 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircuitVAE: Efficient and Scalable Latent Circuit Optimization
Jun 13, 2024
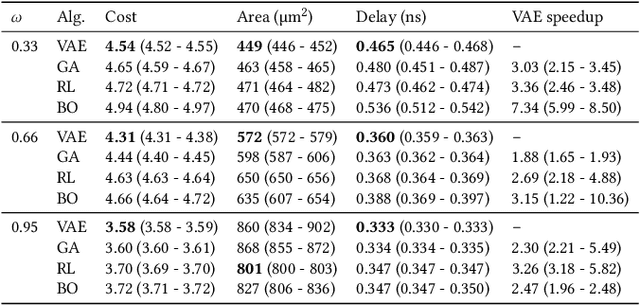
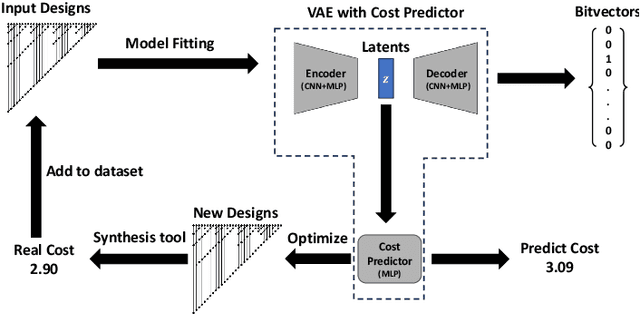
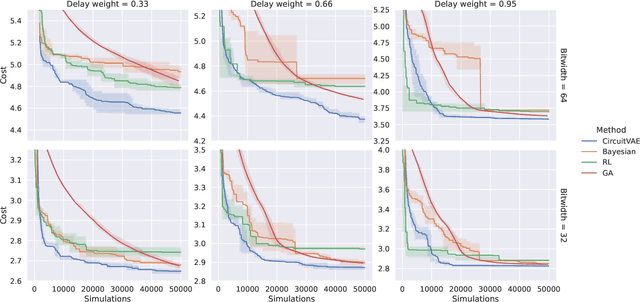
Automatically designing fast and space-efficient digital circuits is challenging because circuits are discrete, must exactly implement the desired logic, and are costly to simulate. We address these challenges with CircuitVAE, a search algorithm that embeds computation graphs in a continuous space and optimizes a learned surrogate of physical simulation by gradient descent. By carefully controlling overfitting of the simulation surrogate and ensuring diverse exploration, our algorithm is highly sample-efficient, yet gracefully scales to large problem instances and high sample budgets. We test CircuitVAE by designing binary adders across a large range of sizes, IO timing constraints, and sample budgets. Our method excels at designing large circuits, where other algorithms struggle: compared to reinforcement learning and genetic algorithms, CircuitVAE typically finds 64-bit adders which are smaller and faster using less than half the sample budget. We also find CircuitVAE can design state-of-the-art adders in a real-world chip, demonstrating that our method can outperform commercial tools in a realistic setting.
