 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Group-wise Post-Training Quantization for Medical Foundation Model
Apr 09, 2026Foundation models have achieved remarkable results in medical image analysis. However, its large network architecture and high computational complexity significantly impact inference speed, limiting its application on terminal medical devices. Quantization, a technique that compresses models into low-bit versions, is a solution to this challenge. In this paper, we propose a post-training quantization algorithm, Permutation-COMQ. It eliminates the need for backpropagation by using simple dot products and rounding operations, thereby removing hyperparameter tuning and simplifying the process. Additionally, we introduce a weight-aware strategy that reorders the weight within each layer to address the accuracy degradation induced by channel-wise scaling during quantization, while preserving channel structure. Experiments demonstrate that our method achieves the best results in 2-bit, 4-bit, and 8-bit quantization.
Beyond Discreteness: Finite-Sample Analysis of Straight-Through Estimator for Quantization
May 23, 2025Training quantized neural networks requires addressing the non-differentiable and discrete nature of the underlying optimization problem. To tackle this challenge, the straight-through estimator (STE) has become the most widely adopted heuristic, allowing backpropagation through discrete operations by introducing surrogate gradients. However, its theoretical properties remain largely unexplored, with few existing works simplifying the analysis by assuming an infinite amount of training data. In contrast, this work presents the first finite-sample analysis of STE in the context of neural network quantization. Our theoretical results highlight the critical role of sample size in the success of STE, a key insight absent from existing studies. Specifically, by analyzing the quantization-aware training of a two-layer neural network with binary weights and activations, we derive the sample complexity bound in terms of the data dimensionality that guarantees the convergence of STE-based optimization to the global minimum. Moreover, in the presence of label noises, we uncover an intriguing recurrence property of STE-gradient method, where the iterate repeatedly escape from and return to the optimal binary weights. Our analysis leverages tools from compressed sensing and dynamical systems theory.
CLoQ: Enhancing Fine-Tuning of Quantized LLMs via Calibrated LoRA Initialization
Jan 30, 2025



Fine-tuning large language models (LLMs) using low-rank adaptation (LoRA) has become a highly efficient approach for downstream tasks, particularly in scenarios with limited computational resources. However, applying LoRA techniques to quantized LLMs poses unique challenges due to the reduced representational precision of quantized weights. In this paper, we introduce CLoQ (Calibrated LoRA initialization for Quantized LLMs), a simplistic initialization strategy designed to overcome these challenges. Our approach focuses on minimizing the layer-wise discrepancy between the original LLM and its quantized counterpart with LoRA components during initialization. By leveraging a small calibration dataset, CLoQ quantizes a pre-trained LLM and determines the optimal LoRA components for each layer, ensuring a strong foundation for subsequent fine-tuning. A key contribution of this work is a novel theoretical result that enables the accurate and closed-form construction of these optimal LoRA components. We validate the efficacy of CLoQ across multiple tasks such as language generation, arithmetic reasoning, and commonsense reasoning, demonstrating that it consistently outperforms existing LoRA fine-tuning methods for quantized LLMs, especially at ultra low-bit widths.
