 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Diffusion Language Model Inference via Efficient KV Caching and Guided Diffusion
May 27, 2025



Diffusion language models offer parallel token generation and inherent bidirectionality, promising more efficient and powerful sequence modeling compared to autoregressive approaches. However, state-of-the-art diffusion models (e.g., Dream 7B, LLaDA 8B) suffer from slow inference. While they match the quality of similarly sized Autoregressive (AR) Models (e.g., Qwen2.5 7B, Llama3 8B), their iterative denoising requires multiple full-sequence forward passes, resulting in high computational costs and latency, particularly for long input prompts and long-context scenarios. Furthermore, parallel token generation introduces token incoherence problems, and current sampling heuristics suffer from significant quality drops with decreasing denoising steps. We address these limitations with two training-free techniques. First, we propose FreeCache, a Key-Value (KV) approximation caching technique that reuses stable KV projections across denoising steps, effectively reducing the computational cost of DLM inference. Second, we introduce Guided Diffusion, a training-free method that uses a lightweight pretrained autoregressive model to supervise token unmasking, dramatically reducing the total number of denoising iterations without sacrificing quality. We conduct extensive evaluations on open-source reasoning benchmarks, and our combined methods deliver up to a 34x end-to-end speedup without compromising accuracy. For the first time, diffusion language models achieve a comparable and even faster latency as the widely adopted autoregressive models. Our work successfully paved the way for scaling up the diffusion language model to a broader scope of applications across different domains.
PANDA -- Paired Anti-hate Narratives Dataset from Asia: Using an LLM-as-a-Judge to Create the First Chinese Counterspeech Dataset
Jan 04, 2025Despite the global prevalence of Modern Standard Chinese language, counterspeech (CS) resources for Chinese remain virtually nonexistent. To address this gap in East Asian counterspeech research we introduce the a corpus of Modern Standard Mandarin counterspeech that focuses on combating hate speech in Mainland China. This paper proposes a novel approach of generating CS by using an LLM-as-a-Judge, simulated annealing, LLMs zero-shot CN generation and a round-robin algorithm. This is followed by manual verification for quality and contextual relevance. This paper details the methodology for creating effective counterspeech in Chinese and other non-Eurocentric languages, including unique cultural patterns of which groups are maligned and linguistic patterns in what kinds of discourse markers are programmatically marked as hate speech (HS). Analysis of the generated corpora, we provide strong evidence for the lack of open-source, properly labeled Chinese hate speech data and the limitations of using an LLM-as-Judge to score possible answers in Chinese. Moreover, the present corpus serves as the first East Asian language based CS corpus and provides an essential resource for future research on counterspeech generation and evaluation.
CODEOFCONDUCT at Multilingual Counterspeech Generation: A Context-Aware Model for Robust Counterspeech Generation in Low-Resource Languages
Jan 04, 2025This paper introduces a context-aware model for robust counterspeech generation, which achieved significant success in the MCG-COLING-2025 shared task. Our approach particularly excelled in low-resource language settings. By leveraging a simulated annealing algorithm fine-tuned on multilingual datasets, the model generates factually accurate responses to hate speech. We demonstrate state-of-the-art performance across four languages (Basque, English, Italian, and Spanish), with our system ranking first for Basque, second for Italian, and third for both English and Spanish. Notably, our model swept all three top positions for Basque, highlighting its effectiveness in low-resource scenarios. Evaluation of the shared task employs both traditional metrics (BLEU, ROUGE, BERTScore, Novelty) and JudgeLM based on LLM. We present a detailed analysis of our results, including an empirical evaluation of the model performance and comprehensive score distributions across evaluation metrics. This work contributes to the growing body of research on multilingual counterspeech generation, offering insights into developing robust models that can adapt to diverse linguistic and cultural contexts in the fight against online hate speech.
BBS: Bi-directional Bit-level Sparsity for Deep Learning Acceleration
Sep 08, 2024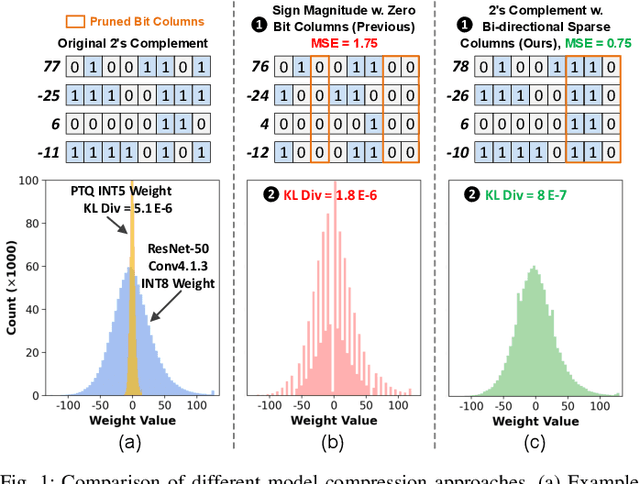
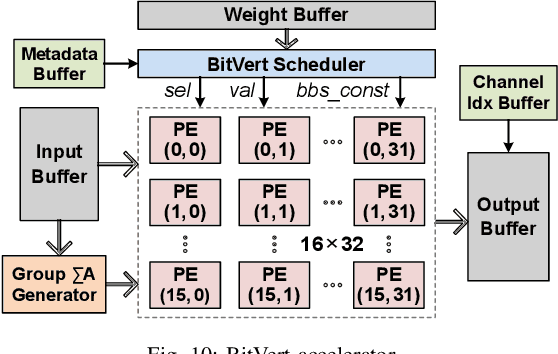
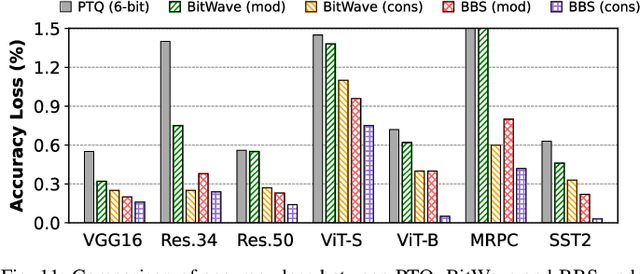
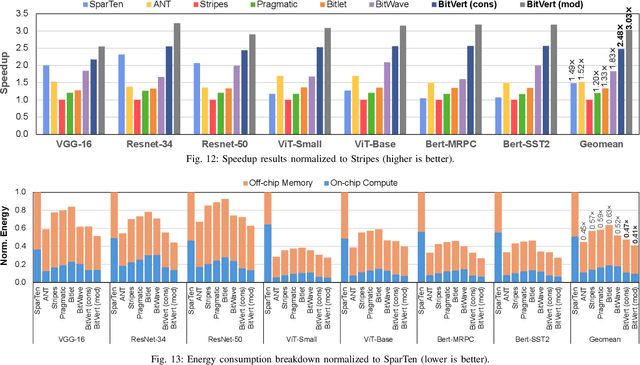
Bit-level sparsity methods skip ineffectual zero-bit operations and are typically applicable within bit-serial deep learning accelerators. This type of sparsity at the bit-level is especially interesting because it is both orthogonal and compatible with other deep neural network (DNN) efficiency methods such as quantization and pruning. In this work, we improve the practicality and efficiency of bitlevel sparsity through a novel algorithmic bit-pruning, averaging, and compression method, and a co-designed efficient bit-serial hardware accelerator. On the algorithmic side, we introduce bidirectional bit sparsity (BBS). The key insight of BBS is that we can leverage bit sparsity in a symmetrical way to prune either zero-bits or one-bits. This significantly improves the load balance of bit-serial computing and guarantees the level of sparsity to be more than 50%. On top of BBS, we further propose two bit-level binary pruning methods that require no retraining, and can be seamlessly applied to quantized DNNs. Combining binary pruning with a new tensor encoding scheme, BBS can both skip computation and reduce the memory footprint associated with bi-directional sparse bit columns. On the hardware side, we demonstrate the potential of BBS through BitVert, a bitserial architecture with an efficient PE design to accelerate DNNs with low overhead, exploiting our proposed binary pruning. Evaluation on seven representative DNN models shows that our approach achieves: (1) on average 1.66$\times$ reduction in model sizewith negligible accuracy loss of < 0.5%; (2) up to 3.03$\times$ speedupand 2.44$\times$ energy saving compared to prior DNN accelerators.
Torch2Chip: An End-to-end Customizable Deep Neural Network Compression and Deployment Toolkit for Prototype Hardware Accelerator Design
May 06, 2024