Polaris: A Safety-focused LLM Constellation Architecture for Healthcare
Mar 20, 2024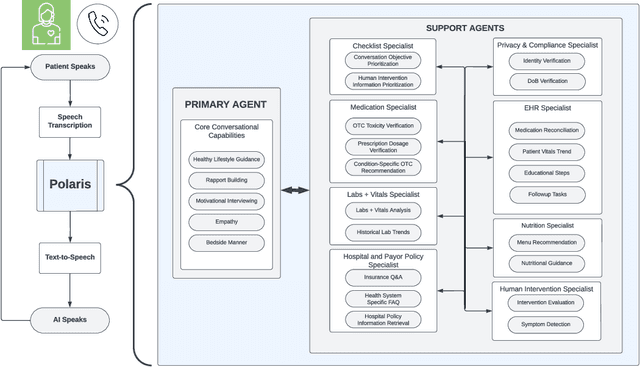
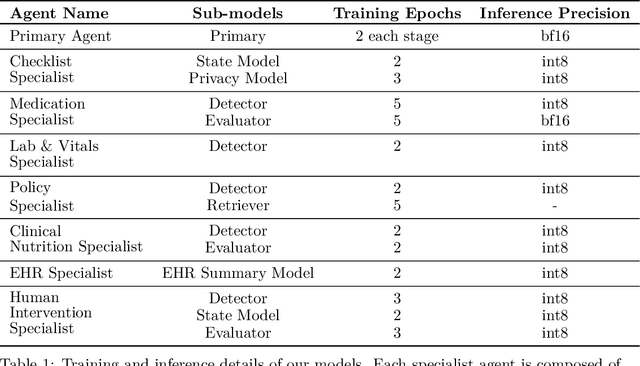
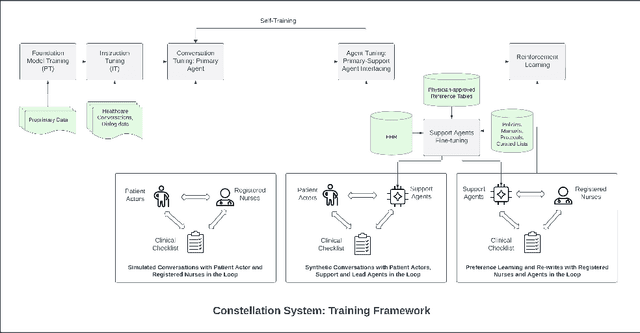
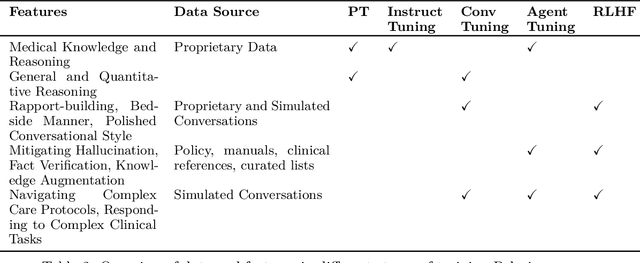
We develop Polaris, the first safety-focused LLM constellation for real-time patient-AI healthcare conversations. Unlike prior LLM works in healthcare focusing on tasks like question answering, our work specifically focuses on long multi-turn voice conversations. Our one-trillion parameter constellation system is composed of several multibillion parameter LLMs as co-operative agents: a stateful primary agent that focuses on driving an engaging conversation and several specialist support agents focused on healthcare tasks performed by nurses to increase safety and reduce hallucinations. We develop a sophisticated training protocol for iterative co-training of the agents that optimize for diverse objectives. We train our models on proprietary data, clinical care plans, healthcare regulatory documents, medical manuals, and other medical reasoning documents. We align our models to speak like medical professionals, using organic healthcare conversations and simulated ones between patient actors and experienced nurses. This allows our system to express unique capabilities such as rapport building, trust building, empathy and bedside manner. Finally, we present the first comprehensive clinician evaluation of an LLM system for healthcare. We recruited over 1100 U.S. licensed nurses and over 130 U.S. licensed physicians to perform end-to-end conversational evaluations of our system by posing as patients and rating the system on several measures. We demonstrate Polaris performs on par with human nurses on aggregate across dimensions such as medical safety, clinical readiness, conversational quality, and bedside manner. Additionally, we conduct a challenging task-based evaluation of the individual specialist support agents, where we demonstrate our LLM agents significantly outperform a much larger general-purpose LLM (GPT-4) as well as from its own medium-size class (LLaMA-2 70B).
