 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering by Denoising: Latent plug-and-play diffusion for single-cell data
Oct 26, 2025Single-cell RNA sequencing (scRNA-seq) enables the study of cellular heterogeneity. Yet, clustering accuracy, and with it downstream analyses based on cell labels, remain challenging due to measurement noise and biological variability. In standard latent spaces (e.g., obtained through PCA), data from different cell types can be projected close together, making accurate clustering difficult. We introduce a latent plug-and-play diffusion framework that separates the observation and denoising space. This separation is operationalized through a novel Gibbs sampling procedure: the learned diffusion prior is applied in a low-dimensional latent space to perform denoising, while to steer this process, noise is reintroduced into the original high-dimensional observation space. This unique "input-space steering" ensures the denoising trajectory remains faithful to the original data structure. Our approach offers three key advantages: (1) adaptive noise handling via a tunable balance between prior and observed data; (2) uncertainty quantification through principled uncertainty estimates for downstream analysis; and (3) generalizable denoising by leveraging clean reference data to denoise noisier datasets, and via averaging, improve quality beyond the training set. We evaluate robustness on both synthetic and real single-cell genomics data. Our method improves clustering accuracy on synthetic data across varied noise levels and dataset shifts. On real-world single-cell data, our method demonstrates improved biological coherence in the resulting cell clusters, with cluster boundaries that better align with known cell type markers and developmental trajectories.
Torch2Chip: An End-to-end Customizable Deep Neural Network Compression and Deployment Toolkit for Prototype Hardware Accelerator Design
May 06, 2024



The development of model compression is continuously motivated by the evolution of various neural network accelerators with ASIC or FPGA. On the algorithm side, the ultimate goal of quantization or pruning is accelerating the expensive DNN computations on low-power hardware. However, such a "design-and-deploy" workflow faces under-explored challenges in the current hardware-algorithm co-design community. First, although the state-of-the-art quantization algorithm can achieve low precision with negligible degradation of accuracy, the latest deep learning framework (e.g., PyTorch) can only support non-customizable 8-bit precision, data format, and parameter extraction. Secondly, the objective of quantization is to enable the computation with low-precision data. However, the current SoTA algorithm treats the quantized integer as an intermediate result, while the final output of the quantizer is the "discretized" floating-point values, ignoring the practical needs and adding additional workload to hardware designers for integer parameter extraction and layer fusion. Finally, the compression toolkits designed by the industry are constrained to their in-house product or a handful of algorithms. The limited degree of freedom in the current toolkit and the under-explored customization hinder the prototype ASIC or FPGA-based accelerator design. To resolve these challenges, we propose Torch2Chip, an open-sourced, fully customizable, and high-performance toolkit that supports user-designed compression followed by automatic model fusion and parameter extraction. Torch2Chip incorporates the hierarchical design workflow, and the user-customized compression algorithm will be directly packed into the deployment-ready format for prototype chip verification with either CNN or vision transformer (ViT). The code is available at https://github.com/SeoLabCornell/torch2chip.
