 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-SAM: Boosting Sharpness-Aware Minimization with Dominant-Eigenvector Gradient Correction
Jan 15, 2026Sharpness-Aware Minimization (SAM) aims to improve generalization by minimizing a worst-case perturbed loss over a small neighborhood of model parameters. However, during training, its optimization behavior does not always align with theoretical expectations, since both sharp and flat regions may yield a small perturbed loss. In such cases, the gradient may still point toward sharp regions, failing to achieve the intended effect of SAM. To address this issue, we investigate SAM from a spectral and geometric perspective: specifically, we utilize the angle between the gradient and the leading eigenvector of the Hessian as a measure of sharpness. Our analysis illustrates that when this angle is less than or equal to ninety degrees, the effect of SAM's sharpness regularization can be weakened. Furthermore, we propose an explicit eigenvector-aligned SAM (X-SAM), which corrects the gradient via orthogonal decomposition along the top eigenvector, enabling more direct and efficient regularization of the Hessian's maximum eigenvalue. We prove X-SAM's convergence and superior generalization, with extensive experimental evaluations confirming both theoretical and practical advantages.
PipeOptim: Ensuring Effective 1F1B Schedule with Optimizer-Dependent Weight Prediction
Dec 05, 2023Asynchronous pipeline model parallelism with a "1F1B" (one forward, one backward) schedule generates little bubble overhead and always provides quite a high throughput. However, the "1F1B" schedule inevitably leads to weight inconsistency and weight staleness issues due to the cross-training of different mini-batches across GPUs. To simultaneously address these two problems, in this paper, we propose an optimizer-dependent weight prediction strategy (a.k.a PipeOptim) for asynchronous pipeline training. The key insight of our proposal is that we employ a weight prediction strategy in the forward pass to ensure that each mini-batch uses consistent and staleness-free weights to compute the forward pass. To be concrete, we first construct the weight prediction scheme based on the update rule of the used optimizer when training the deep neural network models. Then throughout the "1F1B" pipelined training, each mini-batch is mandated to execute weight prediction ahead of the forward pass, subsequently employing the predicted weights to perform the forward pass. As a result, PipeOptim 1) inherits the advantage of the "1F1B" schedule and generates pretty high throughput, and 2) can ensure effective parameter learning regardless of the type of the used optimizer. To verify the effectiveness of our proposal, we conducted extensive experimental evaluations using eight different deep-learning models spanning three machine-learning tasks including image classification, sentiment analysis, and machine translation. The experiment results demonstrate that PipeOptim outperforms the popular pipelined approaches including GPipe, PipeDream, PipeDream-2BW, and SpecTrain. The code of PipeOptim can be accessible at https://github.com/guanleics/PipeOptim.
AdaPlus: Integrating Nesterov Momentum and Precise Stepsize Adjustment on AdamW Basis
Sep 05, 2023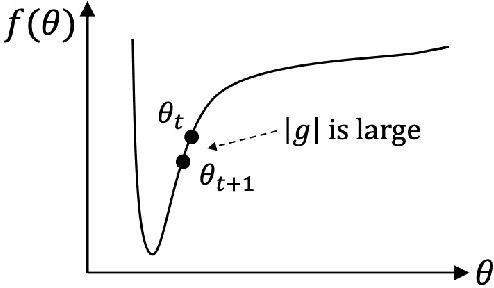

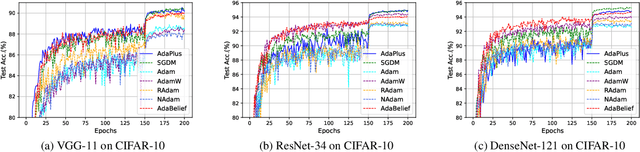

This paper proposes an efficient optimizer called AdaPlus which integrates Nesterov momentum and precise stepsize adjustment on AdamW basis. AdaPlus combines the advantages of AdamW, Nadam, and AdaBelief and, in particular, does not introduce any extra hyper-parameters. We perform extensive experimental evaluations on three machine learning tasks to validate the effectiveness of AdaPlus. The experiment results validate that AdaPlus (i) is the best adaptive method which performs most comparable with (even slightly better than) SGD with momentum on image classification tasks and (ii) outperforms other state-of-the-art optimizers on language modeling tasks and illustrates the highest stability when training GANs. The experiment code of AdaPlus is available at: https://github.com/guanleics/AdaPlus.