GraPhSyM: Graph Physical Synthesis Model
Aug 07, 2023In this work, we introduce GraPhSyM, a Graph Attention Network (GATv2) model for fast and accurate estimation of post-physical synthesis circuit delay and area metrics from pre-physical synthesis circuit netlists. Once trained, GraPhSyM provides accurate visibility of final design metrics to early EDA stages, such as logic synthesis, without running the slow physical synthesis flow, enabling global co-optimization across stages. Additionally, the swift and precise feedback provided by GraPhSym is instrumental for machine-learning-based EDA optimization frameworks. Given a gate-level netlist of a circuit represented as a graph, GraPhSyM utilizes graph structure, connectivity, and electrical property features to predict the impact of physical synthesis transformations such as buffer insertion and gate sizing. When trained on a dataset of 6000 prefix adder designs synthesized at an aggressive delay target, GraPhSyM can accurately predict the post-synthesis delay (98.3%) and area (96.1%) metrics of unseen adders with a fast 0.22s inference time. Furthermore, we illustrate the compositionality of GraPhSyM by employing the model trained on a fixed delay target to accurately anticipate post-synthesis metrics at a variety of unseen delay targets. Lastly, we report promising generalization capabilities of the GraPhSyM model when it is evaluated on circuits different from the adders it was exclusively trained on. The results show the potential for GraPhSyM to serve as a powerful tool for advanced optimization techniques and as an oracle for EDA machine learning frameworks.
LeanDojo: Theorem Proving with Retrieval-Augmented Language Models
Jun 27, 2023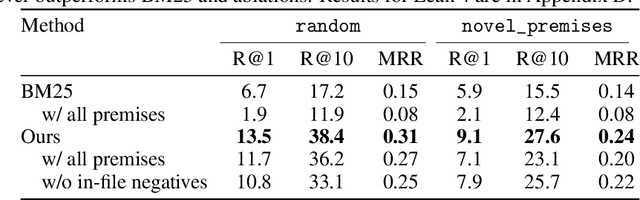
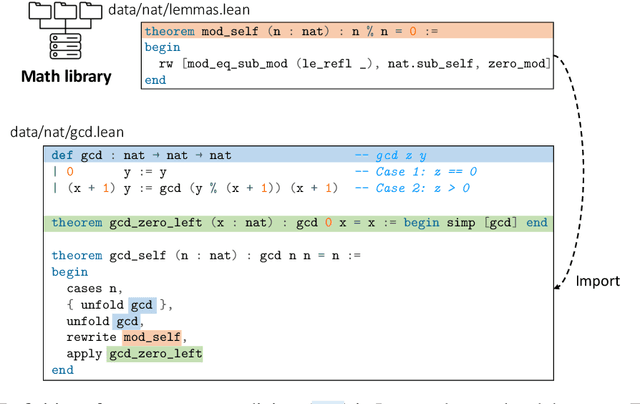

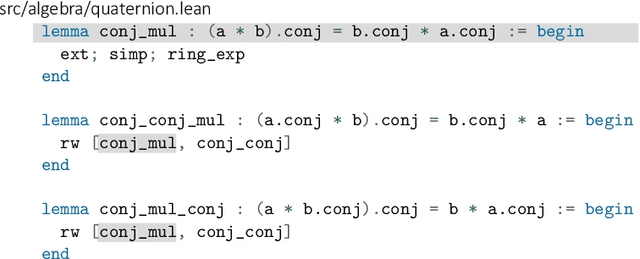
Large language models (LLMs) have shown promise in proving formal theorems using proof assistants such as Lean. However, existing methods are difficult to reproduce or build on, due to private code, data, and large compute requirements. This has created substantial barriers to research on machine learning methods for theorem proving. This paper removes these barriers by introducing LeanDojo: an open-source Lean playground consisting of toolkits, data, models, and benchmarks. LeanDojo extracts data from Lean and enables interaction with the proof environment programmatically. It contains fine-grained annotations of premises in proofs, providing valuable data for premise selection: a key bottleneck in theorem proving. Using this data, we develop ReProver (Retrieval-Augmented Prover): the first LLM-based prover that is augmented with retrieval for selecting premises from a vast math library. It is inexpensive and needs only one GPU week of training. Our retriever leverages LeanDojo's program analysis capability to identify accessible premises and hard negative examples, which makes retrieval much more effective. Furthermore, we construct a new benchmark consisting of 96,962 theorems and proofs extracted from Lean's math library. It features challenging data split requiring the prover to generalize to theorems relying on novel premises that are never used in training. We use this benchmark for training and evaluation, and experimental results demonstrate the effectiveness of ReProver over non-retrieval baselines and GPT-4. We thus provide the first set of open-source LLM-based theorem provers without any proprietary datasets and release it under a permissive MIT license to facilitate further research.