FLORA: Fine-grained Low-Rank Architecture Search for Vision Transformer
Nov 07, 2023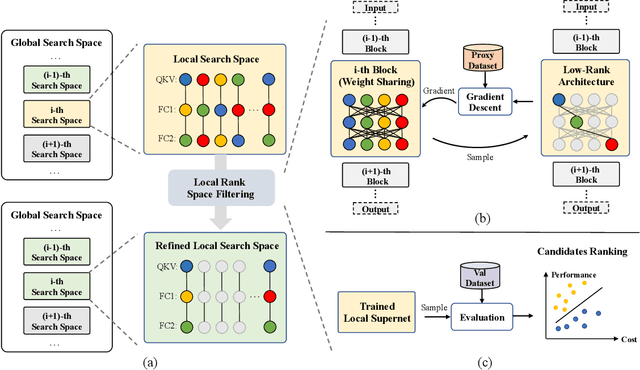
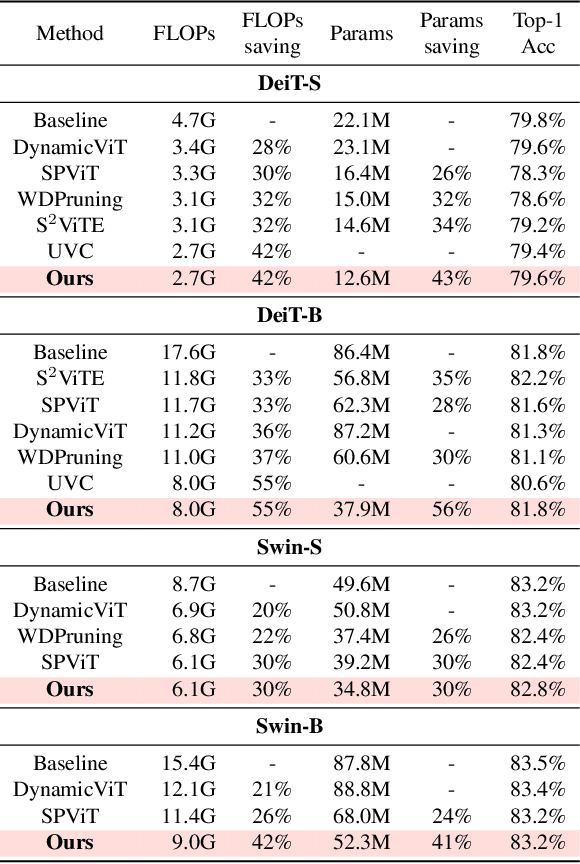
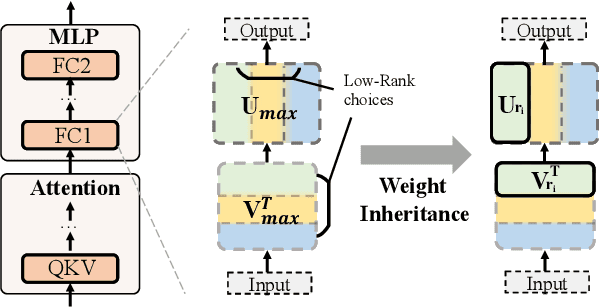
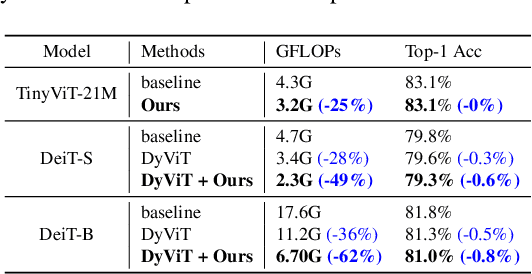
Vision Transformers (ViT) have recently demonstrated success across a myriad of computer vision tasks. However, their elevated computational demands pose significant challenges for real-world deployment. While low-rank approximation stands out as a renowned method to reduce computational loads, efficiently automating the target rank selection in ViT remains a challenge. Drawing from the notable similarity and alignment between the processes of rank selection and One-Shot NAS, we introduce FLORA, an end-to-end automatic framework based on NAS. To overcome the design challenge of supernet posed by vast search space, FLORA employs a low-rank aware candidate filtering strategy. This method adeptly identifies and eliminates underperforming candidates, effectively alleviating potential undertraining and interference among subnetworks. To further enhance the quality of low-rank supernets, we design a low-rank specific training paradigm. First, we propose weight inheritance to construct supernet and enable gradient sharing among low-rank modules. Secondly, we adopt low-rank aware sampling to strategically allocate training resources, taking into account inherited information from pre-trained models. Empirical results underscore FLORA's efficacy. With our method, a more fine-grained rank configuration can be generated automatically and yield up to 33% extra FLOPs reduction compared to a simple uniform configuration. More specific, FLORA-DeiT-B/FLORA-Swin-B can save up to 55%/42% FLOPs almost without performance degradtion. Importantly, FLORA boasts both versatility and orthogonality, offering an extra 21%-26% FLOPs reduction when integrated with leading compression techniques or compact hybrid structures. Our code is publicly available at https://github.com/shadowpa0327/FLORA.
