 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Human Cognition: Visual Context Guides Syntactic Priming in Fusion-Encoded Models
Feb 24, 2025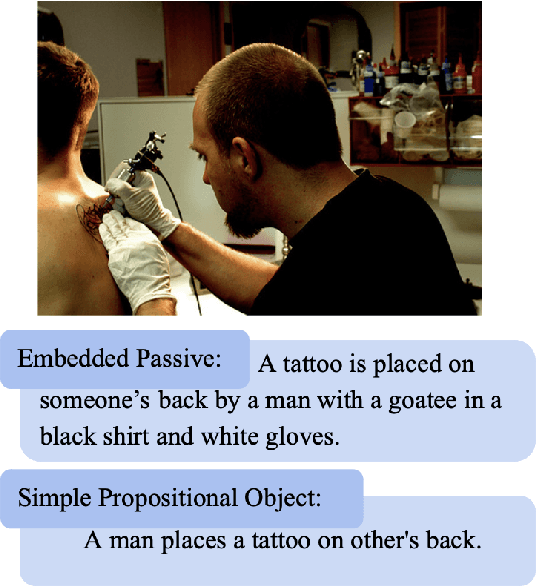
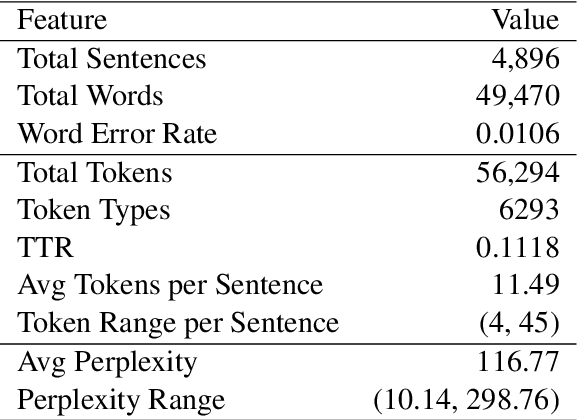
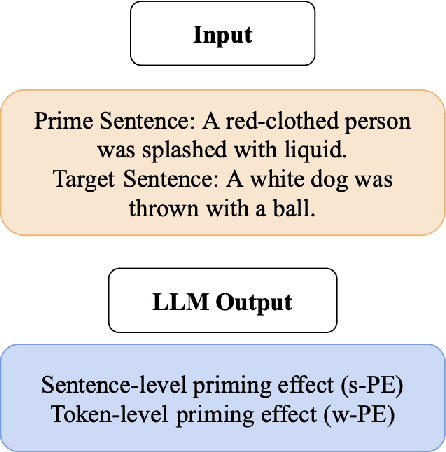
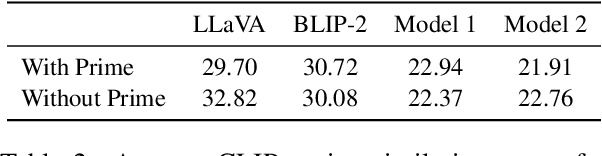
We introduced PRISMATIC, the first multimodal structural priming dataset, and proposed a reference-free evaluation metric that assesses priming effects without predefined target sentences. Using this metric, we constructed and tested models with different multimodal encoding architectures (dual encoder and fusion encoder) to investigate their structural preservation capabilities. Our findings show that models with both encoding methods demonstrate comparable syntactic priming effects. However, only fusion-encoded models exhibit robust positive correlations between priming effects and visual similarity, suggesting a cognitive process more aligned with human psycholinguistic patterns. This work provides new insights into evaluating and understanding how syntactic information is processed in multimodal language models.
