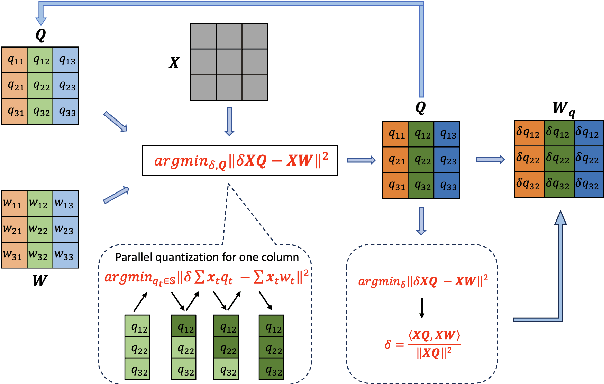
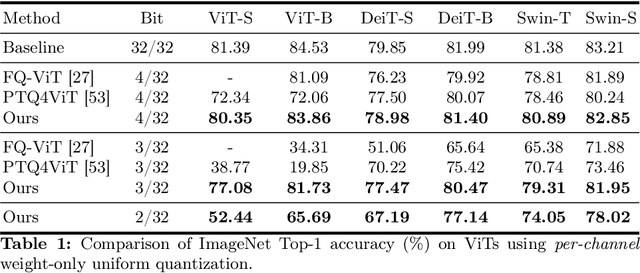
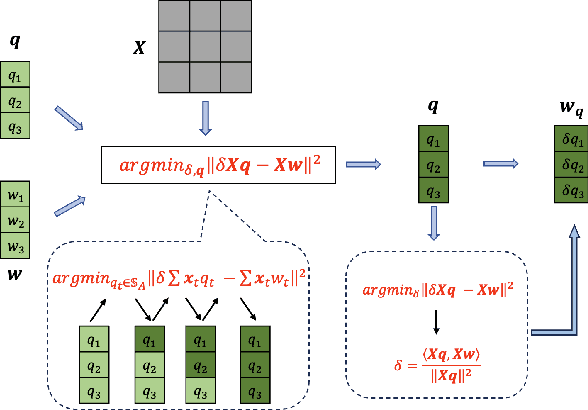
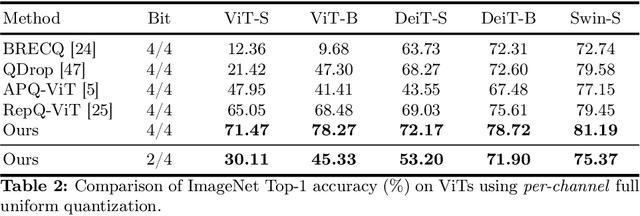
Post-training quantization (PTQ) has emerged as a practical approach to compress large neural networks, making them highly efficient for deployment. However, effectively reducing these models to their low-bit counterparts without compromising the original accuracy remains a key challenge. In this paper, we propose an innovative PTQ algorithm termed COMQ, which sequentially conducts coordinate-wise minimization of the layer-wise reconstruction errors. We consider the widely used integer quantization, where every quantized weight can be decomposed into a shared floating-point scalar and an integer bit-code. Within a fixed layer, COMQ treats all the scaling factor(s) and bit-codes as the variables of the reconstruction error. Every iteration improves this error along a single coordinate while keeping all other variables constant. COMQ is easy to use and requires no hyper-parameter tuning. It instead involves only dot products and rounding operations. We update these variables in a carefully designed greedy order, significantly enhancing the accuracy. COMQ achieves remarkable results in quantizing 4-bit Vision Transformers, with a negligible loss of less than 1% in Top-1 accuracy. In 4-bit INT quantization of convolutional neural networks, COMQ maintains near-lossless accuracy with a minimal drop of merely 0.3% in Top-1 accuracy.
Deformation Robust Text Spotting with Geometric Prior
Aug 31, 2023



The goal of text spotting is to perform text detection and recognition in an end-to-end manner. Although the diversity of luminosity and orientation in scene texts has been widely studied, the font diversity and shape variance of the same character are ignored in recent works, since most characters in natural images are rendered in standard fonts. To solve this problem, we present a Chinese Artistic Dataset, termed as ARText, which contains 33,000 artistic images with rich shape deformation and font diversity. Based on this database, we develop a deformation robust text spotting method (DR TextSpotter) to solve the recognition problem of complex deformation of characters in different fonts. Specifically, we propose a geometric prior module to highlight the important features based on the unsupervised landmark detection sub-network. A graph convolution network is further constructed to fuse the character features and landmark features, and then performs semantic reasoning to enhance the discrimination for different characters. The experiments are conducted on ARText and IC19-ReCTS datasets. Our results demonstrate the effectiveness of our proposed method.
