 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Maps in Language Models: A Mechanistic Analysis of Spatial Planning
Nov 17, 2025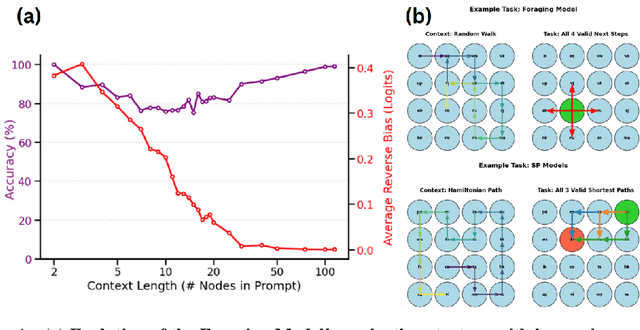

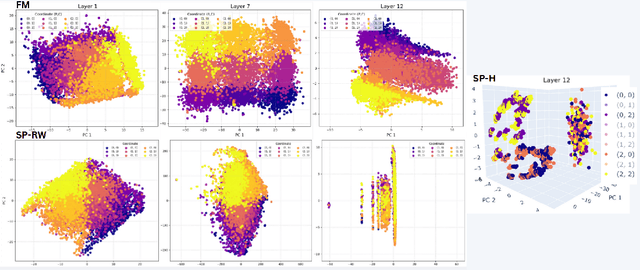
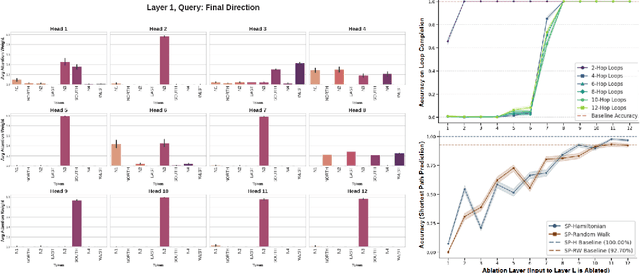
How do large language models solve spatial navigation tasks? We investigate this by training GPT-2 models on three spatial learning paradigms in grid environments: passive exploration (Foraging Model- predicting steps in random walks), goal-directed planning (generating optimal shortest paths) on structured Hamiltonian paths (SP-Hamiltonian), and a hybrid model fine-tuned with exploratory data (SP-Random Walk). Using behavioural, representational and mechanistic analyses, we uncover two fundamentally different learned algorithms. The Foraging model develops a robust, map-like representation of space, akin to a 'cognitive map'. Causal interventions reveal that it learns to consolidate spatial information into a self-sufficient coordinate system, evidenced by a sharp phase transition where its reliance on historical direction tokens vanishes by the middle layers of the network. The model also adopts an adaptive, hierarchical reasoning system, switching between a low-level heuristic for short contexts and map-based inference for longer ones. In contrast, the goal-directed models learn a path-dependent algorithm, remaining reliant on explicit directional inputs throughout all layers. The hybrid model, despite demonstrating improved generalisation over its parent, retains the same path-dependent strategy. These findings suggest that the nature of spatial intelligence in transformers may lie on a spectrum, ranging from generalisable world models shaped by exploratory data to heuristics optimised for goal-directed tasks. We provide a mechanistic account of this generalisation-optimisation trade-off and highlight how the choice of training regime influences the strategies that emerge.
Successor-Predecessor Intrinsic Exploration
May 24, 2023Exploration is essential in reinforcement learning, particularly in environments where external rewards are sparse. Here we focus on exploration with intrinsic rewards, where the agent transiently augments the external rewards with self-generated intrinsic rewards. Although the study of intrinsic rewards has a long history, existing methods focus on composing the intrinsic reward based on measures of future prospects of states, ignoring the information contained in the retrospective structure of transition sequences. Here we argue that the agent can utilise retrospective information to generate explorative behaviour with structure-awareness, facilitating efficient exploration based on global instead of local information. We propose Successor-Predecessor Intrinsic Exploration (SPIE), an exploration algorithm based on a novel intrinsic reward combining prospective and retrospective information. We show that SPIE yields more efficient and ethologically plausible exploratory behaviour in environments with sparse rewards and bottleneck states than competing methods. We also implement SPIE in deep reinforcement learning agents, and show that the resulting agent achieves stronger empirical performance than existing methods on sparse-reward Atari games.
