 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Multi-omic Biosequence Transformers for Modeling Peptide-Nucleotide Interactions
Aug 29, 2024



The transformer architecture has revolutionized bioinformatics and driven progress in the understanding and prediction of the properties of biomolecules. Almost all research on large-scale biosequence transformers has focused on one domain at a time (single-omic), usually nucleotides or peptides. These models have seen incredible success in downstream tasks in each domain and have achieved particularly noteworthy breakthroughs in sequences of peptides and structural modeling. However, these single-omic models are naturally incapable of modeling multi-omic tasks, one of the most biologically critical being nucleotide-peptide interactions. We present our work training the first multi-omic nucleotide-peptide foundation models. We show that these multi-omic models (MOMs) can learn joint representations between various single-omic distributions that are emergently consistent with the Central Dogma of molecular biology, despite only being trained on unlabeled biosequences. We further demonstrate that MOMs can be fine-tuned to achieve state-of-the-art results on peptide-nucleotide interaction tasks, namely predicting the change in Gibbs free energy ({\Delta}G) of the binding interaction between a given oligonucleotide and peptide, as well as the effect on this binding interaction due to mutations in the oligonucleotide sequence ({\Delta}{\Delta}G). Remarkably, we show that multi-omic biosequence transformers emergently learn useful structural information without any prior structural training, allowing us to predict which peptide residues are most involved in the peptide-nucleotide binding interaction. Lastly, we provide evidence that multi-omic biosequence models are non-inferior to foundation models trained on single-omics distributions, suggesting a more generalized or foundational approach to building these models.
Stereo Video Reconstruction Without Explicit Depth Maps for Endoscopic Surgery
Sep 16, 2021
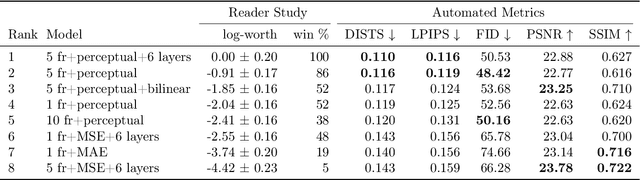

