 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSotopia-RL: Reward Design for Social Intelligence
Aug 05, 2025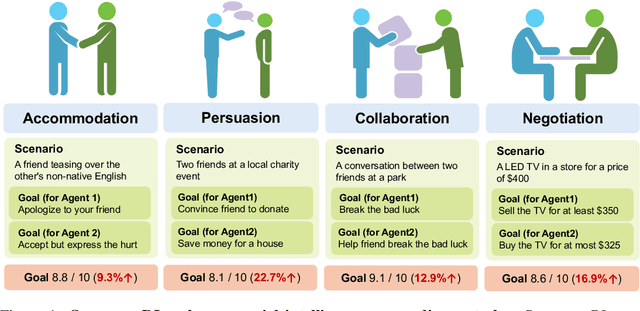
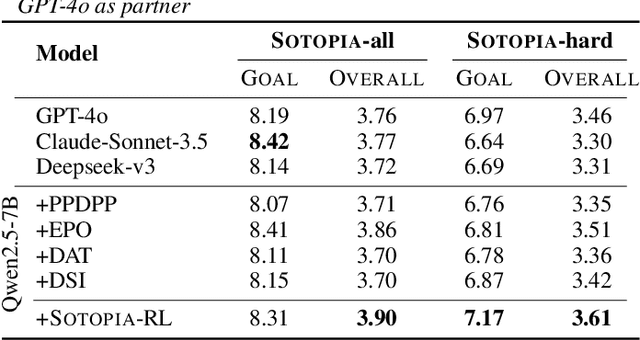
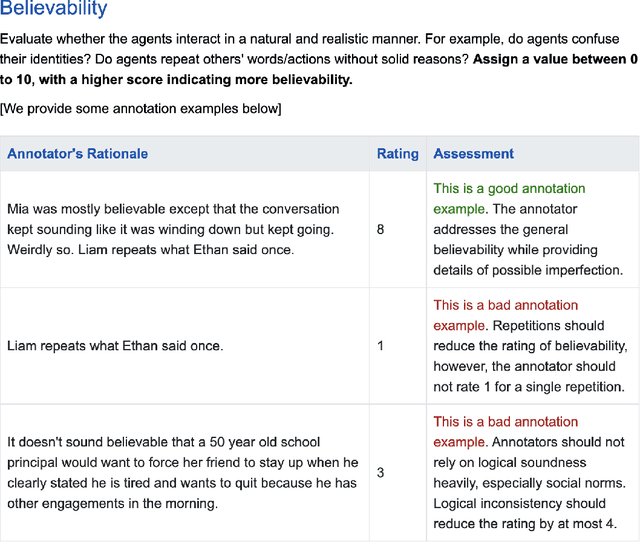
Social intelligence has become a critical capability for large language models (LLMs), enabling them to engage effectively in real-world social tasks such as accommodation, persuasion, collaboration, and negotiation. Reinforcement learning (RL) is a natural fit for training socially intelligent agents because it allows models to learn sophisticated strategies directly through social interactions. However, social interactions have two key characteristics that set barriers for RL training: (1) partial observability, where utterances have indirect and delayed effects that complicate credit assignment, and (2) multi-dimensionality, where behaviors such as rapport-building or knowledge-seeking contribute indirectly to goal achievement. These characteristics make Markov decision process (MDP)-based RL with single-dimensional episode-level rewards inefficient and unstable. To address these challenges, we propose Sotopia-RL, a novel framework that refines coarse episode-level feedback into utterance-level, multi-dimensional rewards. Utterance-level credit assignment mitigates partial observability by attributing outcomes to individual utterances, while multi-dimensional rewards capture the full richness of social interactions and reduce reward hacking. Experiments in Sotopia, an open-ended social learning environment, demonstrate that Sotopia-RL achieves state-of-the-art social goal completion scores (7.17 on Sotopia-hard and 8.31 on Sotopia-full), significantly outperforming existing approaches. Ablation studies confirm the necessity of both utterance-level credit assignment and multi-dimensional reward design for RL training. Our implementation is publicly available at: https://github.com/sotopia-lab/sotopia-rl.
