 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbout Time: Model-free Reinforcement Learning with Timed Reward Machines
Dec 19, 2025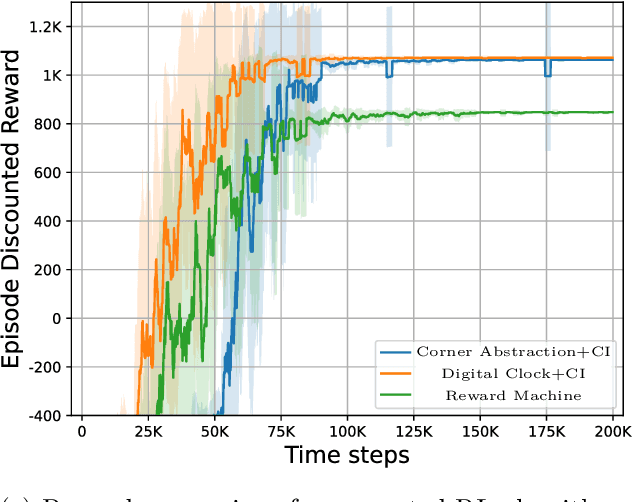
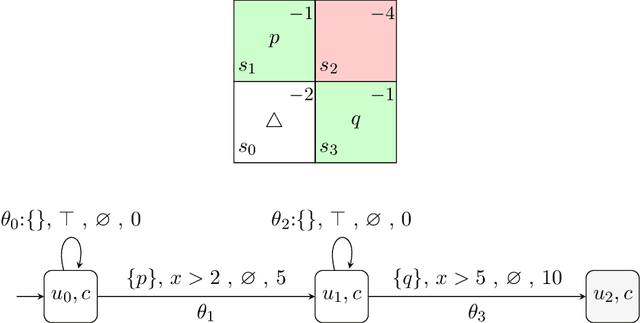

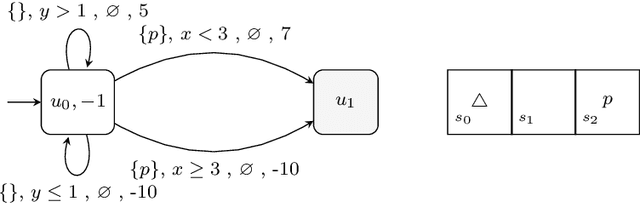
Reward specification plays a central role in reinforcement learning (RL), guiding the agent's behavior. To express non-Markovian rewards, formalisms such as reward machines have been introduced to capture dependencies on histories. However, traditional reward machines lack the ability to model precise timing constraints, limiting their use in time-sensitive applications. In this paper, we propose timed reward machines (TRMs), which are an extension of reward machines that incorporate timing constraints into the reward structure. TRMs enable more expressive specifications with tunable reward logic, for example, imposing costs for delays and granting rewards for timely actions. We study model-free RL frameworks (i.e., tabular Q-learning) for learning optimal policies with TRMs under digital and real-time semantics. Our algorithms integrate the TRM into learning via abstractions of timed automata, and employ counterfactual-imagining heuristics that exploit the structure of the TRM to improve the search. Experimentally, we demonstrate that our algorithm learns policies that achieve high rewards while satisfying the timing constraints specified by the TRM on popular RL benchmarks. Moreover, we conduct comparative studies of performance under different TRM semantics, along with ablations that highlight the benefits of counterfactual-imagining.