FP8 Formats for Deep Learning
Sep 12, 2022
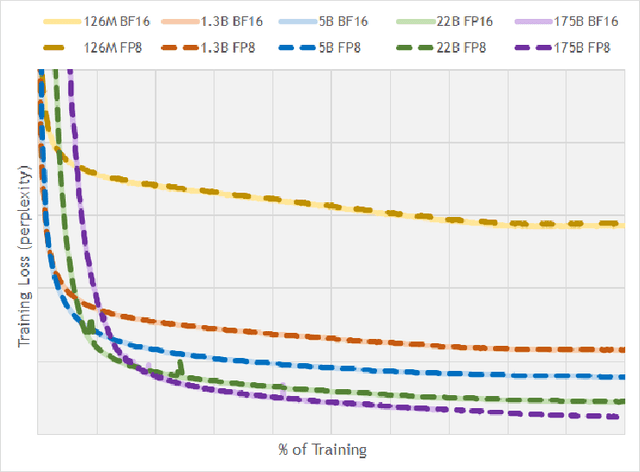
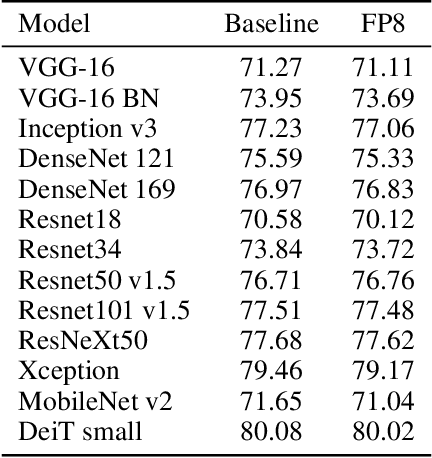
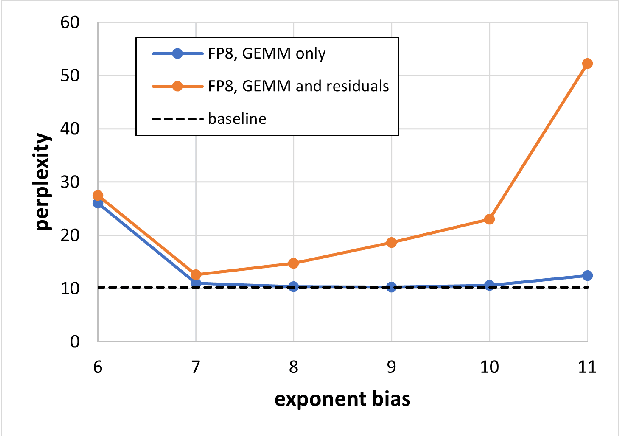
FP8 is a natural progression for accelerating deep learning training inference beyond the 16-bit formats common in modern processors. In this paper we propose an 8-bit floating point (FP8) binary interchange format consisting of two encodings - E4M3 (4-bit exponent and 3-bit mantissa) and E5M2 (5-bit exponent and 2-bit mantissa). While E5M2 follows IEEE 754 conventions for representatio of special values, E4M3's dynamic range is extended by not representing infinities and having only one mantissa bit-pattern for NaNs. We demonstrate the efficacy of the FP8 format on a variety of image and language tasks, effectively matching the result quality achieved by 16-bit training sessions. Our study covers the main modern neural network architectures - CNNs, RNNs, and Transformer-based models, leaving all the hyperparameters unchanged from the 16-bit baseline training sessions. Our training experiments include large, up to 175B parameter, language models. We also examine FP8 post-training-quantization of language models trained using 16-bit formats that resisted fixed point int8 quantization.
