 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroscaling Data Formats for Deep Learning
Oct 19, 2023



Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
FP8 Formats for Deep Learning
Sep 12, 2022
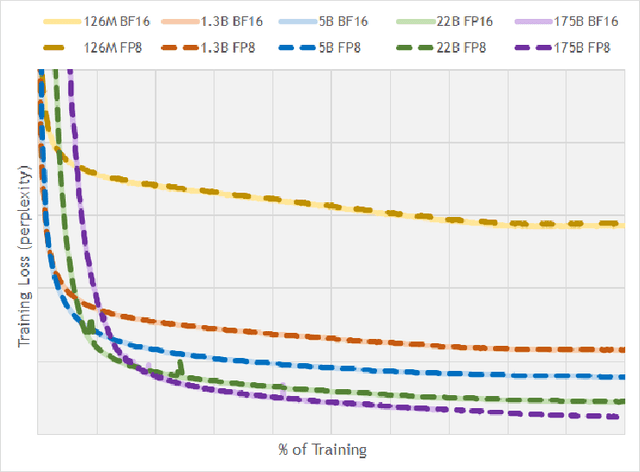
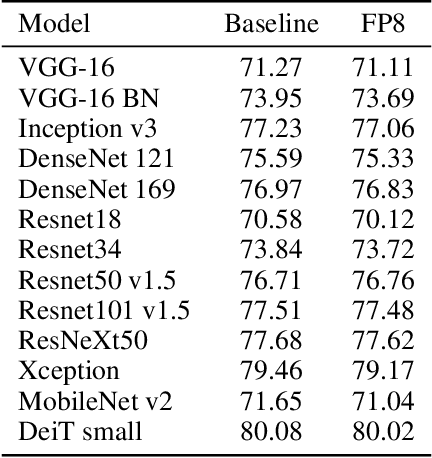
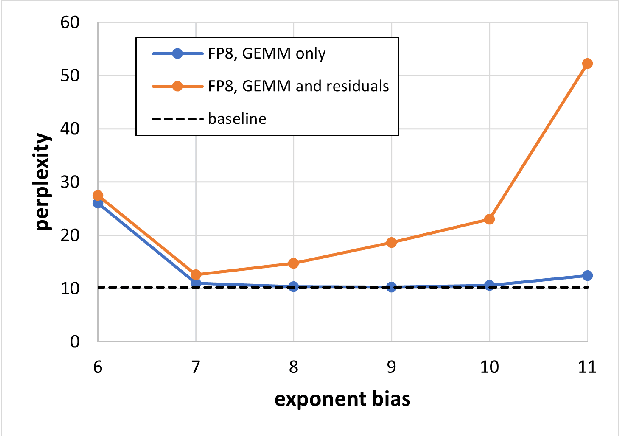
FP8 is a natural progression for accelerating deep learning training inference beyond the 16-bit formats common in modern processors. In this paper we propose an 8-bit floating point (FP8) binary interchange format consisting of two encodings - E4M3 (4-bit exponent and 3-bit mantissa) and E5M2 (5-bit exponent and 2-bit mantissa). While E5M2 follows IEEE 754 conventions for representatio of special values, E4M3's dynamic range is extended by not representing infinities and having only one mantissa bit-pattern for NaNs. We demonstrate the efficacy of the FP8 format on a variety of image and language tasks, effectively matching the result quality achieved by 16-bit training sessions. Our study covers the main modern neural network architectures - CNNs, RNNs, and Transformer-based models, leaving all the hyperparameters unchanged from the 16-bit baseline training sessions. Our training experiments include large, up to 175B parameter, language models. We also examine FP8 post-training-quantization of language models trained using 16-bit formats that resisted fixed point int8 quantization.