A Comprehensive Dataset for Human vs. AI Generated Text Detection
Oct 26, 2025
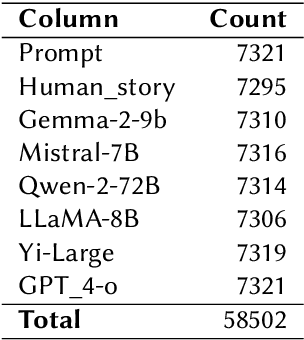
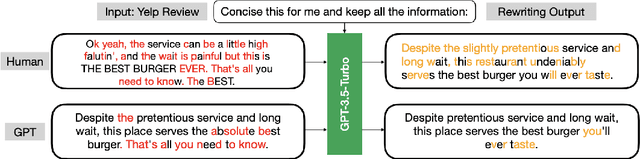

The rapid advancement of large language models (LLMs) has led to increasingly human-like AI-generated text, raising concerns about content authenticity, misinformation, and trustworthiness. Addressing the challenge of reliably detecting AI-generated text and attributing it to specific models requires large-scale, diverse, and well-annotated datasets. In this work, we present a comprehensive dataset comprising over 58,000 text samples that combine authentic New York Times articles with synthetic versions generated by multiple state-of-the-art LLMs including Gemma-2-9b, Mistral-7B, Qwen-2-72B, LLaMA-8B, Yi-Large, and GPT-4-o. The dataset provides original article abstracts as prompts, full human-authored narratives. We establish baseline results for two key tasks: distinguishing human-written from AI-generated text, achieving an accuracy of 58.35\%, and attributing AI texts to their generating models with an accuracy of 8.92\%. By bridging real-world journalistic content with modern generative models, the dataset aims to catalyze the development of robust detection and attribution methods, fostering trust and transparency in the era of generative AI. Our dataset is available at: https://huggingface.co/datasets/gsingh1-py/train.
DETONATE: A Benchmark for Text-to-Image Alignment and Kernelized Direct Preference Optimization
Jun 17, 2025Alignment is crucial for text-to-image (T2I) models to ensure that generated images faithfully capture user intent while maintaining safety and fairness. Direct Preference Optimization (DPO), prominent in large language models (LLMs), is extending its influence to T2I systems. This paper introduces DPO-Kernels for T2I models, a novel extension enhancing alignment across three dimensions: (i) Hybrid Loss, integrating embedding-based objectives with traditional probability-based loss for improved optimization; (ii) Kernelized Representations, employing Radial Basis Function (RBF), Polynomial, and Wavelet kernels for richer feature transformations and better separation between safe and unsafe inputs; and (iii) Divergence Selection, expanding beyond DPO's default Kullback-Leibler (KL) regularizer by incorporating Wasserstein and R'enyi divergences for enhanced stability and robustness. We introduce DETONATE, the first large-scale benchmark of its kind, comprising approximately 100K curated image pairs categorized as chosen and rejected. DETONATE encapsulates three axes of social bias and discrimination: Race, Gender, and Disability. Prompts are sourced from hate speech datasets, with images generated by leading T2I models including Stable Diffusion 3.5 Large, Stable Diffusion XL, and Midjourney. Additionally, we propose the Alignment Quality Index (AQI), a novel geometric measure quantifying latent-space separability of safe/unsafe image activations, revealing hidden vulnerabilities. Empirically, we demonstrate that DPO-Kernels maintain strong generalization bounds via Heavy-Tailed Self-Regularization (HT-SR). DETONATE and complete code are publicly released.
Learning Probabilistic Temporal Logic Specifications for Stochastic Systems
May 17, 2025There has been substantial progress in the inference of formal behavioural specifications from sample trajectories, for example, using Linear Temporal Logic (LTL). However, these techniques cannot handle specifications that correctly characterise systems with stochastic behaviour, which occur commonly in reinforcement learning and formal verification. We consider the passive learning problem of inferring a Boolean combination of probabilistic LTL (PLTL) formulas from a set of Markov chains, classified as either positive or negative. We propose a novel learning algorithm that infers concise PLTL specifications, leveraging grammar-based enumeration, search heuristics, probabilistic model checking and Boolean set-cover procedures. We demonstrate the effectiveness of our algorithm in two use cases: learning from policies induced by RL algorithms and learning from variants of a probabilistic model. In both cases, our method automatically and efficiently extracts PLTL specifications that succinctly characterise the temporal differences between the policies or model variants.
What is Formal Verification without Specifications? A Survey on mining LTL Specifications
Jan 27, 2025Virtually all verification techniques using formal methods rely on the availability of a formal specification, which describes the design requirements precisely. However, formulating specifications remains a manual task that is notoriously challenging and error-prone. To address this bottleneck in formal verification, recent research has thus focussed on automatically generating specifications for formal verification from examples of (desired and undesired) system behavior. In this survey, we list and compare recent advances in mining specifications in Linear Temporal Logic (LTL), the de facto standard specification language for reactive systems. Several approaches have been designed for learning LTL formulas, which address different aspects and settings of specification design. Moreover, the approaches rely on a diverse range of techniques such as constraint solving, neural network training, enumerative search, etc. We survey the current state-of-the-art techniques and compare them for the convenience of the formal methods practitioners.