XGrad: Boosting Gradient-Based Optimizers With Weight Prediction
May 26, 2023



In this paper, we propose a general deep learning training framework XGrad which introduces weight prediction into the popular gradient-based optimizers to boost their convergence and generalization when training the deep neural network (DNN) models. In particular, ahead of each mini-batch training, the future weights are predicted according to the update rule of the used optimizer and are then applied to both the forward pass and backward propagation. In this way, during the whole training period, the optimizer always utilizes the gradients w.r.t. the future weights to update the DNN parameters, making the gradient-based optimizer achieve better convergence and generalization compared to the original optimizer without weight prediction. XGrad is rather straightforward to implement yet pretty effective in boosting the convergence of gradient-based optimizers and the accuracy of DNN models. Empirical results concerning the most three popular gradient-based optimizers including SGD with momentum, Adam, and AdamW demonstrate the effectiveness of our proposal. The experimental results validate that XGrad can attain higher model accuracy than the original optimizers when training the DNN models. The code of XGrad will be available at: https://github.com/guanleics/XGrad.
Weight Prediction Boosts the Convergence of AdamW
Feb 01, 2023In this paper, we introduce weight prediction into the AdamW optimizer to boost its convergence when training the deep neural network (DNN) models. In particular, ahead of each mini-batch training, we predict the future weights according to the update rule of AdamW and then apply the predicted future weights to do both forward pass and backward propagation. In this way, the AdamW optimizer always utilizes the gradients w.r.t. the future weights instead of current weights to update the DNN parameters, making the AdamW optimizer achieve better convergence. Our proposal is simple and straightforward to implement but effective in boosting the convergence of DNN training. We performed extensive experimental evaluations on image classification and language modeling tasks to verify the effectiveness of our proposal. The experimental results validate that our proposal can boost the convergence of AdamW and achieve better accuracy than AdamW when training the DNN models.