MagR: Weight Magnitude Reduction for Enhancing Post-Training Quantization
Jun 02, 2024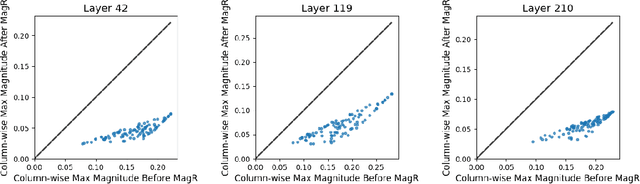
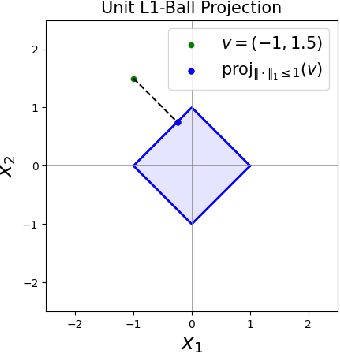
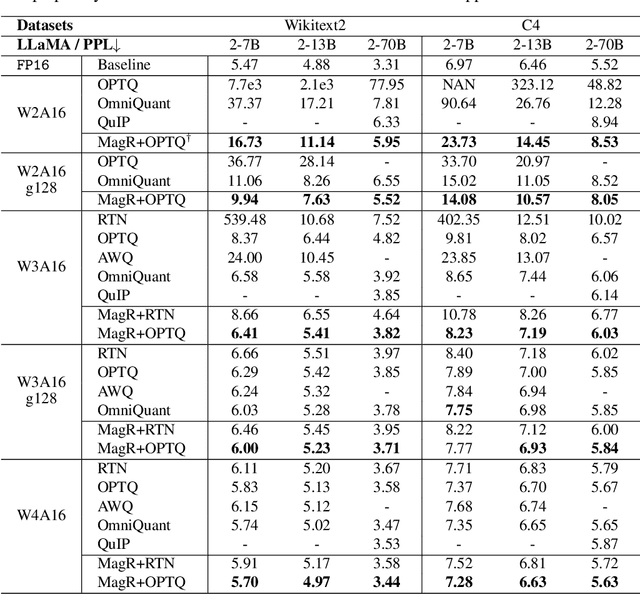
In this paper, we present a simple optimization-based preprocessing technique called Weight Magnitude Reduction (MagR) to improve the performance of post-training quantization. For each linear layer, we adjust the pre-trained floating-point weights by solving an $\ell_\infty$-regularized optimization problem. This process greatly diminishes the maximum magnitude of the weights and smooths out outliers, while preserving the layer's output. The preprocessed weights are centered more towards zero, which facilitates the subsequent quantization process. To implement MagR, we address the $\ell_\infty$-regularization by employing an efficient proximal gradient descent algorithm. Unlike existing preprocessing methods that involve linear transformations and subsequent post-processing steps, which can introduce significant overhead at inference time, MagR functions as a non-linear transformation, eliminating the need for any additional post-processing. This ensures that MagR introduces no overhead whatsoever during inference. Our experiments demonstrate that MagR achieves state-of-the-art performance on the Llama family of models. For example, we achieve a Wikitext2 perplexity of 5.95 on the LLaMA2-70B model for per-channel INT2 weight quantization without incurring any inference overhead.
COMQ: A Backpropagation-Free Algorithm for Post-Training Quantization
Mar 11, 2024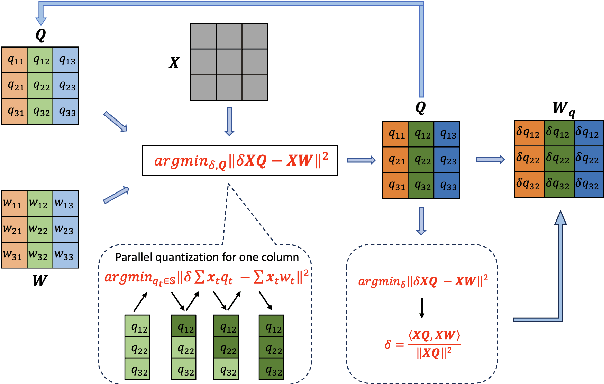
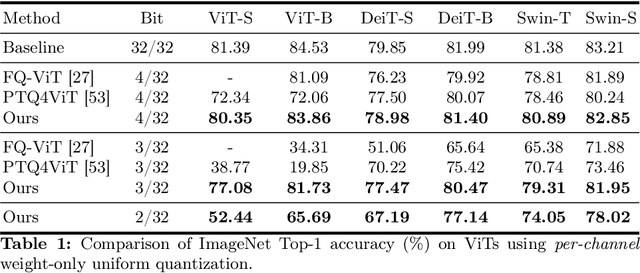
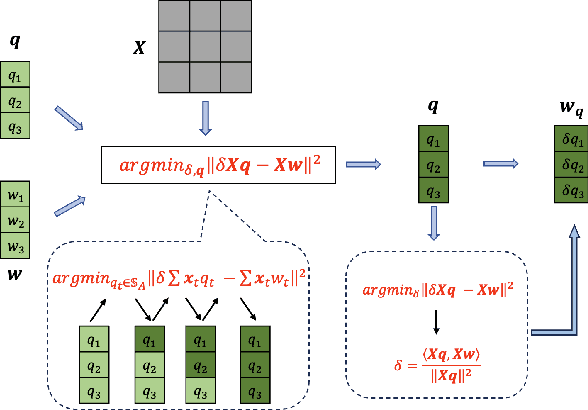
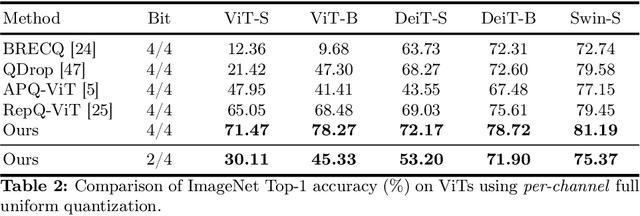
Post-training quantization (PTQ) has emerged as a practical approach to compress large neural networks, making them highly efficient for deployment. However, effectively reducing these models to their low-bit counterparts without compromising the original accuracy remains a key challenge. In this paper, we propose an innovative PTQ algorithm termed COMQ, which sequentially conducts coordinate-wise minimization of the layer-wise reconstruction errors. We consider the widely used integer quantization, where every quantized weight can be decomposed into a shared floating-point scalar and an integer bit-code. Within a fixed layer, COMQ treats all the scaling factor(s) and bit-codes as the variables of