TTQA-RS- A break-down prompting approach for Multi-hop Table-Text Question Answering with Reasoning and Summarization
Jun 20, 2024
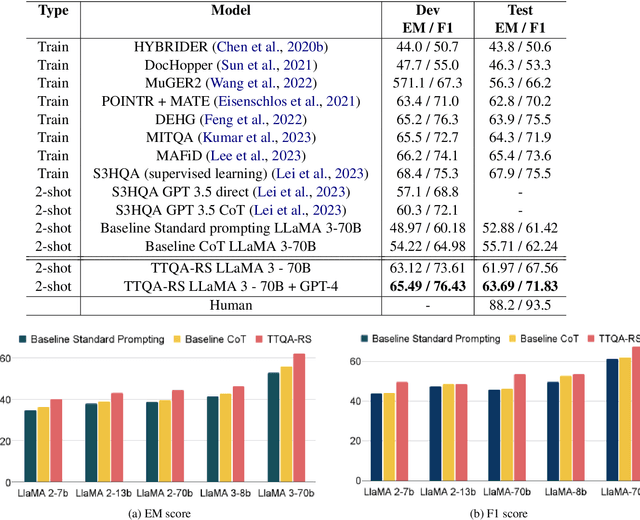
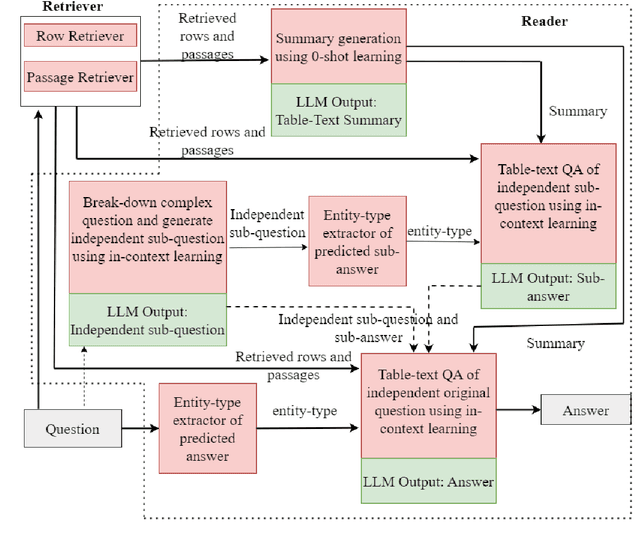
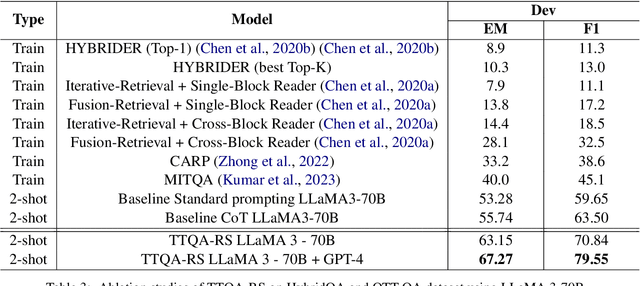
Question answering (QA) over tables and text has gained much popularity over the years. Multi-hop table-text QA requires multiple hops between the table and text, making it a challenging QA task. Although several works have attempted to solve the table-text QA task, most involve training the models and requiring labeled data. In this paper, we have proposed a model - TTQA-RS: A break-down prompting approach for Multi-hop Table-Text Question Answering with Reasoning and Summarization. Our model uses augmented knowledge including table-text summary with decomposed sub-question with answer for a reasoning-based table-text QA. Using open-source language models our model outperformed all existing prompting methods for table-text QA tasks on existing table-text QA datasets like HybridQA and OTT-QA's development set. Our results are comparable with the training-based state-of-the-art models, demonstrating the potential of prompt-based approaches using open-source LLMs. Additionally, by using GPT-4 with LLaMA3-70B, our model achieved state-of-the-art performance for prompting-based methods on multi-hop table-text QA.