XPipe: Efficient Pipeline Model Parallelism for Multi-GPU DNN Training
Nov 20, 2019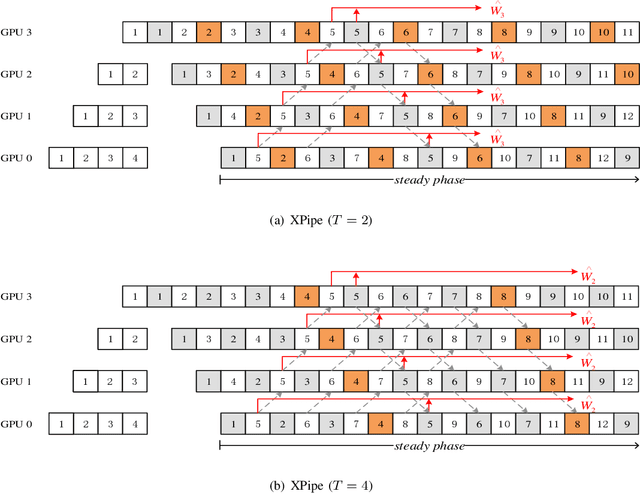
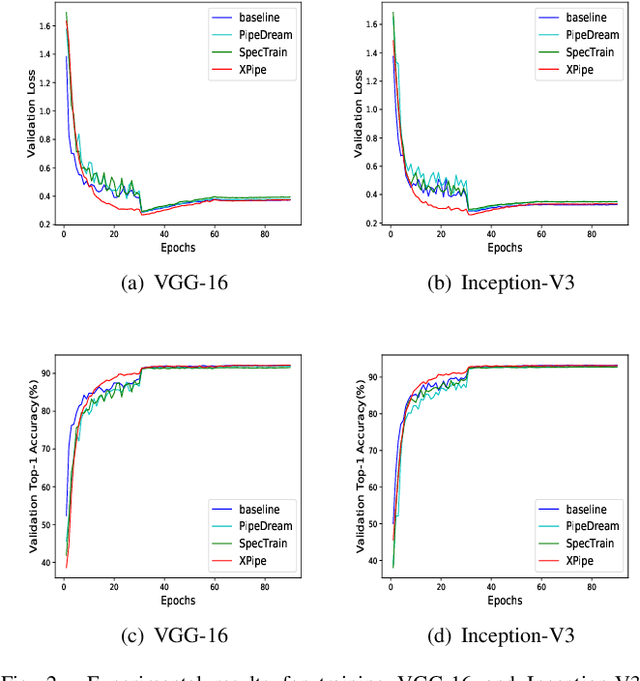
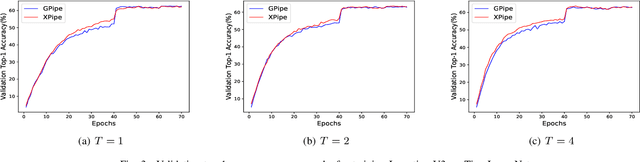
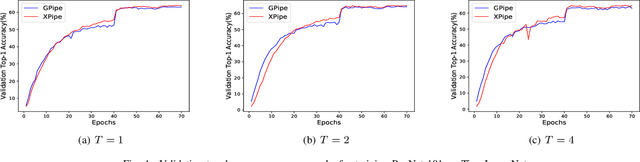
We propose XPipe, an efficient asynchronous pipeline model parallelism approach for multi-GPU DNN training. XPipe is designed to make use of multiple GPUs to concurrently and continuously train different parts of a DNN model. To improve GPU utilization and achieve high throughput, it splits a mini-batch into a set of micro-batches and allows the overlapping of the pipelines of multiple micro-batches, including those belonging to different mini-batches. Most importantly, the novel weight prediction strategy adopted by XPipe enables it to effectively address the weight inconsistency and staleness issues incurred by the asynchronous pipeline parallelism. As a result, XPipe incorporates the advantages of both synchronous and asynchronous pipeline model parallelism approaches. Concretely, it can achieve very comparable (even slightly better) model accuracy as its synchronous counterpart, while obtaining higher throughput than it. Experimental results show that XPipe outperforms other state-of-the-art synchronous and asynchronous model parallelism approaches.
Non-ergodic Convergence Analysis of Heavy-Ball Algorithms
Nov 09, 2018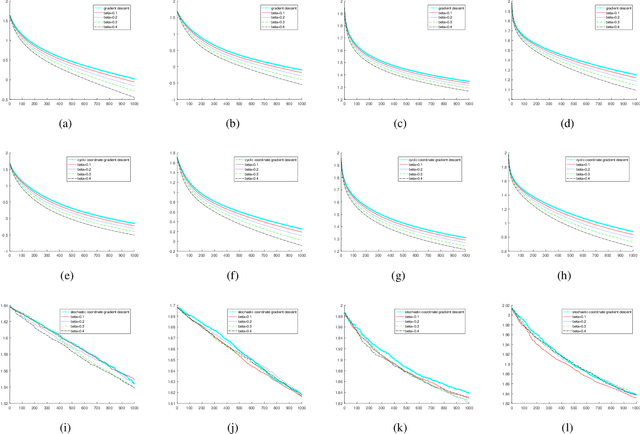
In this paper, we revisit the convergence of the Heavy-ball method, and present improved convergence complexity results in the convex setting. We provide the first non-ergodic O(1/k) rate result of the Heavy-ball algorithm with constant step size for coercive objective functions. For objective functions satisfying a relaxed strongly convex condition, the linear convergence is established under weaker assumptions on the step size and inertial parameter than made in the existing literature. We extend our results to multi-block version of the algorithm with both the cyclic and stochastic update rules. In addition, our results can also be extended to decentralized optimization, where the ergodic analysis is not applicable.
