 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Framework for Visuomotor Language Grounding
Sep 05, 2021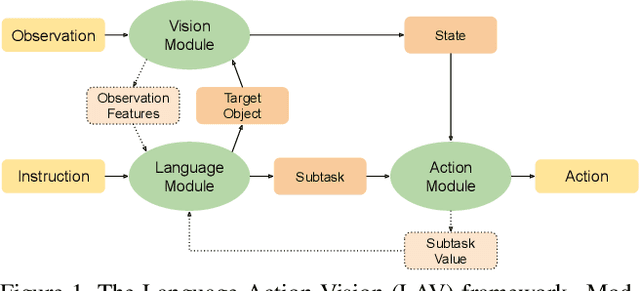
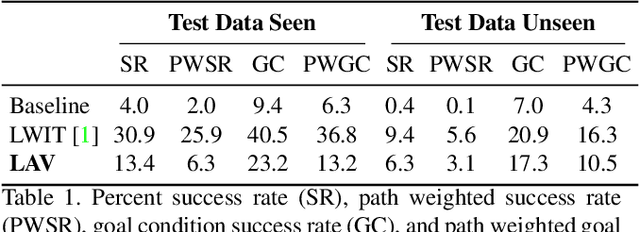
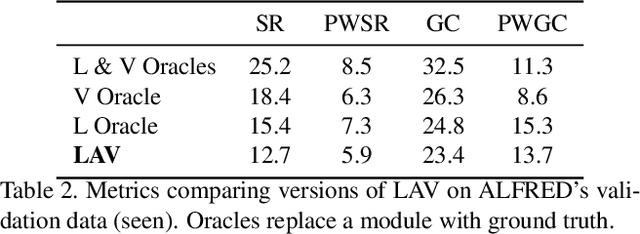
Natural language instruction following tasks serve as a valuable test-bed for grounded language and robotics research. However, data collection for these tasks is expensive and end-to-end approaches suffer from data inefficiency. We propose the structuring of language, acting, and visual tasks into separate modules that can be trained independently. Using a Language, Action, and Vision (LAV) framework removes the dependence of action and vision modules on instruction following datasets, making them more efficient to train. We also present a preliminary evaluation of LAV on the ALFRED task for visual and interactive instruction following.
Predicting Camera Viewpoint Improves Cross-dataset Generalization for 3D Human Pose Estimation
Apr 07, 2020
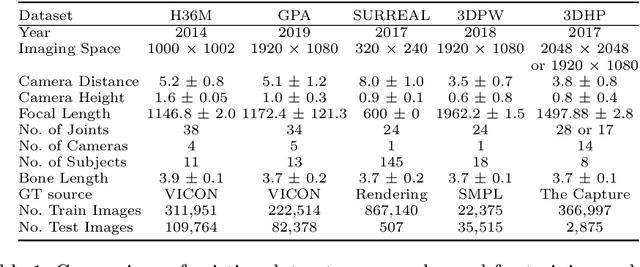
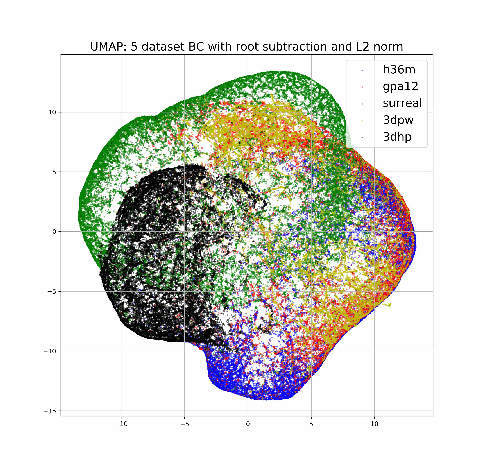
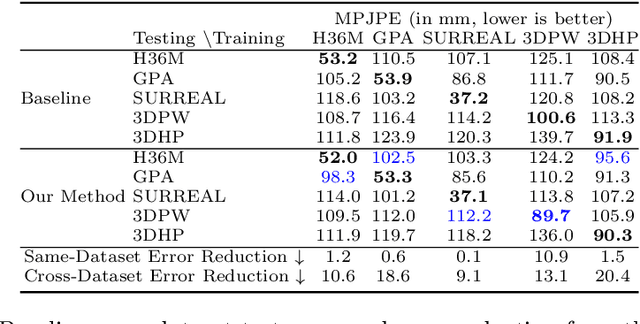
Monocular estimation of 3d human pose has attracted increased attention with the availability of large ground-truth motion capture datasets. However, the diversity of training data available is limited and it is not clear to what extent methods generalize outside the specific datasets they are trained on. In this work we carry out a systematic study of the diversity and biases present in specific datasets and its effect on cross-dataset generalization across a compendium of 5 pose datasets. We specifically focus on systematic differences in the distribution of camera viewpoints relative to a body-centered coordinate frame. Based on this observation, we propose an auxiliary task of predicting the camera viewpoint in addition to pose. We find that models trained to jointly predict viewpoint and pose systematically show significantly improved cross-dataset generalization.