LeanDojo: Theorem Proving with Retrieval-Augmented Language Models
Jun 27, 2023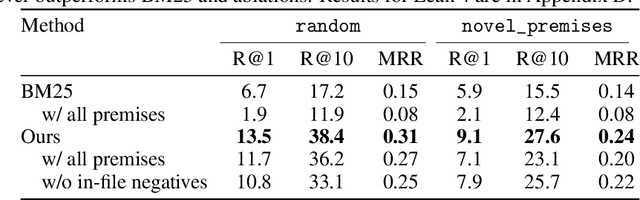
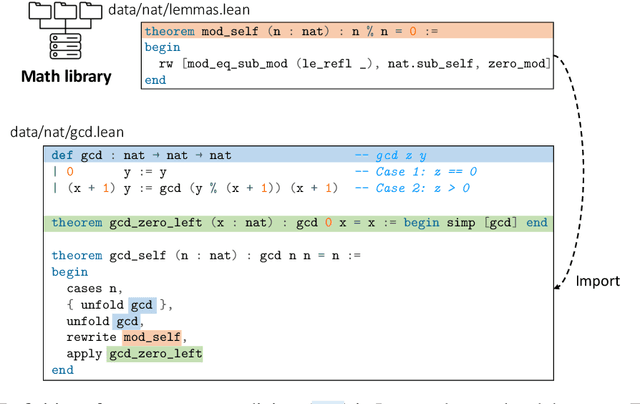

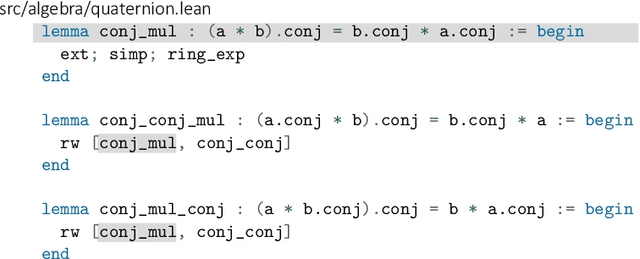
Large language models (LLMs) have shown promise in proving formal theorems using proof assistants such as Lean. However, existing methods are difficult to reproduce or build on, due to private code, data, and large compute requirements. This has created substantial barriers to research on machine learning methods for theorem proving. This paper removes these barriers by introducing LeanDojo: an open-source Lean playground consisting of toolkits, data, models, and benchmarks. LeanDojo extracts data from Lean and enables interaction with the proof environment programmatically. It contains fine-grained annotations of premises in proofs, providing valuable data for premise selection: a key bottleneck in theorem proving. Using this data, we develop ReProver (Retrieval-Augmented Prover): the first LLM-based prover that is augmented with retrieval for selecting premises from a vast math library. It is inexpensive and needs only one GPU week of training. Our retriever leverages LeanDojo's program analysis capability to identify accessible premises and hard negative examples, which makes retrieval much more effective. Furthermore, we construct a new benchmark consisting of 96,962 theorems and proofs extracted from Lean's math library. It features challenging data split requiring the prover to generalize to theorems relying on novel premises that are never used in training. We use this benchmark for training and evaluation, and experimental results demonstrate the effectiveness of ReProver over non-retrieval baselines and GPT-4. We thus provide the first set of open-source LLM-based theorem provers without any proprietary datasets and release it under a permissive MIT license to facilitate further research.
Regularizing Deep Neural Networks with Stochastic Estimators of Hessian Trace
Aug 11, 2022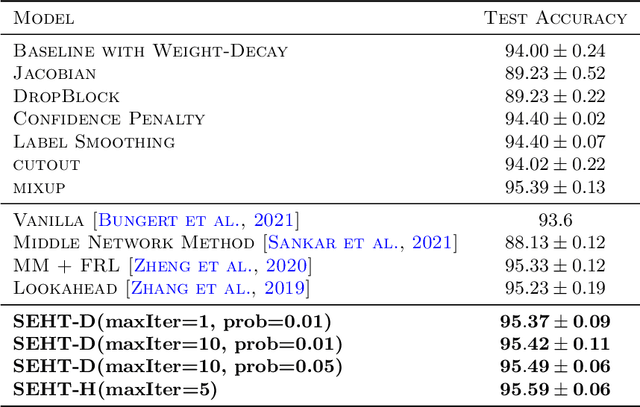
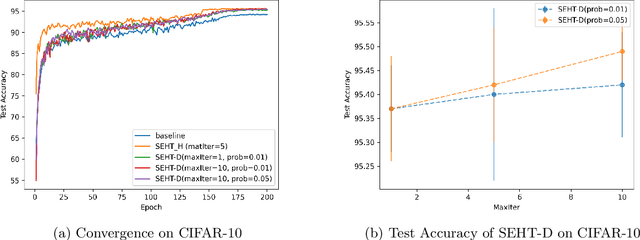
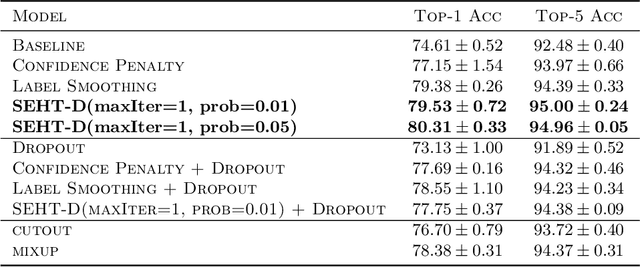

