 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Human Cognition: Visual Context Guides Syntactic Priming in Fusion-Encoded Models
Feb 24, 2025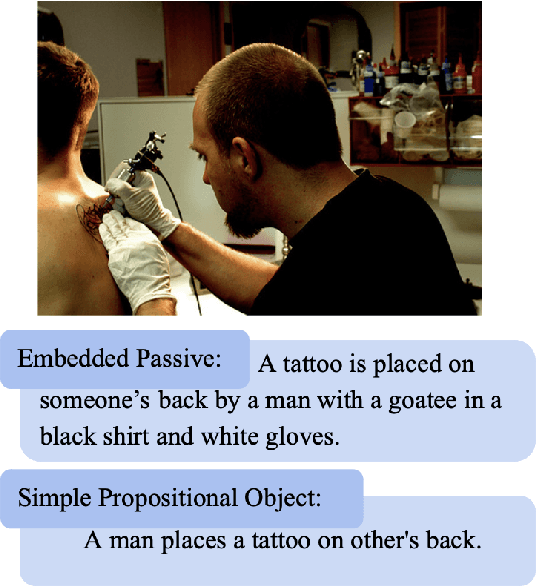
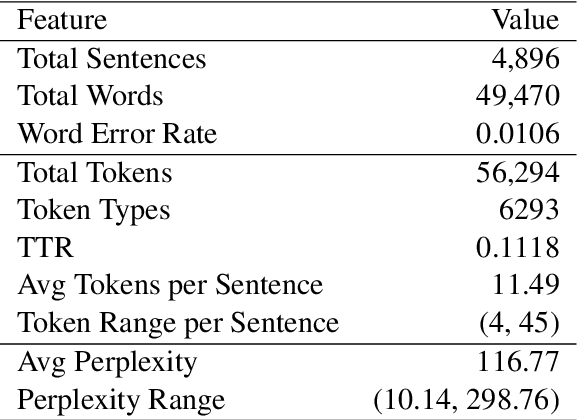
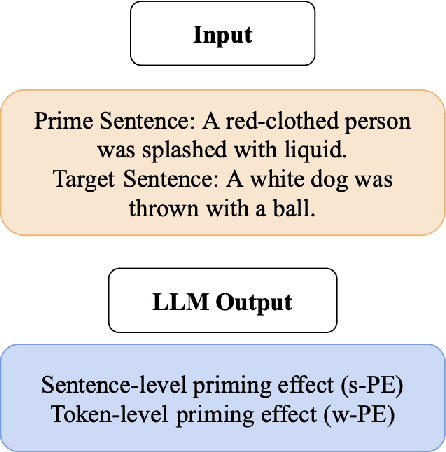
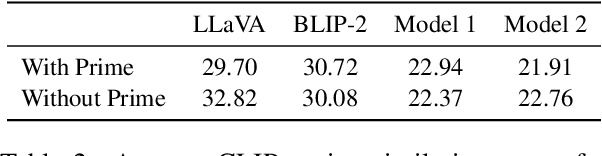
We introduced PRISMATIC, the first multimodal structural priming dataset, and proposed a reference-free evaluation metric that assesses priming effects without predefined target sentences. Using this metric, we constructed and tested models with different multimodal encoding architectures (dual encoder and fusion encoder) to investigate their structural preservation capabilities. Our findings show that models with both encoding methods demonstrate comparable syntactic priming effects. However, only fusion-encoded models exhibit robust positive correlations between priming effects and visual similarity, suggesting a cognitive process more aligned with human psycholinguistic patterns. This work provides new insights into evaluating and understanding how syntactic information is processed in multimodal language models.