Domain Decluttering: Simplifying Images to Mitigate Synthetic-Real Domain Shift and Improve Depth Estimation
Feb 27, 2020
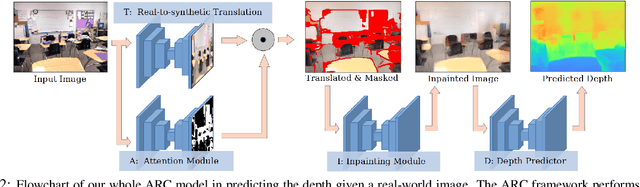
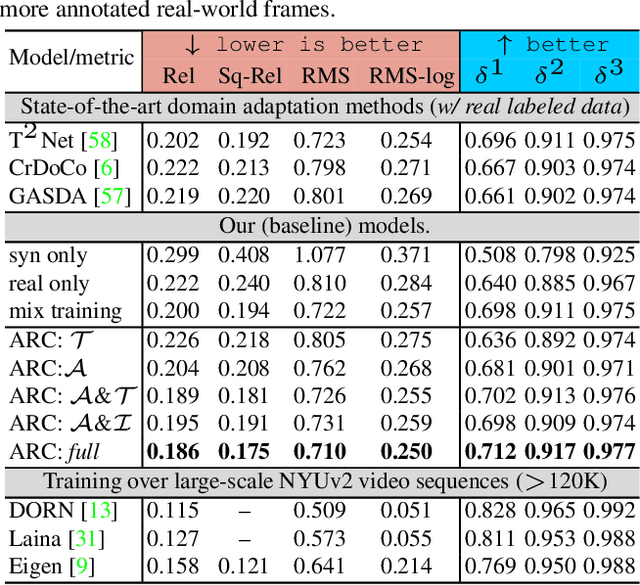
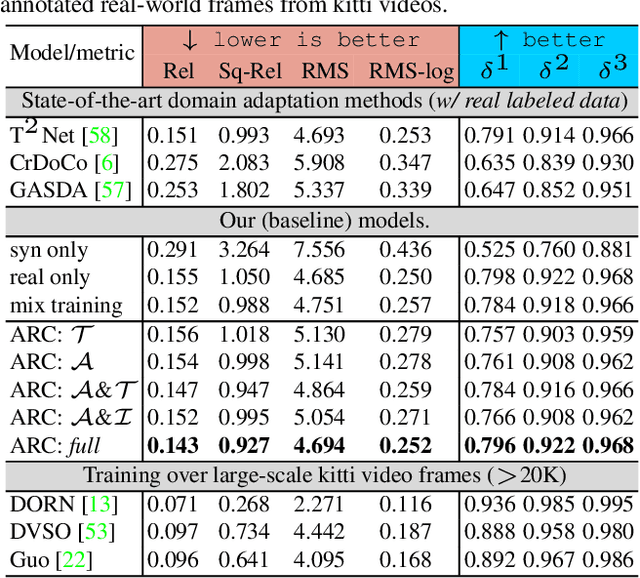
Leveraging synthetically rendered data offers great potential to improve monocular depth estimation, but closing the synthetic-real domain gap is a non-trivial and important task. While much recent work has focused on unsupervised domain adaptation, we consider a more realistic scenario where a large amount of synthetic training data is supplemented by a small set of real images with ground-truth. In this setting we find that existing domain translation approaches are difficult to train and offer little advantage over simple baselines that use a mix of real and synthetic data. A key failure mode is that real-world images contain novel objects and clutter not present in synthetic training. This high-level domain shift isn't handled by existing image translation models. Based on these observations, we develop an attentional module that learns to identify and remove (hard) out-of-domain regions in real images in order to improve depth prediction for a model trained primarily on synthetic data. We carry out extensive experiments to validate our attend-remove-complete approach (ARC) and find that it significantly outperforms state-of-the-art domain adaptation methods for depth prediction. Visualizing the removed regions provides interpretable insights into the synthetic-real domain gap.