PrefixRL: Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning
May 14, 2022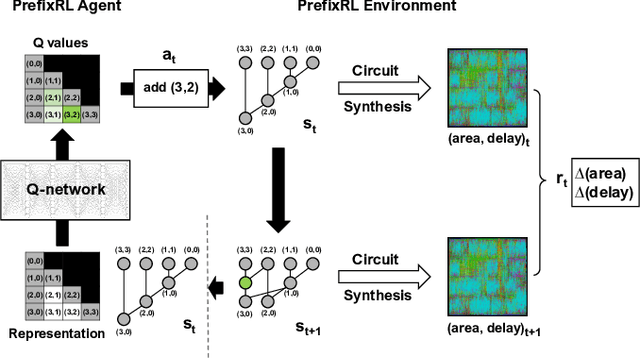
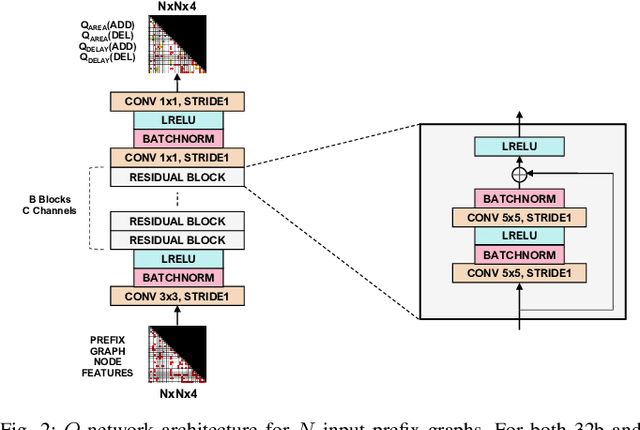
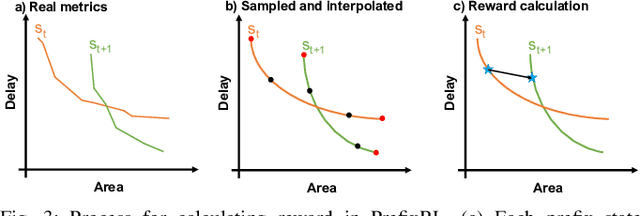
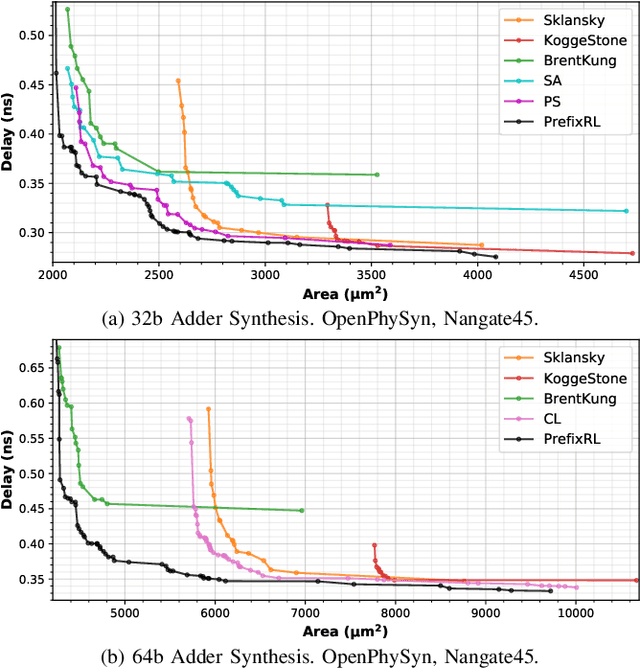
In this work, we present a reinforcement learning (RL) based approach to designing parallel prefix circuits such as adders or priority encoders that are fundamental to high-performance digital design. Unlike prior methods, our approach designs solutions tabula rasa purely through learning with synthesis in the loop. We design a grid-based state-action representation and an RL environment for constructing legal prefix circuits. Deep Convolutional RL agents trained on this environment produce prefix adder circuits that Pareto-dominate existing baselines with up to 16.0% and 30.2% lower area for the same delay in the 32b and 64b settings respectively. We observe that agents trained with open-source synthesis tools and cell library can design adder circuits that achieve lower area and delay than commercial tool adders in an industrial cell library.