GenText: Unsupervised Artistic Text Generation via Decoupled Font and Texture Manipulation
Jul 20, 2022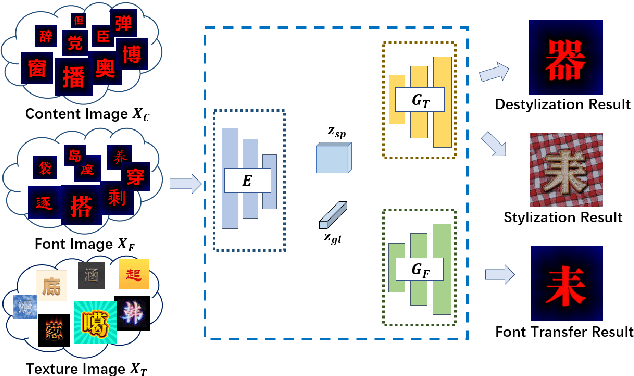
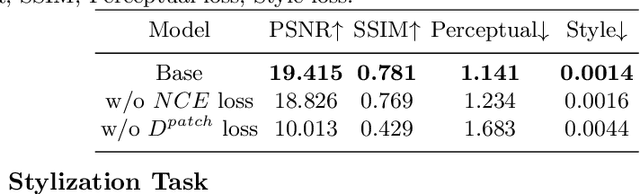
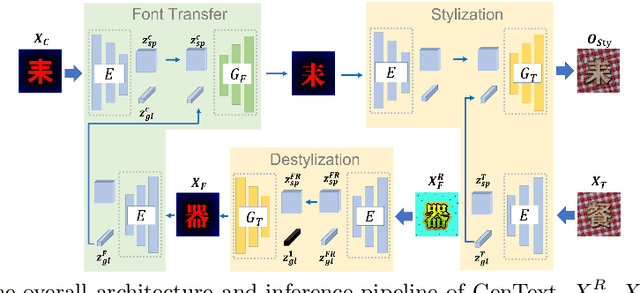
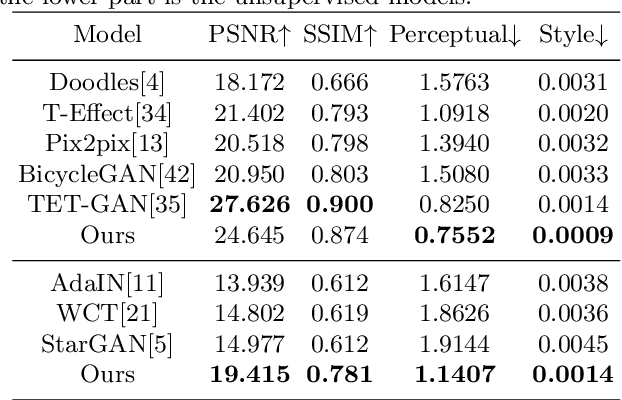
Automatic artistic text generation is an emerging topic which receives increasing attention due to its wide applications. The artistic text can be divided into three components, content, font, and texture, respectively. Existing artistic text generation models usually focus on manipulating one aspect of the above components, which is a sub-optimal solution for controllable general artistic text generation. To remedy this issue, we propose a novel approach, namely GenText, to achieve general artistic text style transfer by separably migrating the font and texture styles from the different source images to the target images in an unsupervised manner. Specifically, our current work incorporates three different stages, stylization, destylization, and font transfer, respectively, into a unified platform with a single powerful encoder network and two separate style generator networks, one for font transfer, the other for stylization and destylization. The destylization stage first extracts the font style of the font reference image, then the font transfer stage generates the target content with the desired font style. Finally, the stylization stage renders the resulted font image with respect to the texture style in the reference image. Moreover, considering the difficult data acquisition of paired artistic text images, our model is designed under the unsupervised setting, where all stages can be effectively optimized from unpaired data. Qualitative and quantitative results are performed on artistic text benchmarks, which demonstrate the superior performance of our proposed model. The code with models will become publicly available in the future.