Geometric Pose Affordance: 3D Human Pose with Scene Constraints
May 19, 2019
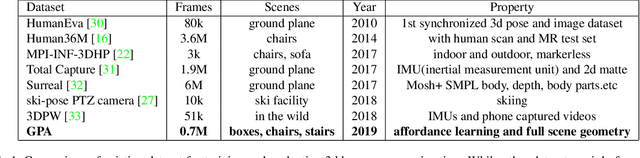
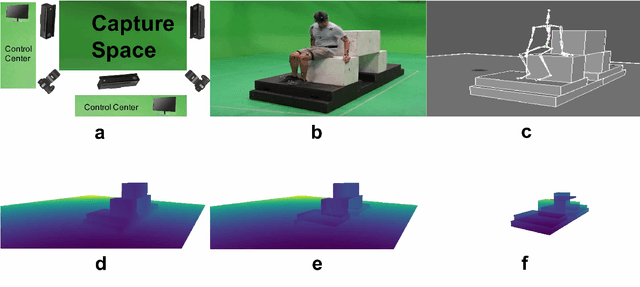
Full 3D estimation of human pose from a single image remains a challenging task despite many recent advances. In this paper, we explore the hypothesis that strong prior information about scene geometry can be used to improve pose estimation accuracy. To tackle this question empirically, we have assembled a novel $\textbf{Geometric Pose Affordance}$ dataset, consisting of multi-view imagery of people interacting with a variety of rich 3D environments. We utilized a commercial motion capture system to collect gold-standard estimates of pose and construct accurate geometric 3D CAD models of the scene itself. To inject prior knowledge of scene constraints into existing frameworks for pose estimation from images, we introduce a novel, view-based representation of scene geometry, a $\textbf{multi-layer depth map}$, which employs multi-hit ray tracing to concisely encode multiple surface entry and exit points along each camera view ray direction. We propose two different mechanisms for integrating multi-layer depth information pose estimation: input as encoded ray features used in lifting 2D pose to full 3D, and secondly as a differentiable loss that encourages learned models to favor geometrically consistent pose estimates. We show experimentally that these techniques can improve the accuracy of 3D pose estimates, particularly in the presence of occlusion and complex scene geometry.
Multi-layer Depth and Epipolar Feature Transformers for 3D Scene Reconstruction
Feb 18, 2019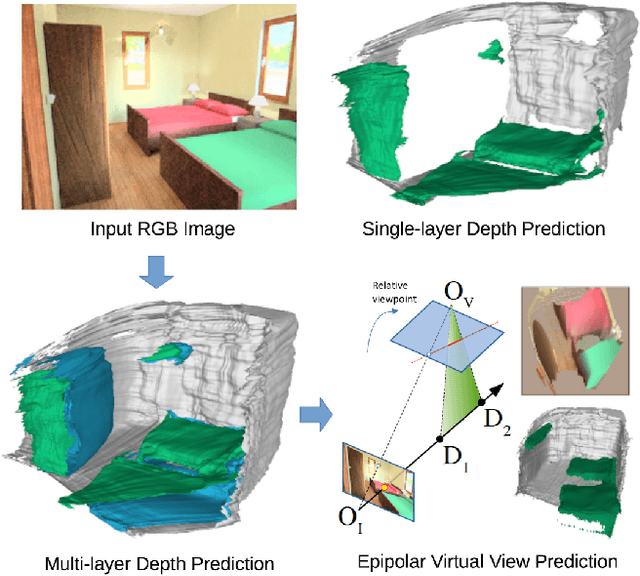
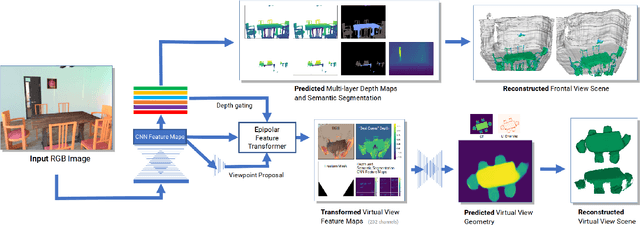

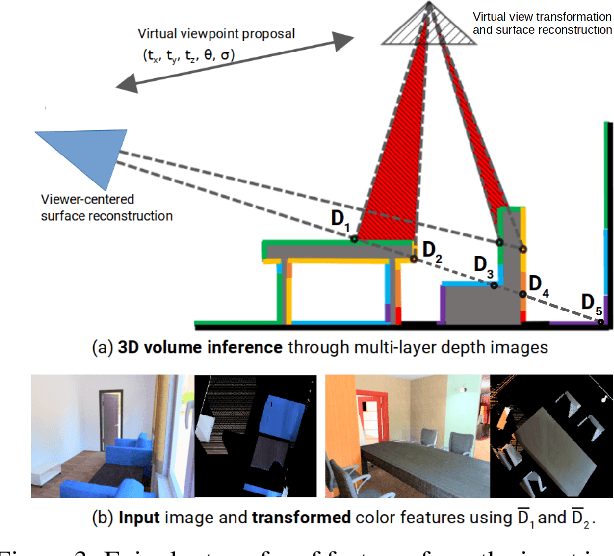
We tackle the problem of automatically reconstructing a complete 3D model of a scene from a single RGB image. This challenging task requires inferring the shape of both visible and occluded surfaces. Our approach utilizes viewer-centered, multi-layer representation of scene geometry adapted from recent methods for