In this paper we develop a novel regularization method for deep neural networks by penalizing the trace of Hessian. This regularizer is motivated by a recent guarantee bound of the generalization error. Hutchinson method is a classical unbiased estimator for the trace of a matrix, but it is very time-consuming on deep learning models. Hence a dropout scheme is proposed to efficiently implements the Hutchinson method. Then we discuss a connection to linear stability of a nonlinear dynamical system and flat/sharp minima. Experiments demonstrate that our method outperforms existing regularizers and data augmentation methods, such as Jacobian, confidence penalty, and label smoothing, cutout and mixup.
Meta-Interpolation: Time-Arbitrary Frame Interpolation via Dual Meta-Learning
Jul 27, 2022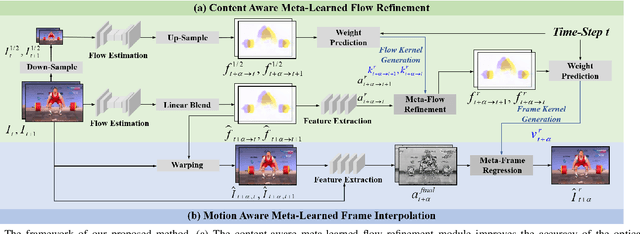


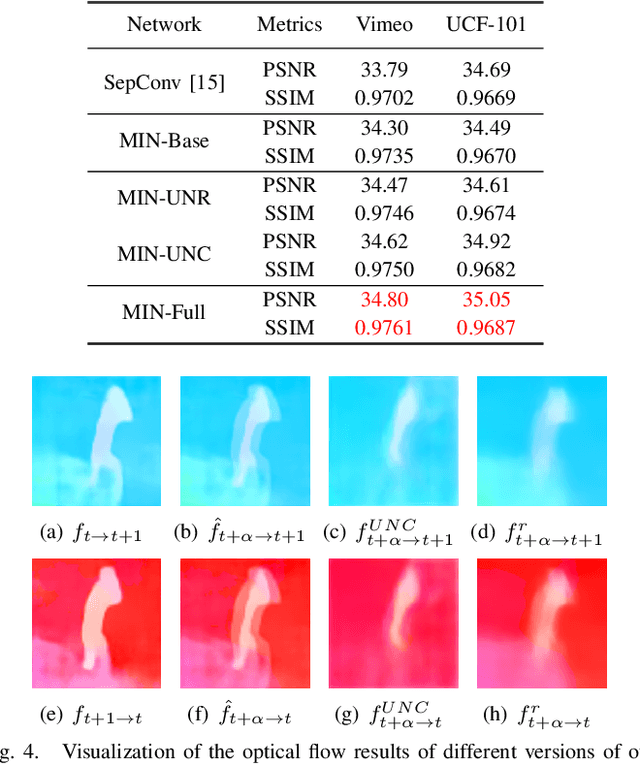
Existing video frame interpolation methods can only interpolate the frame at a given intermediate time-step, e.g. 1/2. In this paper, we aim to explore a more generalized kind of video frame interpolation, that at an arbitrary time-step. To this end, we consider processing different time-steps with adaptively generated convolutional kernels in a unified way with the help of meta-learning. Specifically, we develop a dual meta-learned frame interpolation framework to synthesize intermediate frames with the guidance of context information and optical flow as well as taking the time-step as side information. First, a content-aware meta-learned flow refinement module is built to improve the accuracy of the optical flow estimation based on the down-sampled version of the input frames. Second, with the refined optical flow and the time-step as the input, a motion-aware meta-learned frame interpolation module generates the convolutional kernels for every pixel used in the convolution operations on the feature map of the coarse warped version of the input frames to generate the predicted frame. Extensive qualitative and quantitative evaluations, as well as ablation studies, demonstrate that, via introducing meta-learning in our framework in such a well-designed way, our method not only achieves superior performance to state-of-the-art frame interpolation approaches but also owns an extended capacity to support the interpolation at an arbitrary time-step.