Collaborating Action by Action: A Multi-agent LLM Framework for Embodied Reasoning
Apr 24, 2025Collaboration is ubiquitous and essential in day-to-day life -- from exchanging ideas, to delegating tasks, to generating plans together. This work studies how LLMs can adaptively collaborate to perform complex embodied reasoning tasks. To this end we introduce MINDcraft, an easily extensible platform built to enable LLM agents to control characters in the open-world game of Minecraft; and MineCollab, a benchmark to test the different dimensions of embodied and collaborative reasoning. An experimental study finds that the primary bottleneck in collaborating effectively for current state-of-the-art agents is efficient natural language communication, with agent performance dropping as much as 15% when they are required to communicate detailed task completion plans. We conclude that existing LLM agents are ill-optimized for multi-agent collaboration, especially in embodied scenarios, and highlight the need to employ methods beyond in-context and imitation learning. Our website can be found here: https://mindcraft-minecollab.github.io/
Skill Set Optimization: Reinforcing Language Model Behavior via Transferable Skills
Feb 05, 2024



Large language models (LLMs) have recently been used for sequential decision making in interactive environments. However, leveraging environment reward signals for continual LLM actor improvement is not straightforward. We propose Skill Set Optimization (SSO) for improving LLM actor performance through constructing and refining sets of transferable skills. SSO constructs skills by extracting common subtrajectories with high rewards and generating subgoals and instructions to represent each skill. These skills are provided to the LLM actor in-context to reinforce behaviors with high rewards. Then, SSO further refines the skill set by pruning skills that do not continue to result in high rewards. We evaluate our method in the classic videogame NetHack and the text environment ScienceWorld to demonstrate SSO's ability to optimize a set of skills and perform in-context policy improvement. SSO outperforms baselines by 40% in our custom NetHack task and outperforms the previous state-of-the-art in ScienceWorld by 35%.
Selective Perception: Optimizing State Descriptions with Reinforcement Learning for Language Model Actors
Jul 21, 2023


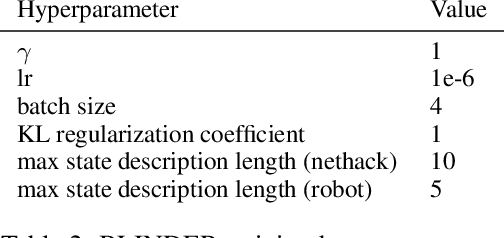
Large language models (LLMs) are being applied as actors for sequential decision making tasks in domains such as robotics and games, utilizing their general world knowledge and planning abilities. However, previous work does little to explore what environment state information is provided to LLM actors via language. Exhaustively describing high-dimensional states can impair performance and raise inference costs for LLM actors. Previous LLM actors avoid the issue by relying on hand-engineered, task-specific protocols to determine which features to communicate about a state and which to leave out. In this work, we propose Brief Language INputs for DEcision-making Responses (BLINDER), a method for automatically selecting concise state descriptions by learning a value function for task-conditioned state descriptions. We evaluate BLINDER on the challenging video game NetHack and a robotic manipulation task. Our method improves task success rate, reduces input size and compute costs, and generalizes between LLM actors.
Do Embodied Agents Dream of Pixelated Sheep?: Embodied Decision Making using Language Guided World Modelling
Jan 28, 2023Reinforcement learning (RL) agents typically learn tabula rasa, without prior knowledge of the world, which makes learning complex tasks with sparse rewards difficult. If initialized with knowledge of high-level subgoals and transitions between subgoals, RL agents could utilize this Abstract World Model (AWM) for planning and exploration. We propose using few-shot large language models (LLMs) to hypothesize an AWM, that is tested and verified during exploration, to improve sample efficiency in embodied RL agents. Our DECKARD agent applies LLM-guided exploration to item crafting in Minecraft in two phases: (1) the Dream phase where the agent uses an LLM to decompose a task into a sequence of subgoals, the hypothesized AWM; and (2) the Wake phase where the agent learns a modular policy for each subgoal and verifies or corrects the hypothesized AWM on the basis of its experiences. Our method of hypothesizing an AWM with LLMs and then verifying the AWM based on agent experience not only increases sample efficiency over contemporary methods by an order of magnitude but is also robust to and corrects errors in the LLM, successfully blending noisy internet-scale information from LLMs with knowledge grounded in environment dynamics.