Amortised Inference in Structured Generative Models with Explaining Away
Sep 12, 2022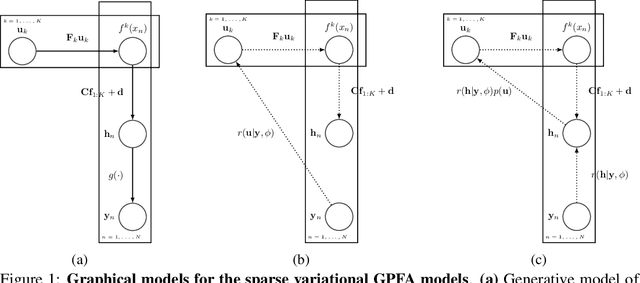
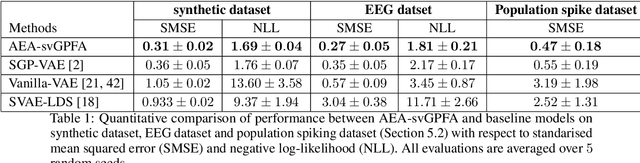
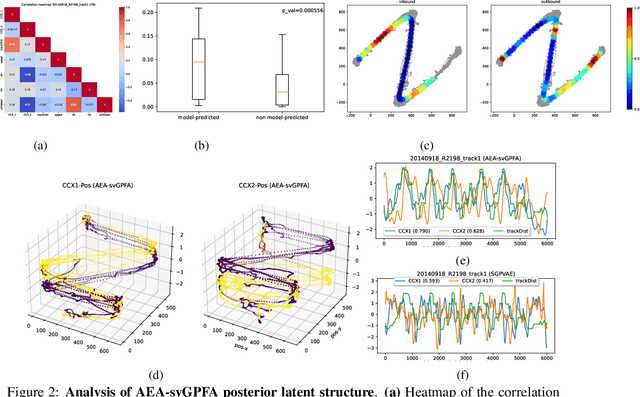
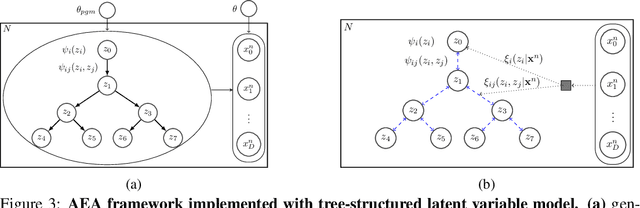
A key goal of unsupervised learning is to go beyond density estimation and sample generation to reveal the structure inherent within observed data. Such structure can be expressed in the pattern of interactions between explanatory latent variables captured through a probabilistic graphical model. Although the learning of structured graphical models has a long history, much recent work in unsupervised modelling has instead emphasised flexible deep-network-based generation, either transforming independent latent generators to model complex data or assuming that distinct observed variables are derived from different latent nodes. Here, we extend the output of amortised variational inference to incorporate structured factors over multiple variables, able to capture the observation-induced posterior dependence between latents that results from "explaining away" and thus allow complex observations to depend on multiple nodes of a structured graph. We show that appropriately parameterised factors can be combined efficiently with variational message passing in elaborate graphical structures. We instantiate the framework based on Gaussian Process Factor Analysis models, and empirically evaluate its improvement over existing methods on synthetic data with known generative processes. We then fit the structured model to high-dimensional neural spiking time-series from the hippocampus of freely moving rodents, demonstrating that the model identifies latent signals that correlate with behavioural covariates.
