 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
Nemotron-4 15B Technical Report
Feb 27, 2024



We introduce Nemotron-4 15B, a 15-billion-parameter large multilingual language model trained on 8 trillion text tokens. Nemotron-4 15B demonstrates strong performance when assessed on English, multilingual, and coding tasks: it outperforms all existing similarly-sized open models on 4 out of 7 downstream evaluation areas and achieves competitive performance to the leading open models in the remaining ones. Specifically, Nemotron-4 15B exhibits the best multilingual capabilities of all similarly-sized models, even outperforming models over four times larger and those explicitly specialized for multilingual tasks.
nach0: Multimodal Natural and Chemical Languages Foundation Model
Nov 21, 2023



Large Language Models (LLMs) have substantially driven scientific progress in various domains, and many papers have demonstrated their ability to tackle complex problems with creative solutions. Our paper introduces a new foundation model, nach0, capable of solving various chemical and biological tasks: biomedical question answering, named entity recognition, molecular generation, molecular synthesis, attributes prediction, and others. nach0 is a multi-domain and multi-task encoder-decoder LLM pre-trained on unlabeled text from scientific literature, patents, and molecule strings to incorporate a range of chemical and linguistic knowledge. We employed instruction tuning, where specific task-related instructions are utilized to fine-tune nach0 for the final set of tasks. To train nach0 effectively, we leverage the NeMo framework, enabling efficient parallel optimization of both base and large model versions. Extensive experiments demonstrate that our model outperforms state-of-the-art baselines on single-domain and cross-domain tasks. Furthermore, it can generate high-quality outputs in molecular and textual formats, showcasing its effectiveness in multi-domain setups.
Stereo Video Reconstruction Without Explicit Depth Maps for Endoscopic Surgery
Sep 16, 2021
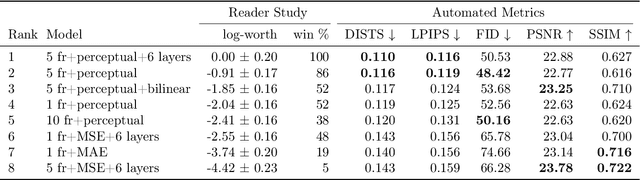

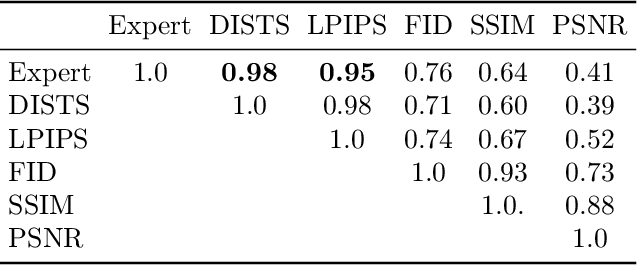
We introduce the task of stereo video reconstruction or, equivalently, 2D-to-3D video conversion for minimally invasive surgical video. We design and implement a series of end-to-end U-Net-based solutions for this task by varying the input (single frame vs. multiple consecutive frames), loss function (MSE, MAE, or perceptual losses), and network architecture. We evaluate these solutions by surveying ten experts - surgeons who routinely perform endoscopic surgery. We run two separate reader studies: one evaluating individual frames and the other evaluating fully reconstructed 3D video played on a VR headset. In the first reader study, a variant of the U-Net that takes as input multiple consecutive video frames and outputs the missing view performs best. We draw two conclusions from this outcome. First, motion information coming from multiple past frames is crucial in recreating stereo vision. Second, the proposed U-Net variant can indeed exploit such motion information for solving this task. The result from the second study further confirms the effectiveness of the proposed U-Net variant. The surgeons reported that they could successfully perceive depth from the reconstructed 3D video clips. They also expressed a clear preference for the reconstructed 3D video over the original 2D video. These two reader studies strongly support the usefulness of the proposed task of stereo reconstruction for minimally invasive surgical video and indicate that deep learning is a promising approach to this task. Finally, we identify two automatic metrics, LPIPS and DISTS, that are strongly correlated with expert judgement and that could serve as proxies for the latter in future studies.