An Efficient ADMM-Based Algorithm to Nonconvex Penalized Support Vector Machines
Sep 11, 2018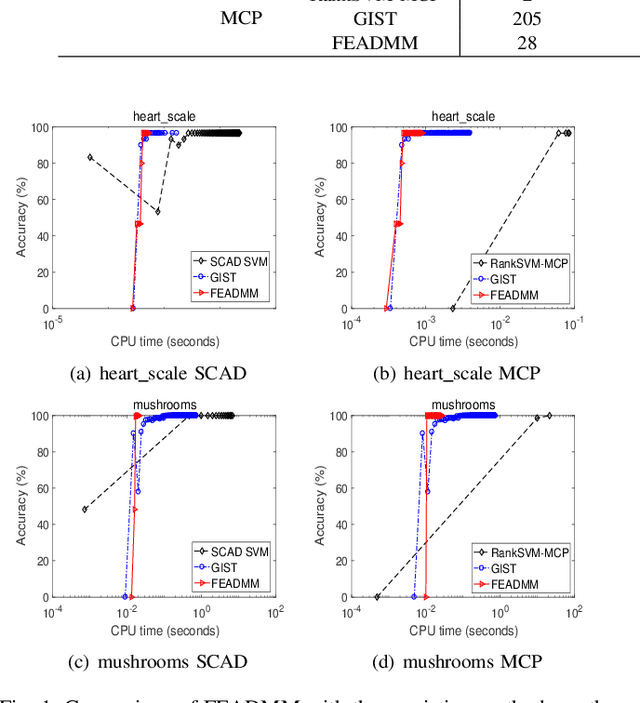
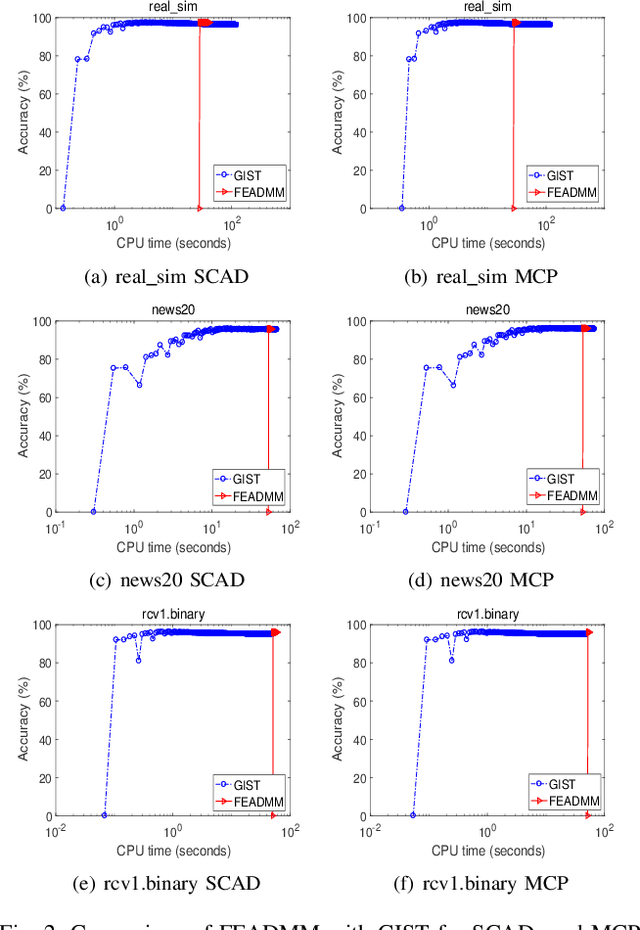
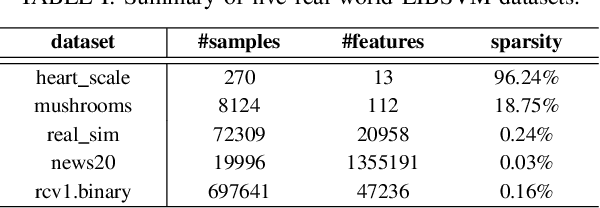
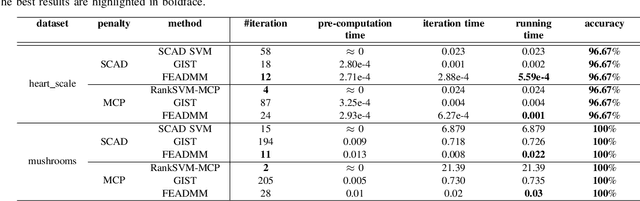
Support vector machines (SVMs) with sparsity-inducing nonconvex penalties have received considerable attentions for the characteristics of automatic classification and variable selection. However, it is quite challenging to solve the nonconvex penalized SVMs due to their nondifferentiability, nonsmoothness and nonconvexity. In this paper, we propose an efficient ADMM-based algorithm to the nonconvex penalized SVMs. The proposed algorithm covers a large class of commonly used nonconvex regularization terms including the smooth clipped absolute deviation (SCAD) penalty, minimax concave penalty (MCP), log-sum penalty (LSP) and capped-$\ell_1$ penalty. The computational complexity analysis shows that the proposed algorithm enjoys low computational cost. Moreover, the convergence of the proposed algorithm is guaranteed. Extensive experimental evaluations on five benchmark datasets demonstrate the superior performance of the proposed algorithm to other three state-of-the-art approaches.