Unified Visual Transformer Compression
Mar 15, 2022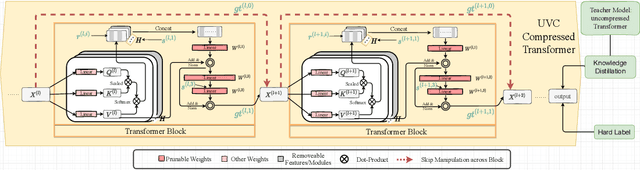
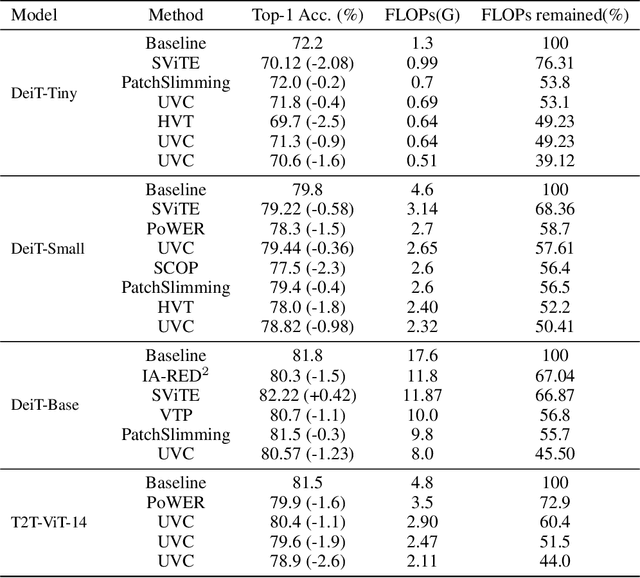
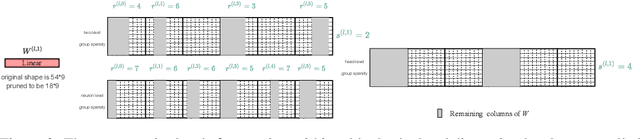
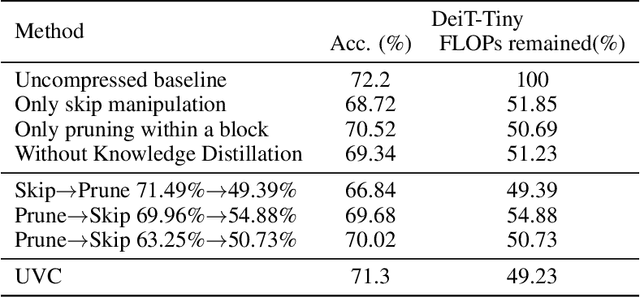
Vision transformers (ViTs) have gained popularity recently. Even without customized image operators such as convolutions, ViTs can yield competitive performance when properly trained on massive data. However, the computational overhead of ViTs remains prohibitive, due to stacking multi-head self-attention modules and else. Compared to the vast literature and prevailing success in compressing convolutional neural networks, the study of Vision Transformer compression has also just emerged, and existing works focused on one or two aspects of compression. This paper proposes a unified ViT compression framework that seamlessly assembles three effective techniques: pruning, layer skipping, and knowledge distillation. We formulate a budget-constrained, end-to-end optimization framework, targeting jointly learning model weights, layer-wise pruning ratios/masks, and skip configurations, under a distillation loss. The optimization problem is then solved using the primal-dual algorithm. Experiments are conducted with several ViT variants, e.g. DeiT and T2T-ViT backbones on the ImageNet dataset, and our approach consistently outperforms recent competitors. For example, DeiT-Tiny can be trimmed down to 50\% of the original FLOPs almost without losing accuracy. Codes are available online:~\url{https://github.com/VITA-Group/UVC}.