SEREN: Knowing When to Explore and When to Exploit
May 30, 2022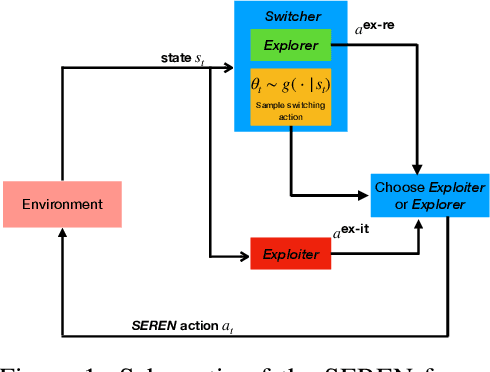
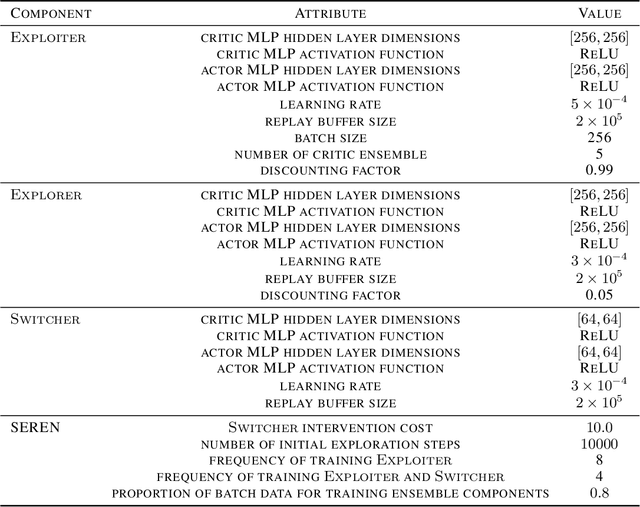
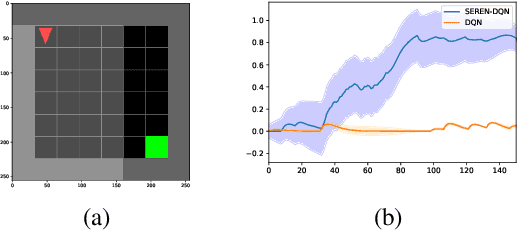
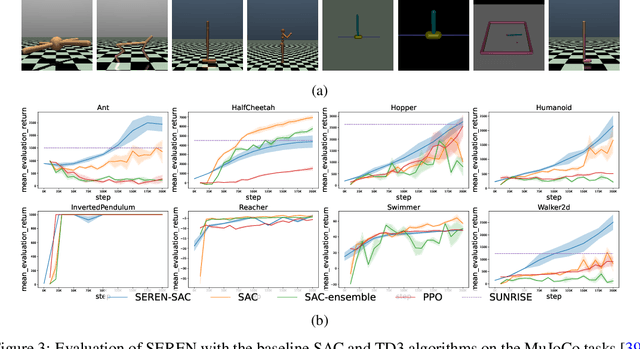
Efficient reinforcement learning (RL) involves a trade-off between "exploitative" actions that maximise expected reward and "explorative'" ones that sample unvisited states. To encourage exploration, recent approaches proposed adding stochasticity to actions, separating exploration and exploitation phases, or equating reduction in uncertainty with reward. However, these techniques do not necessarily offer entirely systematic approaches making this trade-off. Here we introduce SElective Reinforcement Exploration Network (SEREN) that poses the exploration-exploitation trade-off as a game between an RL agent -- \exploiter, which purely exploits known rewards, and another RL agent -- \switcher, which chooses at which states to activate a pure exploration policy that is trained to minimise system uncertainty and override Exploiter. Using a form of policies known as impulse control, \switcher is able to determine the best set of states to switch to the exploration policy while Exploiter is free to execute its actions everywhere else. We prove that SEREN converges quickly and induces a natural schedule towards pure exploitation. Through extensive empirical studies in both discrete (MiniGrid) and continuous (MuJoCo) control benchmarks, we show that SEREN can be readily combined with existing RL algorithms to yield significant improvement in performance relative to state-of-the-art algorithms.
