 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Convergence and Geometric Characterization of Slow to Fast Weight Evolution in Neural Network Training for Classifying Linearly Non-Separable Data
Paper and Code
Mar 05, 2020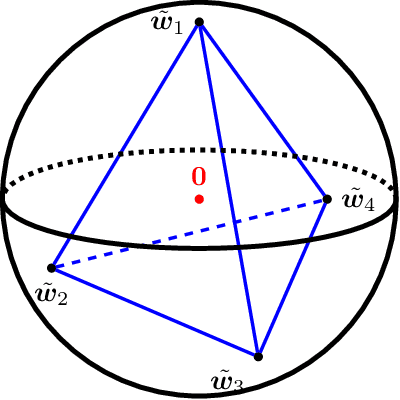
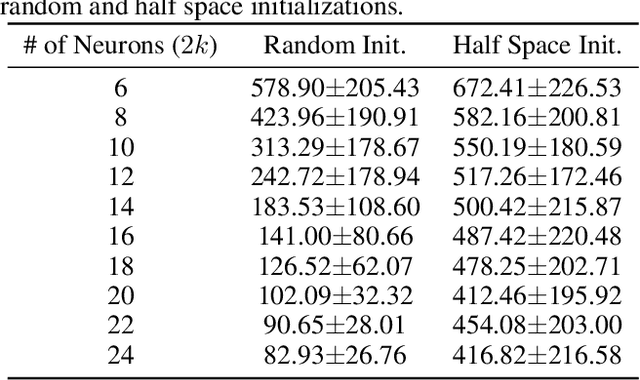
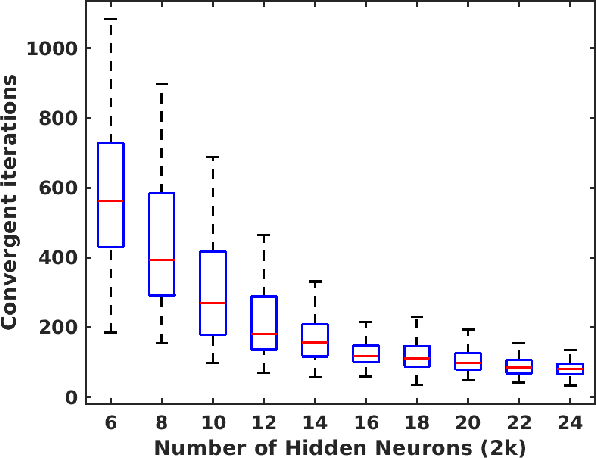

In this paper, we study the dynamics of gradient descent in learning neural networks for classification problems. Unlike in existing works, we consider the linearly non-separable case where the training data of different classes lie in orthogonal subspaces. We show that when the network has sufficient (but not exceedingly large) number of neurons, (1) the corresponding minimization problem has a desirable landscape where all critical points are global minima with perfect classification; (2) gradient descent is guaranteed to converge to the global minima in this case. Moreover, we discovered a geometric condition on the network weights so that when it is satisfied, the weight evolution transitions from a slow phase of weight direction spreading to a fast phase of weight convergence. The geometric condition says that the convex hull of the weights projected on the unit sphere contains the origin.