Hessian-Aware Pruning and Optimal Neural Implant
Feb 06, 2021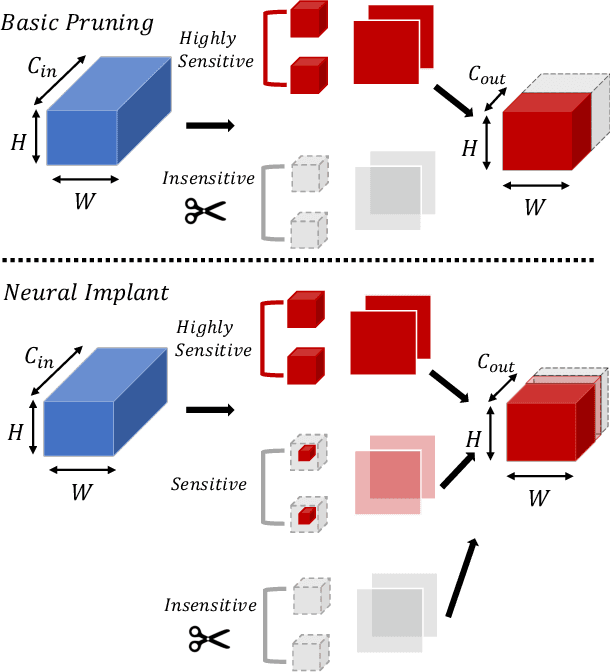
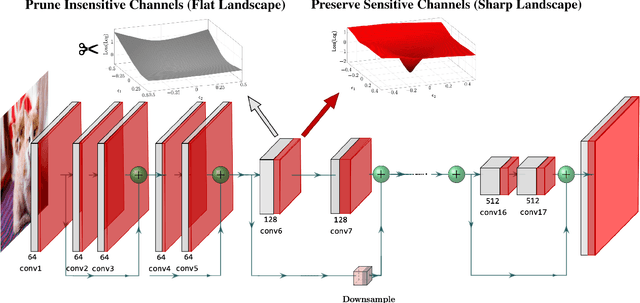
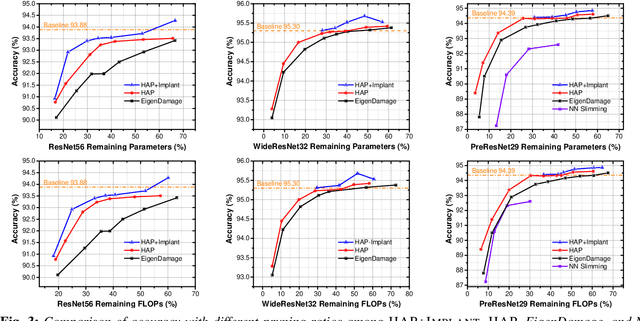
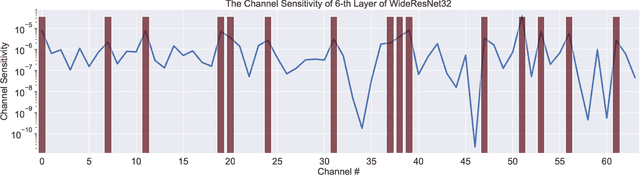
Pruning is an effective method to reduce the memory footprint and FLOPs associated with neural network models. However, existing structured-pruning methods often result in significant accuracy degradation for moderate pruning levels. To address this problem, we introduce a new Hessian Aware Pruning (HAP) method coupled with a Neural Implant approach that uses second-order sensitivity as a metric for structured pruning. The basic idea is to prune insensitive components and to use a Neural Implant for moderately sensitive components, instead of completely pruning them. For the latter approach, the moderately sensitive components are replaced with with a low rank implant that is smaller and less computationally expensive than the original component. We use the relative Hessian trace to measure sensitivity, as opposed to the magnitude based sensitivity metric commonly used in the literature. We test HAP on multiple models on CIFAR-10/ImageNet, and we achieve new state-of-the-art results. Specifically, HAP achieves 94.3\% accuracy ($<0.1\%$ degradation) on PreResNet29 (CIFAR-10), with more than 70\% of parameters pruned. Moreover, for ResNet50 HAP achieves 75.1\% top-1 accuracy (0.5\% degradation) on ImageNet, after pruning more than half of the parameters. The framework has been open sourced and available online.