* Copyright 2021 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Guiding Global Placement With Reinforcement Learning
Sep 06, 2021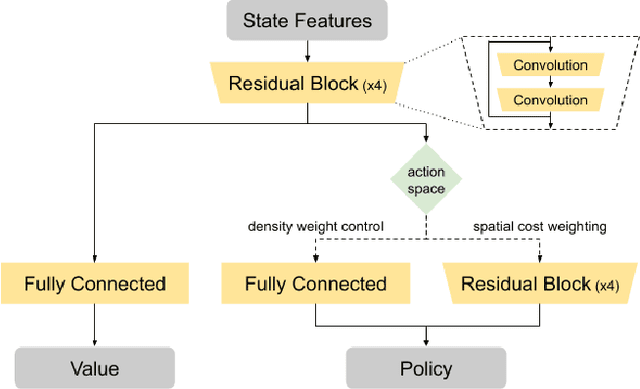
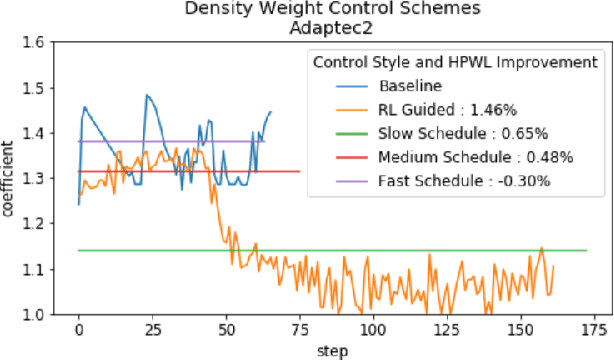

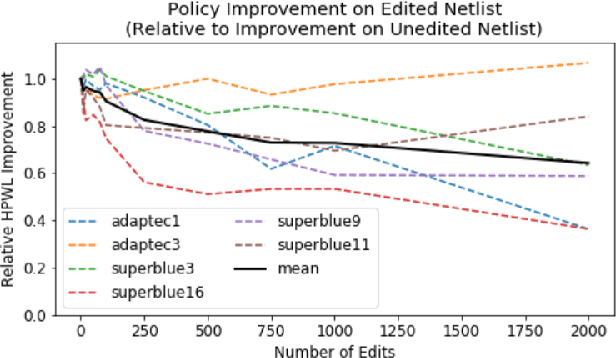
Recent advances in GPU accelerated global and detail placement have reduced the time to solution by an order of magnitude. This advancement allows us to leverage data driven optimization (such as Reinforcement Learning) in an effort to improve the final quality of placement results. In this work we augment state-of-the-art, force-based global placement solvers with a reinforcement learning agent trained to improve the final detail placed Half Perimeter Wire Length (HPWL). We propose novel control schemes with either global or localized control of the placement process. We then train reinforcement learning agents to use these controls to guide placement to improved solutions. In both cases, the augmented optimizer finds improved placement solutions. Our trained agents achieve an average 1% improvement in final detail place HPWL across a range of academic benchmarks and more than 1% in global place HPWL on real industry designs.