Learning to Query Internet Text for Informing Reinforcement Learning Agents
May 25, 2022
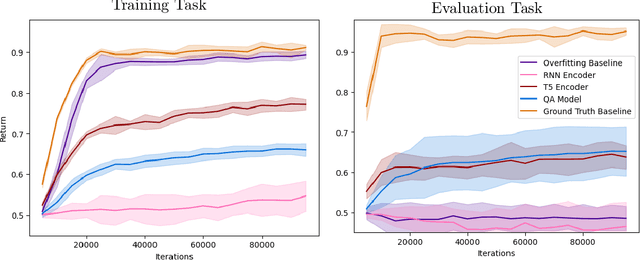

Generalization to out of distribution tasks in reinforcement learning is a challenging problem. One successful approach improves generalization by conditioning policies on task or environment descriptions that provide information about the current transition or reward functions. Previously, these descriptions were often expressed as generated or crowd sourced text. In this work, we begin to tackle the problem of extracting useful information from natural language found in the wild (e.g. internet forums, documentation, and wikis). These natural, pre-existing sources are especially challenging, noisy, and large and present novel challenges compared to previous approaches. We propose to address these challenges by training reinforcement learning agents to learn to query these sources as a human would, and we experiment with how and when an agent should query. To address the \textit{how}, we demonstrate that pretrained QA models perform well at executing zero-shot queries in our target domain. Using information retrieved by a QA model, we train an agent to learn \textit{when} it should execute queries. We show that our method correctly learns to execute queries to maximize reward in a reinforcement learning setting.
Guiding Global Placement With Reinforcement Learning
Sep 06, 2021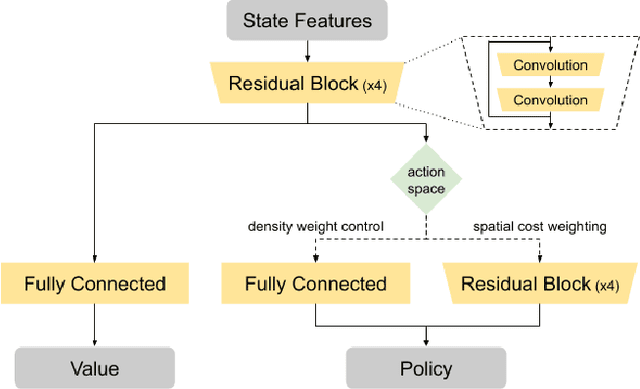
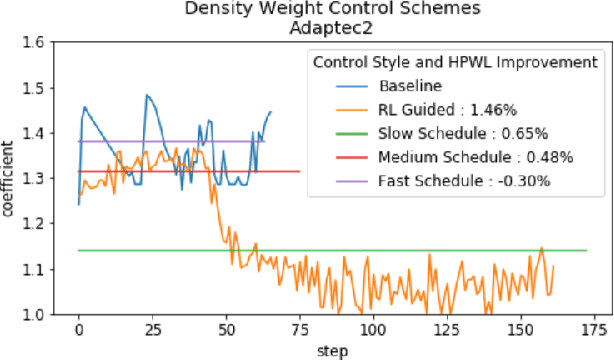

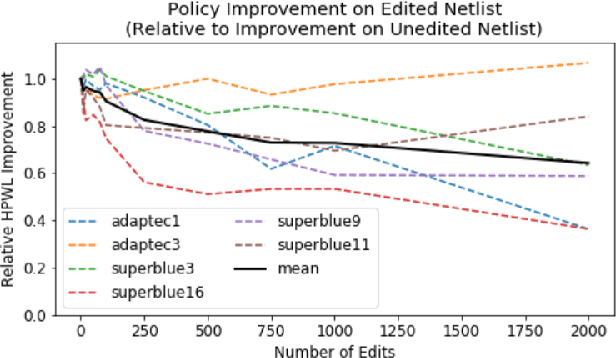
Recent advances in GPU accelerated global and detail placement have reduced the time to solution by an order of magnitude. This advancement allows us to leverage data driven optimization (such as Reinforcement Learning) in an effort to improve the final quality of placement results. In this work we augment state-of-the-art, force-based global placement solvers with a reinforcement learning agent trained to improve the final detail placed Half Perimeter Wire Length (HPWL). We propose novel control schemes with either global or localized control of the placement process. We then train reinforcement learning agents to use these controls to guide placement to improved solutions. In both cases, the augmented optimizer finds improved placement solutions. Our trained agents achieve an average 1% improvement in final detail place HPWL across a range of academic benchmarks and more than 1% in global place HPWL on real industry designs.