DPO Kernels: A Semantically-Aware, Kernel-Enhanced, and Divergence-Rich Paradigm for Direct Preference Optimization
Jan 08, 2025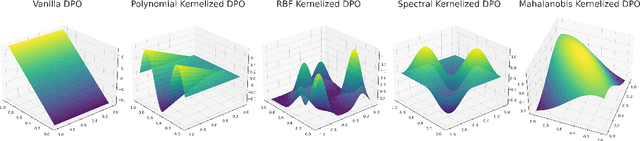


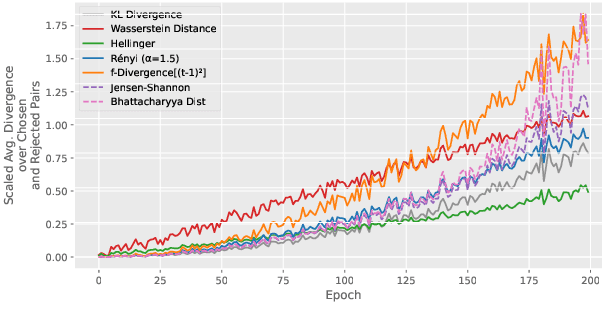
The rapid rise of large language models (LLMs) has unlocked many applications but also underscores the challenge of aligning them with diverse values and preferences. Direct Preference Optimization (DPO) is central to alignment but constrained by fixed divergences and limited feature transformations. We propose DPO-Kernels, which integrates kernel methods to address these issues through four key contributions: (i) Kernelized Representations with polynomial, RBF, Mahalanobis, and spectral kernels for richer transformations, plus a hybrid loss combining embedding-based and probability-based objectives; (ii) Divergence Alternatives (Jensen-Shannon, Hellinger, Renyi, Bhattacharyya, Wasserstein, and f-divergences) for greater stability; (iii) Data-Driven Selection metrics that automatically choose the best kernel-divergence pair; and (iv) a Hierarchical Mixture of Kernels for both local precision and global modeling. Evaluations on 12 datasets demonstrate state-of-the-art performance in factuality, safety, reasoning, and instruction following. Grounded in Heavy-Tailed Self-Regularization, DPO-Kernels maintains robust generalization for LLMs, offering a comprehensive resource for further alignment research.
Nemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
CircuitVAE: Efficient and Scalable Latent Circuit Optimization
Jun 13, 2024
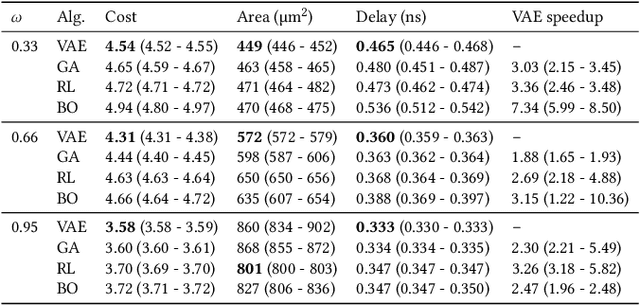
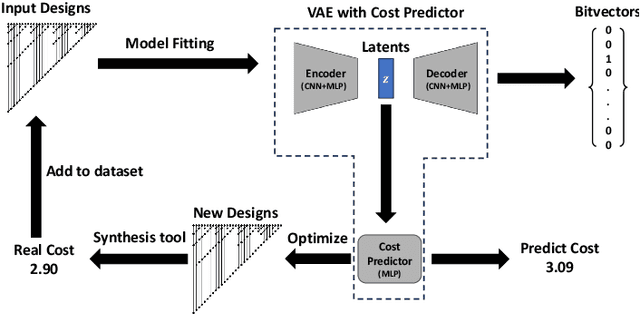
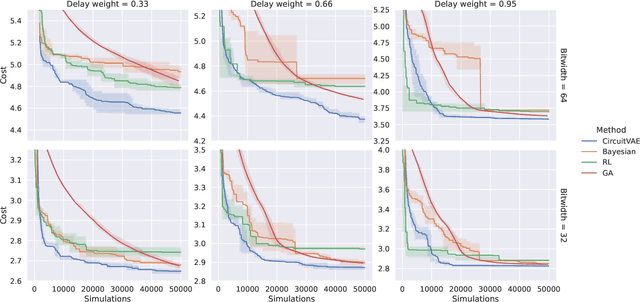
Automatically designing fast and space-efficient digital circuits is challenging because circuits are discrete, must exactly implement the desired logic, and are costly to simulate. We address these challenges with CircuitVAE, a search algorithm that embeds computation graphs in a continuous space and optimizes a learned surrogate of physical simulation by gradient descent. By carefully controlling overfitting of the simulation surrogate and ensuring diverse exploration, our algorithm is highly sample-efficient, yet gracefully scales to large problem instances and high sample budgets. We test CircuitVAE by designing binary adders across a large range of sizes, IO timing constraints, and sample budgets. Our method excels at designing large circuits, where other algorithms struggle: compared to reinforcement learning and genetic algorithms, CircuitVAE typically finds 64-bit adders which are smaller and faster using less than half the sample budget. We also find CircuitVAE can design state-of-the-art adders in a real-world chip, demonstrating that our method can outperform commercial tools in a realistic setting.
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
May 27, 2024