the reconstruction error. Every iteration improves this error along a single coordinate while keeping all other variables constant. COMQ is easy to use and requires no hyper-parameter tuning. It instead involves only dot products and rounding operations. We update these variables in a carefully designed greedy order, significantly enhancing the accuracy. COMQ achieves remarkable results in quantizing 4-bit Vision Transformers, with a negligible loss of less than 1% in Top-1 accuracy. In 4-bit INT quantization of convolutional neural networks, COMQ maintains near-lossless accuracy with a minimal drop of merely 0.3% in Top-1 accuracy.
Feature Affinity Assisted Knowledge Distillation and Quantization of Deep Neural Networks on Label-Free Data
Feb 10, 2023



In this paper, we propose a feature affinity (FA) assisted knowledge distillation (KD) method to improve quantization-aware training of deep neural networks (DNN). The FA loss on intermediate feature maps of DNNs plays the role of teaching middle steps of a solution to a student instead of only giving final answers in the conventional KD where the loss acts on the network logits at the output level. Combining logit loss and FA loss, we found that the quantized student network receives stronger supervision than from the labeled ground-truth data. The resulting FAQD is capable of compressing model on label-free data, which brings immediate practical benefits as pre-trained teacher models are readily available and unlabeled data are abundant. In contrast, data labeling is often laborious and expensive. Finally, we propose a fast feature affinity (FFA) loss that accurately approximates FA loss with a lower order of computational complexity, which helps speed up training for high resolution image input.
Recurrence of Optimum for Training Weight and Activation Quantized Networks
Dec 10, 2020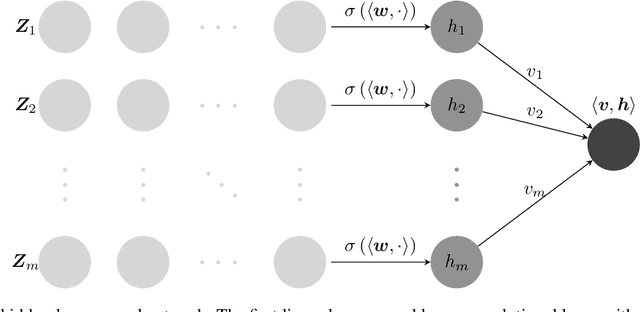



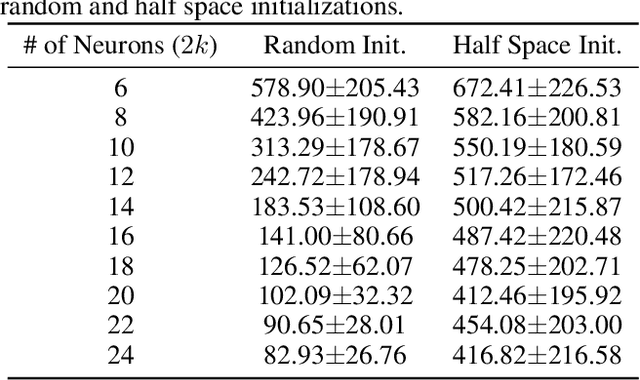
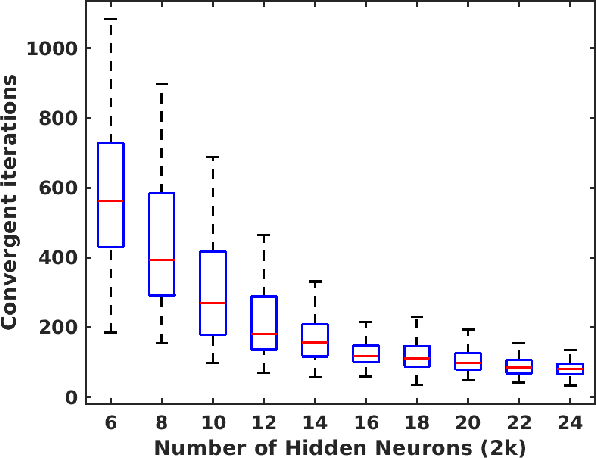
Deep neural networks (DNNs) are quantized for efficient inference on resource-constrained platforms. However, training deep learning models with low-precision weights and activations involves a demanding optimization task, which calls for minimizing a stage-wise loss function subject to a discrete set-constraint. While numerous training methods have been proposed, existing studies for full quantization of DNNs are mostly empirical. From a theoretical point of view, we