PANDA -- Paired Anti-hate Narratives Dataset from Asia: Using an LLM-as-a-Judge to Create the First Chinese Counterspeech Dataset
Jan 04, 2025Despite the global prevalence of Modern Standard Chinese language, counterspeech (CS) resources for Chinese remain virtually nonexistent. To address this gap in East Asian counterspeech research we introduce the a corpus of Modern Standard Mandarin counterspeech that focuses on combating hate speech in Mainland China. This paper proposes a novel approach of generating CS by using an LLM-as-a-Judge, simulated annealing, LLMs zero-shot CN generation and a round-robin algorithm. This is followed by manual verification for quality and contextual relevance. This paper details the methodology for creating effective counterspeech in Chinese and other non-Eurocentric languages, including unique cultural patterns of which groups are maligned and linguistic patterns in what kinds of discourse markers are programmatically marked as hate speech (HS). Analysis of the generated corpora, we provide strong evidence for the lack of open-source, properly labeled Chinese hate speech data and the limitations of using an LLM-as-Judge to score possible answers in Chinese. Moreover, the present corpus serves as the first East Asian language based CS corpus and provides an essential resource for future research on counterspeech generation and evaluation.
CODEOFCONDUCT at Multilingual Counterspeech Generation: A Context-Aware Model for Robust Counterspeech Generation in Low-Resource Languages
Jan 04, 2025This paper introduces a context-aware model for robust counterspeech generation, which achieved significant success in the MCG-COLING-2025 shared task. Our approach particularly excelled in low-resource language settings. By leveraging a simulated annealing algorithm fine-tuned on multilingual datasets, the model generates factually accurate responses to hate speech. We demonstrate state-of-the-art performance across four languages (Basque, English, Italian, and Spanish), with our system ranking first for Basque, second for Italian, and third for both English and Spanish. Notably, our model swept all three top positions for Basque, highlighting its effectiveness in low-resource scenarios. Evaluation of the shared task employs both traditional metrics (BLEU, ROUGE, BERTScore, Novelty) and JudgeLM based on LLM. We present a detailed analysis of our results, including an empirical evaluation of the model performance and comprehensive score distributions across evaluation metrics. This work contributes to the growing body of research on multilingual counterspeech generation, offering insights into developing robust models that can adapt to diverse linguistic and cultural contexts in the fight against online hate speech.
