 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereo Video Reconstruction Without Explicit Depth Maps for Endoscopic Surgery
Paper and Code
Sep 16, 2021
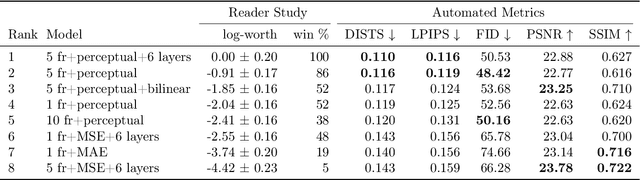

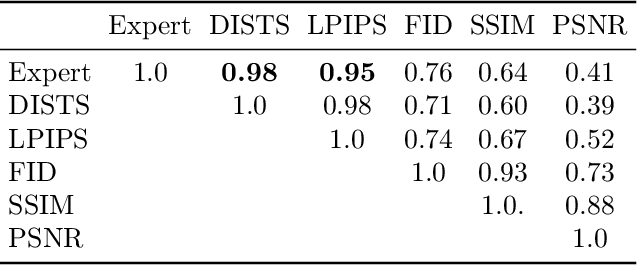
We introduce the task of stereo video reconstruction or, equivalently, 2D-to-3D video conversion for minimally invasive surgical video. We design and implement a series of end-to-end U-Net-based solutions for this task by varying the input (single frame vs. multiple consecutive frames), loss function (MSE, MAE, or perceptual losses), and network architecture. We evaluate these solutions by surveying ten experts - surgeons who routinely perform endoscopic surgery. We run two separate reader studies: one evaluating individual frames and the other evaluating fully reconstructed 3D video played on a VR headset. In the first reader study, a variant of the U-Net that takes as input multiple consecutive video frames and outputs the missing view performs best. We draw two conclusions from this outcome. First, motion information coming from multiple past frames is crucial in recreating stereo vision. Second, the proposed U-Net variant can indeed exploit such motion information for solving this task. The result from the second study further confirms the effectiveness of the proposed U-Net variant. The surgeons reported that they could successfully perceive depth from the reconstructed 3D video clips. They also expressed a clear preference for the reconstructed 3D video over the original 2D video. These two reader studies strongly support the usefulness of the proposed task of stereo reconstruction for minimally invasive surgical video and indicate that deep learning is a promising approach to this task. Finally, we identify two automatic metrics, LPIPS and DISTS, that are strongly correlated with expert judgement and that could serve as proxies for the latter in future studies.