study practical techniques for overcoming the combinatorial nature of network quantization. Specifically, we investigate a simple yet powerful projected gradient-like algorithm for quantizing two-linear-layer networks, which proceeds by repeatedly moving one step at float weights in the negation of a heuristic \emph{fake} gradient of the loss function (so-called coarse gradient) evaluated at quantized weights. For the first time, we prove that under mild conditions, the sequence of quantized weights recurrently visits the global optimum of the discrete minimization problem for training fully quantized network. We also show numerical evidence of the recurrence phenomenon of weight evolution in training quantized deep networks.
Learning Quantized Neural Nets by Coarse Gradient Method for Non-linear Classification
Nov 23, 2020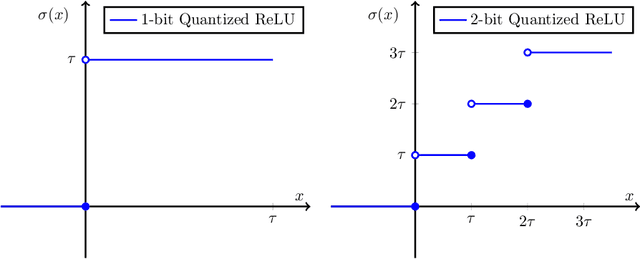

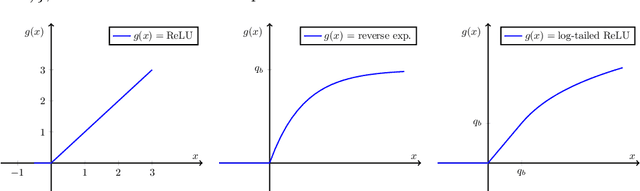
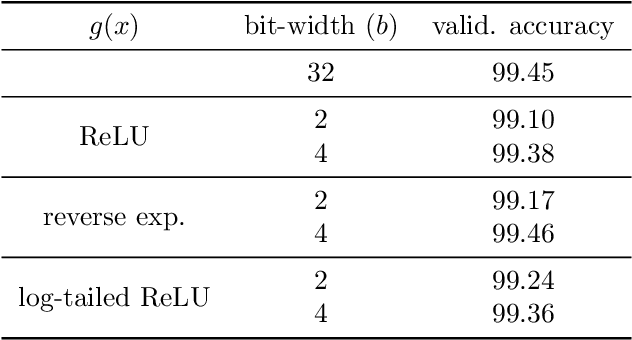
Quantized or low-bit neural networks are attractive due to their inference efficiency. However, training deep neural networks with quantized activations involves minimizing a discontinuous and piecewise constant loss function. Such a loss function has zero gradients almost everywhere (a.e.), which makes the conventional gradient-based algorithms inapplicable. To this end, we study a novel class of \emph{biased} first-order oracle, termed coarse gradient, for overcoming the vanished gradient issue. A coarse gradient is generated by replacing the a.e. zero derivatives of quantized (i.e., stair-case) ReLU activation composited in the chain rule with some heuristic proxy derivative called straight-through estimator (STE). Although having been widely used in training quantized networks empirically, fundamental questions like when and why the ad-hoc STE trick works, still lacks theoretical understanding. In this paper, we propose a class of STEs with certain monotonicity, and consider their applications to the training of a two-linear-layer network with quantized activation functions for non-linear multi-category classification. We establish performance guarantees for the proposed STEs by showing that the corresponding coarse gradient methods converge to the global minimum, which leads to a perfect classification. Lastly, we present experimental results on synthetic data as well as MNIST dataset to verify our theoretical findings and demonstrate the effectiveness of our proposed STEs.