Decoder-only large language model (LLM)-based embedding models are beginning to outperform BERT or T5-based embedding models in general-purpose text embedding tasks, including dense vector-based retrieval. In this work, we introduce the NV-Embed model with a variety of architectural designs and training procedures to significantly enhance the performance of LLM as a versatile embedding model, while maintaining its simplicity and reproducibility. For model architecture, we propose a latent attention layer to obtain pooled embeddings, which consistently improves retrieval and downstream task accuracy compared to mean pooling or using the last <EOS> token embedding from LLMs. To enhance representation learning, we remove the causal attention mask of LLMs during contrastive training. For model training, we introduce a two-stage contrastive instruction-tuning method. It first applies contrastive training with instructions on retrieval datasets, utilizing in-batch negatives and curated hard negative examples. At stage-2, it blends various non-retrieval datasets into instruction tuning, which not only enhances non-retrieval task accuracy but also improves retrieval performance. Combining these techniques, our NV-Embed model, using only publicly available data, has achieved a record-high score of 69.32, ranking No. 1 on the Massive Text Embedding Benchmark (MTEB) (as of May 24, 2024), with 56 tasks, encompassing retrieval, reranking, classification, clustering, and semantic textual similarity tasks. Notably, our model also attains the highest score of 59.36 on 15 retrieval tasks in the MTEB benchmark (also known as BEIR). We will open-source the model at: https://huggingface.co/nvidia/NV-Embed-v1.
A High-Fidelity Simulation Framework for Grasping Stability Analysis in Human Casualty Manipulation
Apr 04, 2024



Recently, there has been a growing interest in rescue robots due to their vital role in addressing emergency scenarios and providing crucial support in challenging or hazardous situations where human intervention is difficult. However, very few of these robots are capable of actively engaging with humans and undertaking physical manipulation tasks. This limitation is largely attributed to the absence of tools that can realistically simulate physical interactions, especially the contact mechanisms between a robotic gripper and a human body. In this letter, we aim to address key limitations in current developments towards robotic casualty manipulation. Firstly, we present an integrative simulation framework for casualty manipulation. We adapt a finite element method (FEM) tool into the grasping and manipulation scenario, and the developed framework can provide accurate biomechanical reactions resulting from manipulation. Secondly, we conduct a detailed assessment of grasping stability during casualty grasping and manipulation simulations. To validate the necessity and superior performance of the proposed high-fidelity simulation framework, we conducted a qualitative and quantitative comparison of grasping stability analyses between the proposed framework and the state-of-the-art multi-body physics simulations. Through these efforts, we have taken the first step towards a feasible solution for robotic casualty manipulation.