single object shape completion. To improve the accuracy of view-centered representations for complex scenes, we introduce a novel "Epipolar Feature Transformer" that transfers convolutional network features from an input view to other virtual camera viewpoints, and thus better covers the 3D scene geometry. Unlike existing approaches that first detect and localize objects in 3D, and then infer object shape using category-specific models, our approach is fully convolutional, end-to-end differentiable, and avoids the resolution and memory limitations of voxel representations. We demonstrate the advantages of multi-layer depth representations and epipolar feature transformers on the reconstruction of a large database of indoor scenes.
Pixels, voxels, and views: A study of shape representations for single view 3D object shape prediction
Jun 12, 2018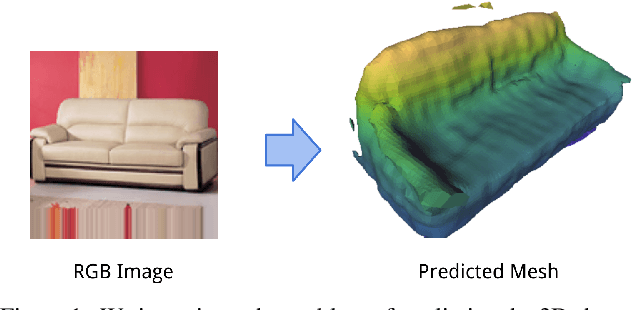


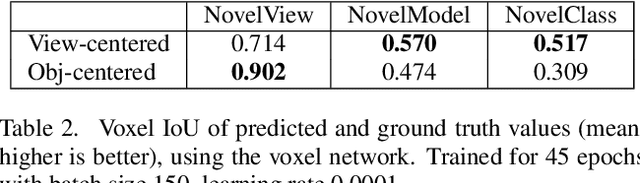
The goal of this paper is to compare surface-based and volumetric 3D object shape representations, as well as viewer-centered and object-centered reference frames for single-view 3D shape prediction. We propose a new algorithm for predicting depth maps from multiple viewpoints, with a single depth or RGB image as input. By modifying the network and the way models are evaluated, we can directly compare the merits of voxels vs. surfaces and viewer-centered vs. object-centered for familiar vs. unfamiliar objects, as predicted from RGB or depth images. Among our findings, we show that surface-based methods outperform voxel representations for objects from novel classes and produce higher resolution outputs. We also find that using viewer-centered coordinates is advantageous for novel objects, while object-centered representations are better for more familiar objects. Interestingly, the coordinate frame significantly affects the shape representation learned, with object-centered placing more importance on implicitly recognizing the object category and viewer-centered producing shape representations with less dependence on category recognition.