Modular Framework for Visuomotor Language Grounding
Sep 05, 2021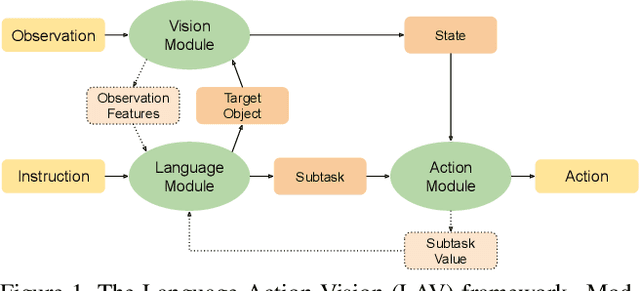
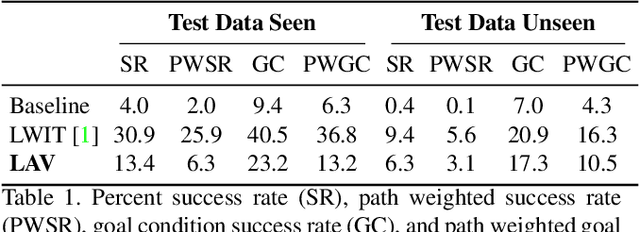
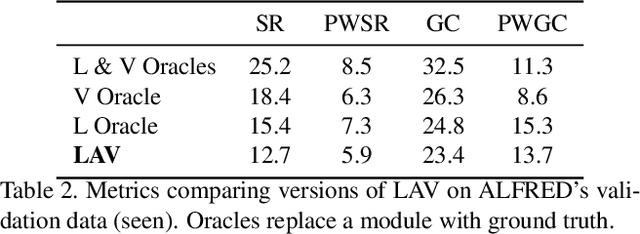
Natural language instruction following tasks serve as a valuable test-bed for grounded language and robotics research. However, data collection for these tasks is expensive and end-to-end approaches suffer from data inefficiency. We propose the structuring of language, acting, and visual tasks into separate modules that can be trained independently. Using a Language, Action, and Vision (LAV) framework removes the dependence of action and vision modules on instruction following datasets, making them more efficient to train. We also present a preliminary evaluation of LAV on the ALFRED task for visual and interactive instruction following.
Using Logical Specifications of Objectives in Multi-Objective Reinforcement Learning
Oct 03, 2019
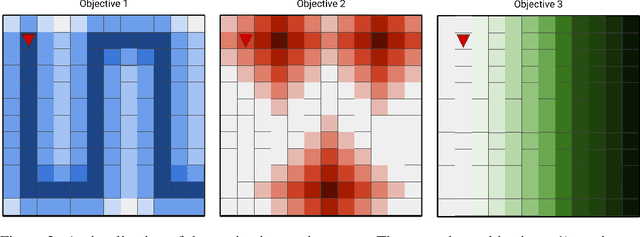

In the multi-objective reinforcement learning (MORL) paradigm, the relative importance of each environment objective is often unknown prior to training, so agents must learn to specialize their behavior to optimize different combinations of environment objectives that are specified post-training. These are typically linear combinations, so the agent is effectively parameterized by a weight vector that describes how to balance competing environment objectives. However, many real world behaviors require non-linear combinations of objectives. Additionally, the conversion between desired behavior and weightings is often unclear. In this work, we explore the use of a language based on propositional logic with quantitative semantics--in place of weight vectors--for specifying non-linear behaviors in an interpretable way. We use a recurrent encoder to encode logical combinations of objectives, and train a MORL agent to generalize over these encodings. We test our agent in several grid worlds with various objectives and show that our agent can generalize to many never-before-seen specifications with performance comparable to single policy baseline agents. We also demonstrate our agent's ability to generate meaningful policies when presented with novel specifications and quickly specialize to novel specifications.