TTQA-RS- A break-down prompting approach for Multi-hop Table-Text Question Answering with Reasoning and Summarization
Jun 20, 2024
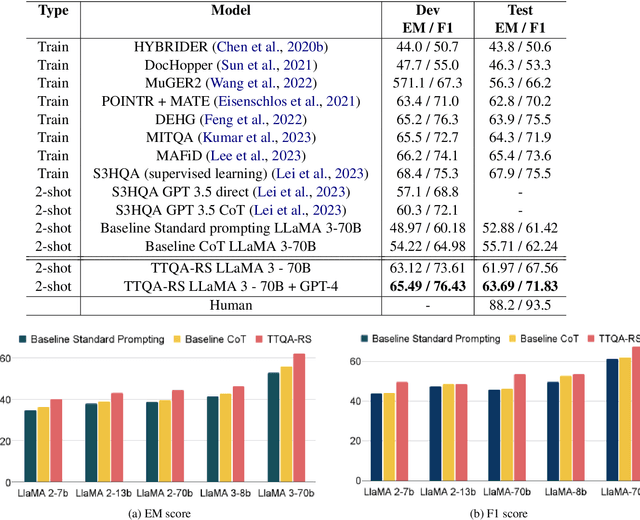
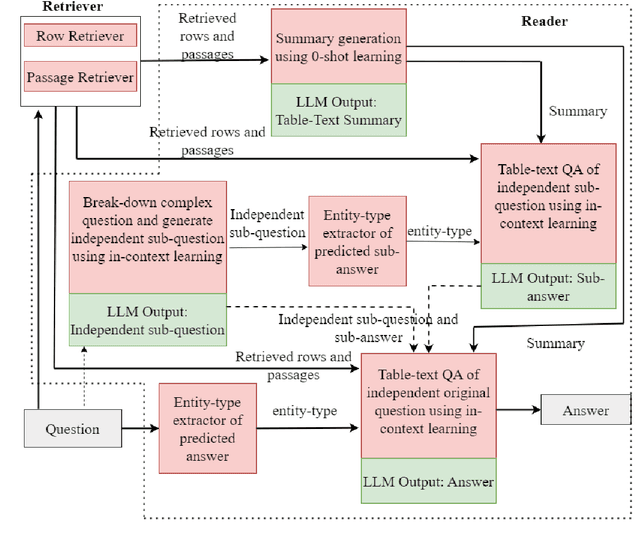
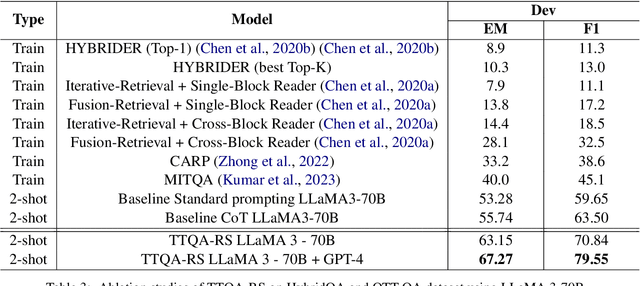
Question answering (QA) over tables and text has gained much popularity over the years. Multi-hop table-text QA requires multiple hops between the table and text, making it a challenging QA task. Although several works have attempted to solve the table-text QA task, most involve training the models and requiring labeled data. In this paper, we have proposed a model - TTQA-RS: A break-down prompting approach for Multi-hop Table-Text Question Answering with Reasoning and Summarization. Our model uses augmented knowledge including table-text summary with decomposed sub-question with answer for a reasoning-based table-text QA. Using open-source language models our model outperformed all existing prompting methods for table-text QA tasks on existing table-text QA datasets like HybridQA and OTT-QA's development set. Our results are comparable with the training-based state-of-the-art models, demonstrating the potential of prompt-based approaches using open-source LLMs. Additionally, by using GPT-4 with LLaMA3-70B, our model achieved state-of-the-art performance for prompting-based methods on multi-hop table-text QA.
Modeling Bilingual Sentence Processing: Evaluating RNN and Transformer Architectures for Cross-Language Structural Priming
May 15, 2024


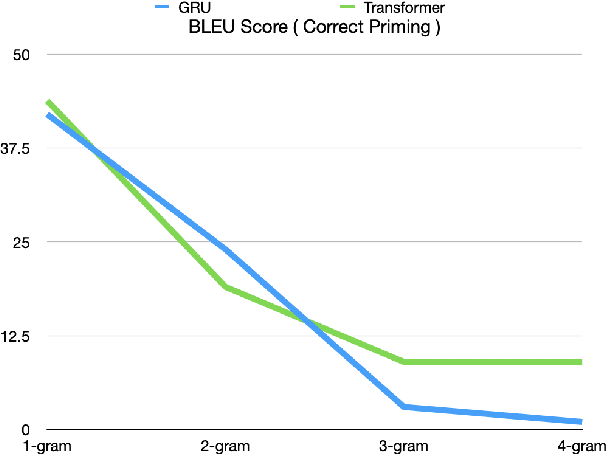
This study evaluates the performance of Recurrent Neural Network (RNN) and Transformer in replicating cross-language structural priming: a key indicator of abstract grammatical representations in human language processing. Focusing on Chinese-English priming, which involves two typologically distinct languages, we examine how these models handle the robust phenomenon of structural priming, where exposure to a particular sentence structure increases the likelihood of selecting a similar structure subsequently. Additionally, we utilize large language models (LLM) to measure the cross-lingual structural priming effect. Our findings indicate that Transformer outperform RNN in generating primed sentence structures, challenging the conventional belief that human sentence processing primarily involves recurrent and immediate processing and suggesting a role for cue-based retrieval mechanisms. Overall, this work contributes to our understanding of how computational models may reflect human cognitive processes in multilingual contexts.