The development of model compression is continuously motivated by the evolution of various neural network accelerators with ASIC or FPGA. On the algorithm side, the ultimate goal of quantization or pruning is accelerating the expensive DNN computations on low-power hardware. However, such a "design-and-deploy" workflow faces under-explored challenges in the current hardware-algorithm co-design community. First, although the state-of-the-art quantization algorithm can achieve low precision with negligible degradation of accuracy, the latest deep learning framework (e.g., PyTorch) can only support non-customizable 8-bit precision, data format, and parameter extraction. Secondly, the objective of quantization is to enable the computation with low-precision data. However, the current SoTA algorithm treats the quantized integer as an intermediate result, while the final output of the quantizer is the "discretized" floating-point values, ignoring the practical needs and adding additional workload to hardware designers for integer parameter extraction and layer fusion. Finally, the compression toolkits designed by the industry are constrained to their in-house product or a handful of algorithms. The limited degree of freedom in the current toolkit and the under-explored customization hinder the prototype ASIC or FPGA-based accelerator design. To resolve these challenges, we propose Torch2Chip, an open-sourced, fully customizable, and high-performance toolkit that supports user-designed compression followed by automatic model fusion and parameter extraction. Torch2Chip incorporates the hierarchical design workflow, and the user-customized compression algorithm will be directly packed into the deployment-ready format for prototype chip verification with either CNN or vision transformer (ViT). The code is available at https://github.com/SeoLabCornell/torch2chip.
XGrad: Boosting Gradient-Based Optimizers With Weight Prediction
May 26, 2023



In this paper, we propose a general deep learning training framework XGrad which introduces weight prediction into the popular gradient-based optimizers to boost their convergence and generalization when training the deep neural network (DNN) models. In particular, ahead of each mini-batch training, the future weights are predicted according to the update rule of the used optimizer and are then applied to both the forward pass and backward propagation. In this way, during the whole training period, the optimizer always utilizes the gradients w.r.t. the future weights to update the DNN parameters, making the gradient-based optimizer achieve better convergence and generalization compared to the original optimizer without weight prediction. XGrad is rather straightforward to implement yet pretty effective in boosting the convergence of gradient-based optimizers and the accuracy of DNN models. Empirical results concerning the most three popular gradient-based optimizers including SGD with momentum, Adam, and AdamW demonstrate the effectiveness of our proposal. The experimental results validate that XGrad can attain higher model accuracy than the original optimizers when training the DNN models. The code of XGrad will be available at: https://github.com/guanleics/XGrad.