PrefixRL: Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning
May 14, 2022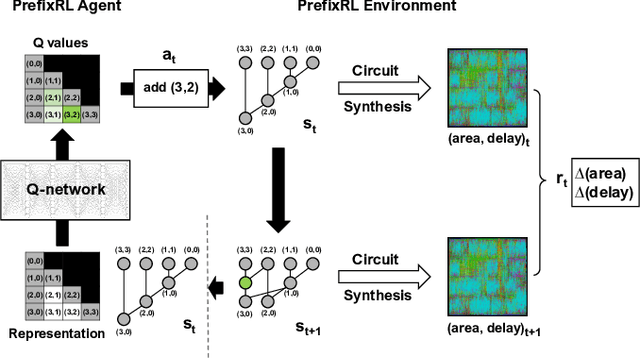
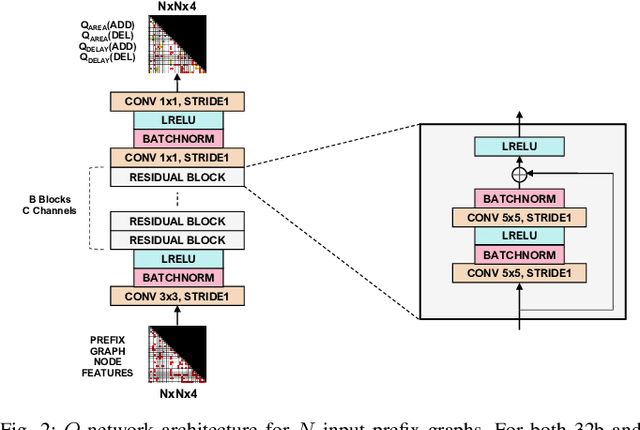
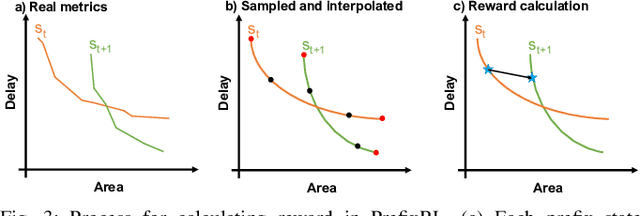
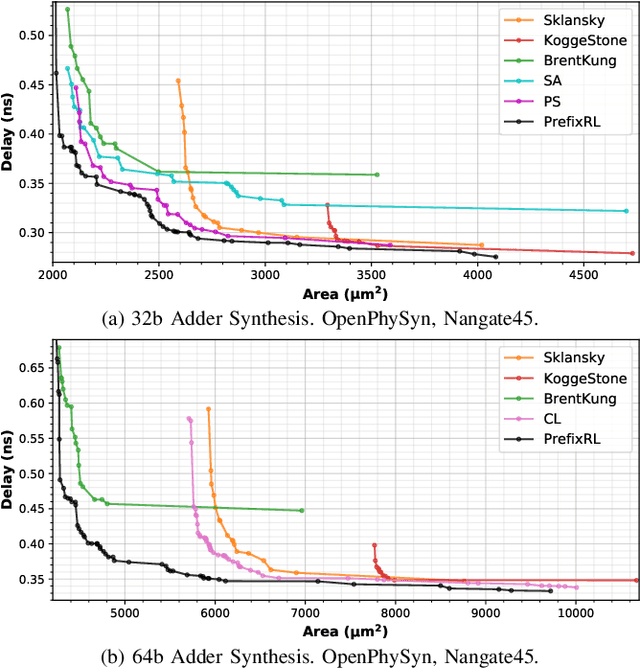
In this work, we present a reinforcement learning (RL) based approach to designing parallel prefix circuits such as adders or priority encoders that are fundamental to high-performance digital design. Unlike prior methods, our approach designs solutions tabula rasa purely through learning with synthesis in the loop. We design a grid-based state-action representation and an RL environment for constructing legal prefix circuits. Deep Convolutional RL agents trained on this environment produce prefix adder circuits that Pareto-dominate existing baselines with up to 16.0% and 30.2% lower area for the same delay in the 32b and 64b settings respectively. We observe that agents trained with open-source synthesis tools and cell library can design adder circuits that achieve lower area and delay than commercial tool adders in an industrial cell library.
* Copyright 2021 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works