3DFS: Deformable Dense Depth Fusion and Segmentation for Object Reconstruction from a Handheld Camera
Jul 27, 2016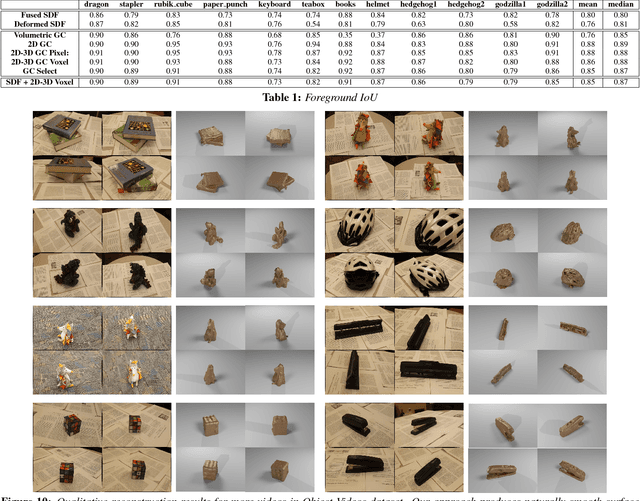
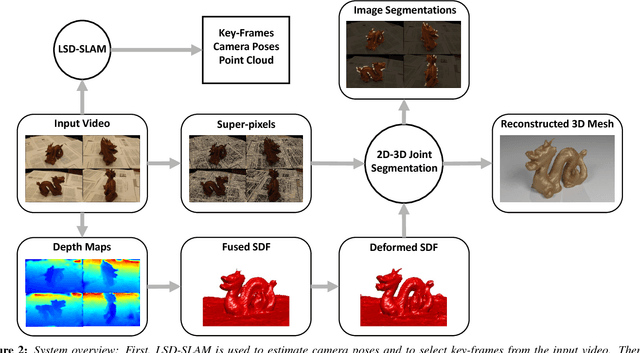
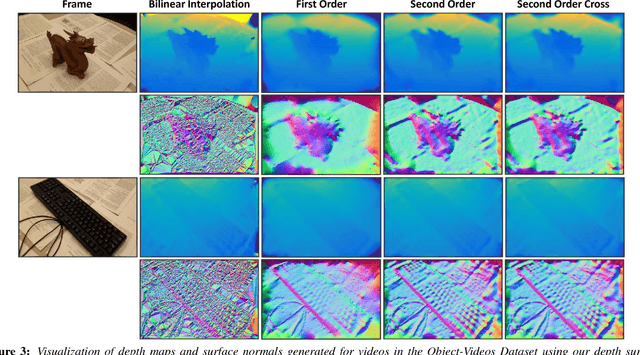
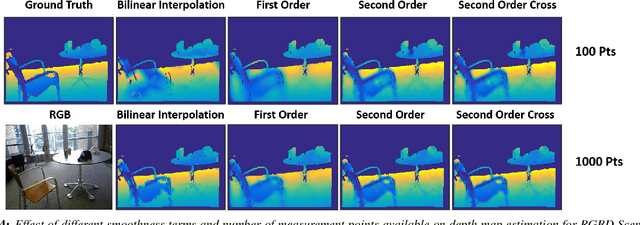
We propose an approach for 3D reconstruction and segmentation of a single object placed on a flat surface from an input video. Our approach is to perform dense depth map estimation for multiple views using a proposed objective function that preserves detail. The resulting depth maps are then fused using a proposed implicit surface function that is robust to estimation error, producing a smooth surface reconstruction of the entire scene. Finally, the object is segmented from the remaining scene using a proposed 2D-3D segmentation that incorporates image and depth cues with priors and regularization over the 3D volume and 2D segmentations. We evaluate 3D reconstructions qualitatively on our Object-Videos dataset, comparing to fusion, multiview stereo, and segmentation baselines. We also quantitatively evaluate the dense depth estimation using the RGBD Scenes V2 dataset [Henry et al. 2013] and the segmentation using keyframe annotations of the Object-Videos dataset.