Improving SAT Solver Heuristics with Graph Networks and Reinforcement Learning
Sep 26, 2019
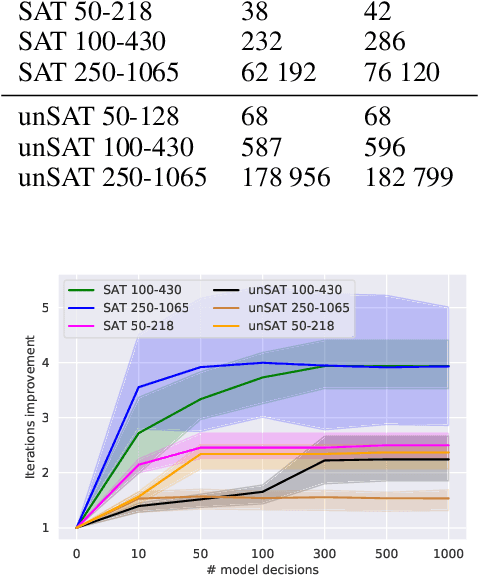
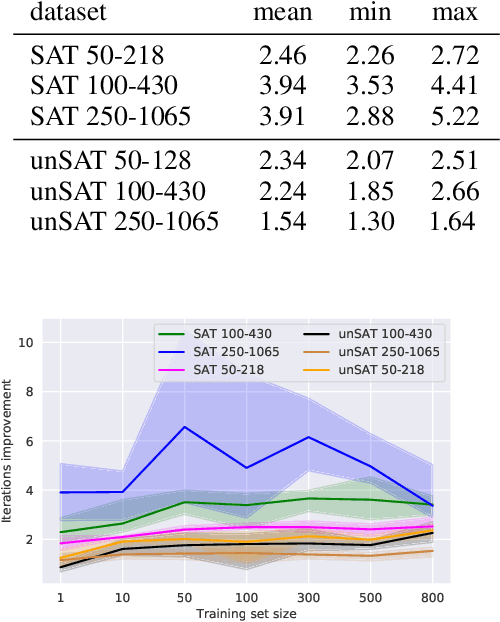
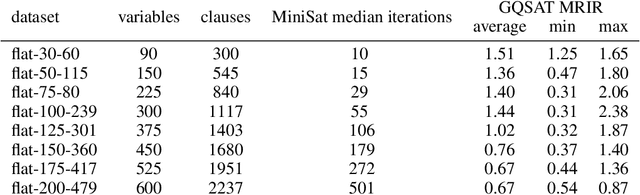
We present GQSAT, a branching heuristic in a Boolean SAT solver trained with value-based reinforcement learning (RL) using Graph Neural Networks for function approximation. Solvers using GQSAT are complete SAT solvers that either provide a satisfying assignment or a proof of unsatisfiability, which is required for many SAT applications. The branching heuristic commonly used in SAT solvers today suffers from bad decisions during their warm-up period, whereas GQSAT has been trained to examine the structure of the particular problem instance to make better decisions at the beginning of the search. Training GQSAT is data efficient and does not require elaborate dataset preparation or feature engineering to train. We train GQSAT on small SAT problems using RL interfacing with an existing SAT solver. We show that GQSAT is able to reduce the number of iterations required to solve SAT problems by 2-3X, and it generalizes to unsatisfiable SAT instances, as well as to problems with 5X more variables than it was trained on. We also show that, to a lesser extent, it generalizes to SAT problems from different domains by evaluating it on graph coloring. Our experiments show that augmenting SAT solvers with agents trained with RL and graph neural networks can improve performance on the SAT search problem.