Question Answering for Electronic Health Records: A Scoping Review of datasets and models
Oct 12, 2023



Question Answering (QA) systems on patient-related data can assist both clinicians and patients. They can, for example, assist clinicians in decision-making and enable patients to have a better understanding of their medical history. Significant amounts of patient data are stored in Electronic Health Records (EHRs), making EHR QA an important research area. In EHR QA, the answer is obtained from the medical record of the patient. Because of the differences in data format and modality, this differs greatly from other medical QA tasks that employ medical websites or scientific papers to retrieve answers, making it critical to research EHR question answering. This study aimed to provide a methodological review of existing works on QA over EHRs. We searched for articles from January 1st, 2005 to September 30th, 2023 in four digital sources including Google Scholar, ACL Anthology, ACM Digital Library, and PubMed to collect relevant publications on EHR QA. 4111 papers were identified for our study, and after screening based on our inclusion criteria, we obtained a total of 47 papers for further study. Out of the 47 papers, 25 papers were about EHR QA datasets, and 37 papers were about EHR QA models. It was observed that QA on EHRs is relatively new and unexplored. Most of the works are fairly recent. Also, it was observed that emrQA is by far the most popular EHR QA dataset, both in terms of citations and usage in other papers. Furthermore, we identified the different models used in EHR QA along with the evaluation metrics used for these models.
DrugEHRQA: A Question Answering Dataset on Structured and Unstructured Electronic Health Records For Medicine Related Queries
May 03, 2022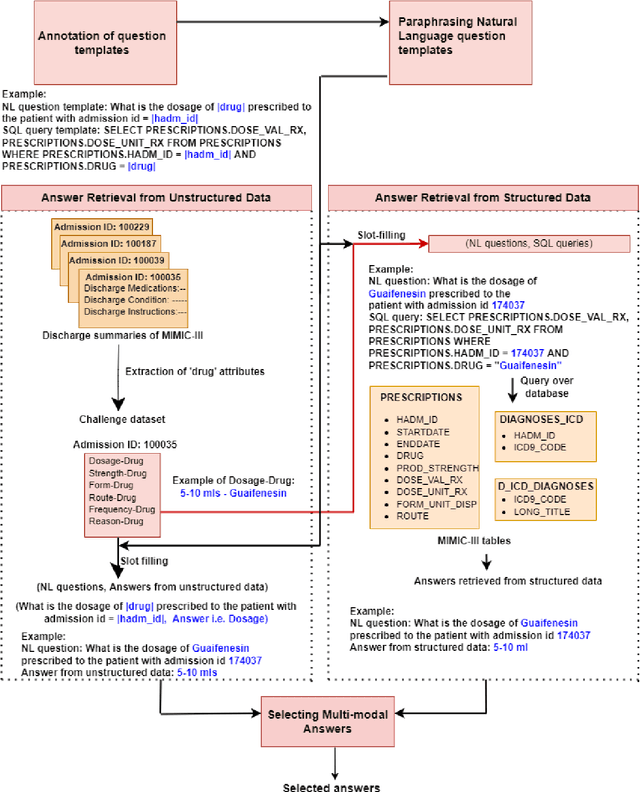


This paper develops the first question answering dataset (DrugEHRQA) containing question-answer pairs from both structured tables and unstructured notes from a publicly available Electronic Health Record (EHR). EHRs contain patient records, stored in structured tables and unstructured clinical notes. The information in structured and unstructured EHRs is not strictly disjoint: information may be duplicated, contradictory, or provide additional context between these sources. Our dataset has medication-related queries, containing over 70,000 question-answer pairs. To provide a baseline model and help analyze the dataset, we have used a simple model (MultimodalEHRQA) which uses the predictions of a modality selection network to choose between EHR tables and clinical notes to answer the questions. This is used to direct the questions to the table-based or text-based state-of-the-art QA model. In order to address the problem arising from complex, nested queries, this is the first time Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers (RAT-SQL) has been used to test the structure of query templates in EHR data. Our goal is to provide a benchmark dataset for multi-modal QA systems, and to open up new avenues of research in improving question answering over EHR structured data by using context from unstructured clinical data.