Global Convergence and Geometric Characterization of Slow to Fast Weight Evolution in Neural Network Training for Classifying Linearly Non-Separable Data
Mar 05, 2020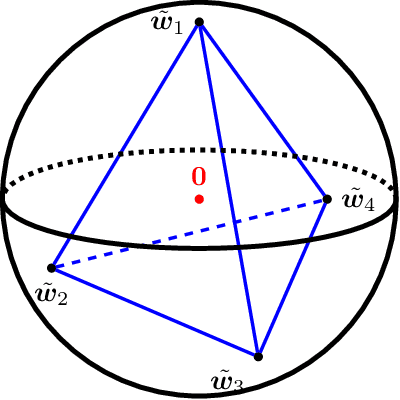

In this paper, we study the dynamics of gradient descent in learning neural networks for classification problems. Unlike in existing works, we consider the linearly non-separable case where the training data of different classes lie in orthogonal subspaces. We show that when the network has sufficient (but not exceedingly large) number of neurons, (1) the corresponding minimization problem has a desirable landscape where all critical points are global minima with perfect classification; (2) gradient descent is guaranteed to converge to the global minima in this case. Moreover, we discovered a geometric condition on the network weights so that when it is satisfied, the weight evolution transitions from a slow phase of weight direction spreading to a fast phase of weight convergence. The geometric condition says that the convex hull of the weights projected on the unit sphere contains the origin.
Understanding Straight-Through Estimator in Training Activation Quantized Neural Nets
Mar 13, 2019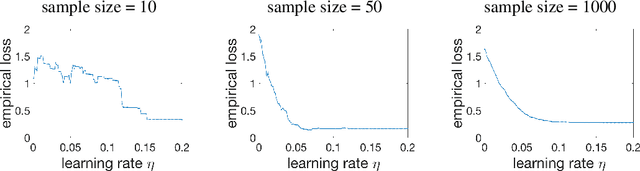

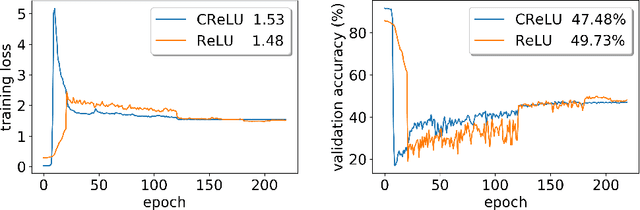

Training activation quantized neural networks involves minimizing a piecewise constant function whose gradient vanishes almost everywhere, which is undesirable for the standard back-propagation or chain rule. An empirical way around this issue is to use a straight-through estimator (STE) (Bengio et al., 2013) in the backward pass, so that the "gradient" through the modified chain rule becomes non-trivial. Since this unusual "gradient" is certainly not the gradient of loss function, the following question arises: why searching in its negative direction minimizes the training loss? In this paper, we provide the theoretical justification of the concept of STE by answering this question. We consider the problem of learning a two-linear-layer network with binarized ReLU activation and Gaussian input data. We shall refer to the unusual "gradient" given by the STE-modifed chain rule as coarse gradient. The choice of STE is not unique. We prove that if the STE is properly chosen, the expected coarse gradient correlates positively with the population gradient (not available for the training), and its negation is a descent direction for minimizing the population loss. We further show the associated coarse gradient descent algorithm converges to a critical point of the population loss minimization problem. Moreover, we show that a poor choice of STE leads to instability of the training algorithm near certain local minima, which is verified with CIFAR-10 experiments.