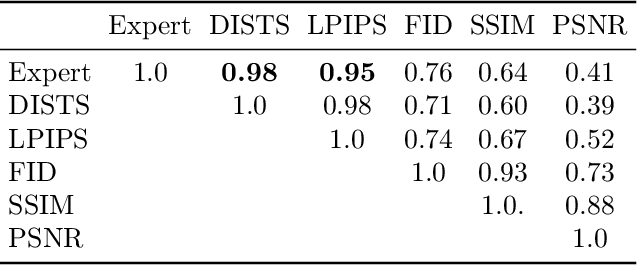
We introduce the task of stereo video reconstruction or, equivalently, 2D-to-3D video conversion for minimally invasive surgical video. We design and implement a series of end-to-end U-Net-based solutions for this task by varying the input (single frame vs. multiple consecutive frames), loss function (MSE, MAE, or perceptual losses), and network architecture. We evaluate these solutions by surveying ten experts - surgeons who routinely perform endoscopic surgery. We run two separate reader studies: one evaluating individual frames and the other evaluating fully reconstructed 3D video played on a VR headset. In the first reader study, a variant of the U-Net that takes as input multiple consecutive video frames and outputs the missing view performs best. We draw two conclusions from this outcome. First, motion information coming from multiple past frames is crucial in recreating stereo vision. Second, the proposed U-Net variant can indeed exploit such motion information for solving this task. The result from the second study further confirms the effectiveness of the proposed U-Net variant. The surgeons reported that they could successfully perceive depth from the reconstructed 3D video clips. They also expressed a clear preference for the reconstructed 3D video over the original 2D video. These two reader studies strongly support the usefulness of the proposed task of stereo reconstruction for minimally invasive surgical video and indicate that deep learning is a promising approach to this task. Finally, we identify two automatic metrics, LPIPS and DISTS, that are strongly correlated with expert judgement and that could serve as proxies for the latter in future studies.
The Utility of General Domain Transfer Learning for Medical Language Tasks
Feb 16, 2020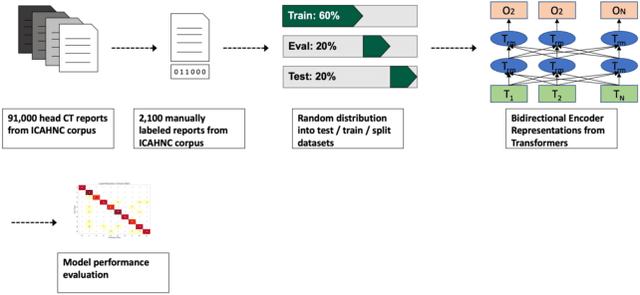
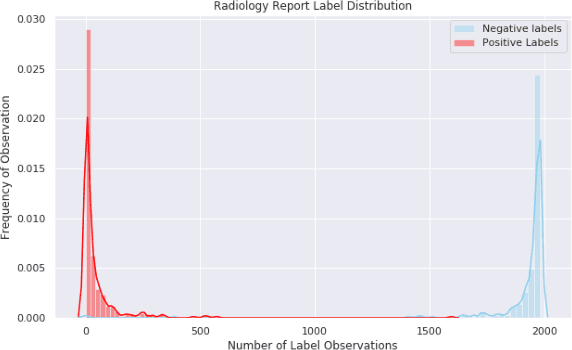
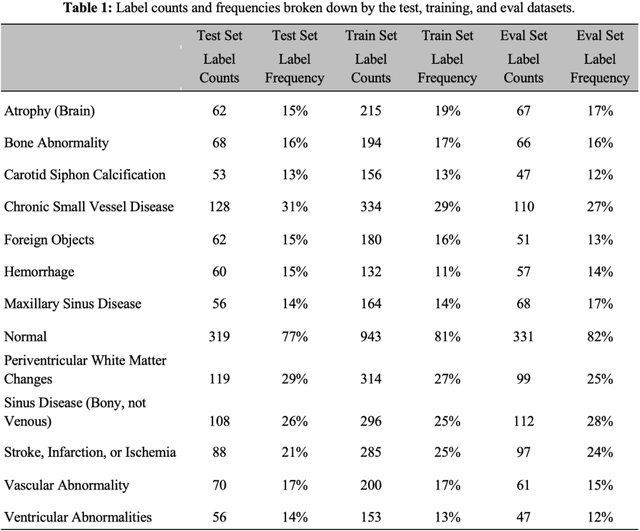
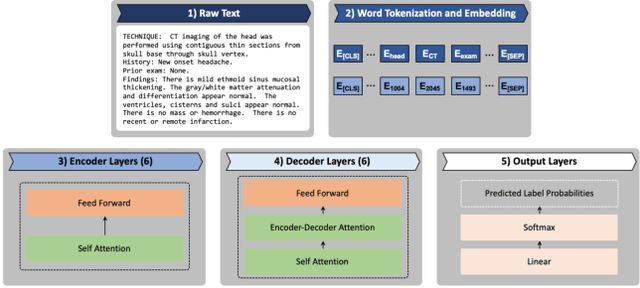
The purpose of this study is to analyze the efficacy of transfer learning techniques and transformer-based models as applied to medical natural language processing (NLP) tasks, specifically radiological text classification. We used 1,977 labeled head CT reports, from a corpus of 96,303 total reports, to evaluate the efficacy of pretraining using general domain corpora and a combined general and medical domain corpus with a bidirectional representations from transformers (BERT) model for the purpose of radiological text classification. Model performance was benchmarked to a logistic regression using bag-of-words vectorization and a long short-term memory (LSTM) multi-label multi-class classification model, and compared to the published literature in medical text classification. The BERT models using either set of pretrained checkpoints outperformed the logistic regression model, achieving sample-weighted average F1-scores of 0.87 and 0.87 for the general domain model and the combined general and biomedical-domain model. General text transfer learning may be a viable technique to generate state-of-the-art results within medical NLP tasks on radiological corpora, outperforming other deep models such as LSTMs. The efficacy of pretraining and transformer-based models could serve to facilitate the creation of groundbreaking NLP models in the uniquely challenging data environment of medical text.
Wide and deep volumetric residual networks for volumetric image classification
Sep 18, 2017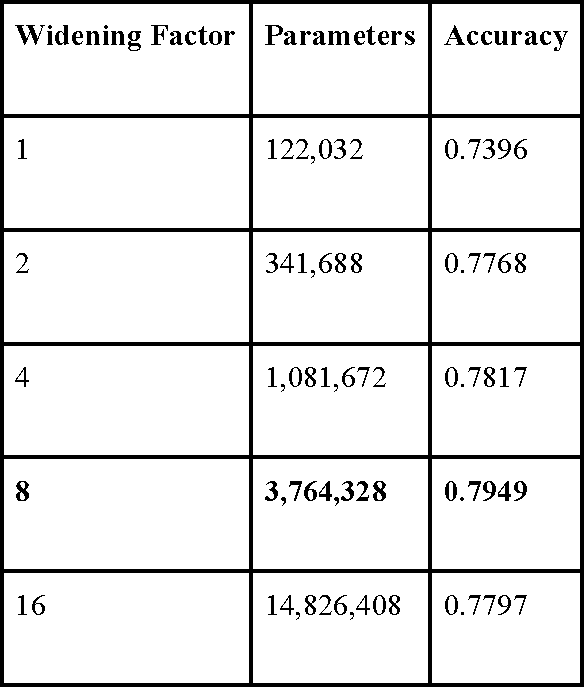
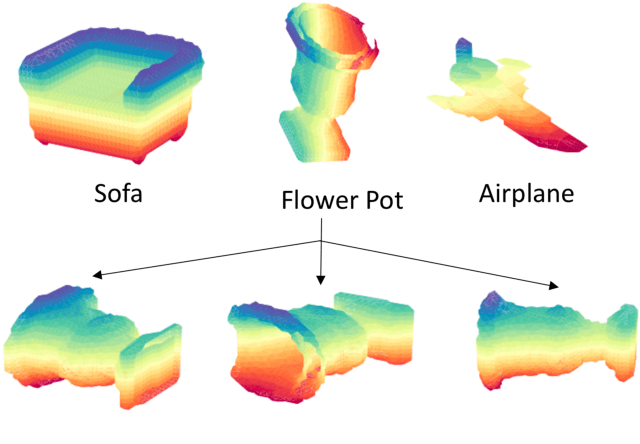

3D shape models that directly classify objects from 3D information have become more widely implementable. Current state of the art models rely on deep convolutional and inception models that are resource intensive. Residual neural networks have been demonstrated to be easier to optimize and do not suffer from vanishing/exploding gradients observed in deep networks. Here we implement a residual neural network for 3D object classification of the 3D Princeton ModelNet dataset. Further, we show that widening network layers dramatically improves accuracy in shallow residual nets, and residual neural networks perform comparable to state-of-the-art 3D shape net models, and we show that widening network layers improves classification accuracy. We provide extensive training and architecture parameters providing a better understanding of available network architectures for use in 3D object classification.