Learning State Representations via Retracing in Reinforcement Learning
Nov 24, 2021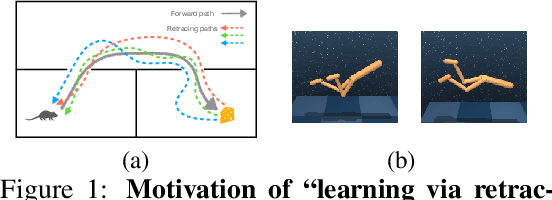
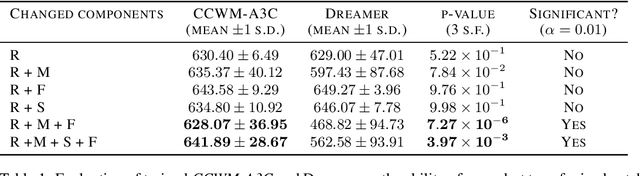
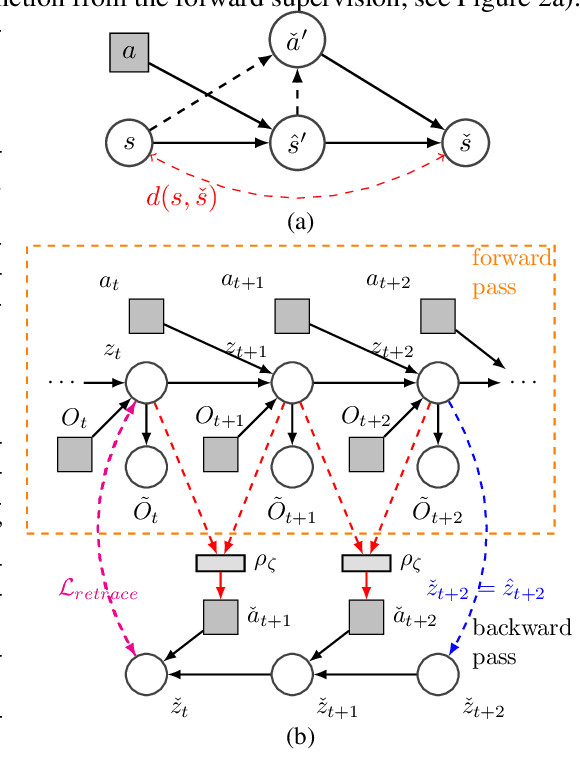
We propose learning via retracing, a novel self-supervised approach for learning the state representation (and the associated dynamics model) for reinforcement learning tasks. In addition to the predictive (reconstruction) supervision in the forward direction, we propose to include `"retraced" transitions for representation/model learning, by enforcing the cycle-consistency constraint between the original and retraced states, hence improve upon the sample efficiency of learning. Moreover, learning via retracing explicitly propagates information about future transitions backward for inferring previous states, thus facilitates stronger representation learning. We introduce Cycle-Consistency World Model (CCWM), a concrete instantiation of learning via retracing implemented under existing model-based reinforcement learning framework. Additionally we propose a novel adaptive "truncation" mechanism for counteracting the negative impacts brought by the "irreversible" transitions such that learning via retracing can be maximally effective. Through extensive empirical studies on continuous control benchmarks, we demonstrates that CCWM achieves state-of-the-art performance in terms of sample efficiency and asymptotic performance.
Prediction with directed transitions: complex eigenstructure, grid cells and phase coding
Jun 05, 2020
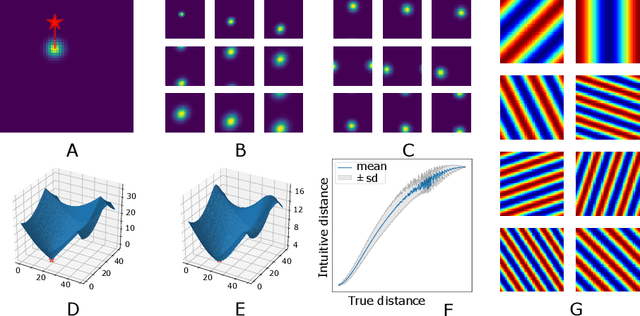
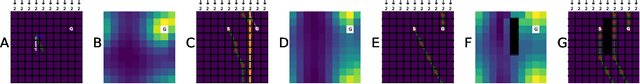
Markovian tasks can be characterised by a state space and a transition matrix. In mammals, the firing of populations of place or grid cells in the hippocampal formation are thought to represent the probability distribution over state space. Grid firing patterns are suggested to be eigenvectors of a transition matrix reflecting diffusion across states, allowing simple prediction of future state distributions, by replacing matrix multiplication with elementwise multiplication by eigenvalues. Here we extend this analysis to any translation-invariant directed transition structure (displacement and diffusion), showing that a single set of eigenvectors supports prediction via displacement-specific eigenvalues. This unifies the prediction framework with traditional models of grid cells firing driven by self-motion to perform path integration. We show that the complex eigenstructure of directed transitions corresponds to the Discrete Fourier Transform, the eigenvalues encode displacement via the Fourier Shift Theorem, and the Fourier components are analogous to "velocity-controlled oscillators" in oscillatory interference models. The resulting model supports computationally efficient prediction with directed transitions in spatial and non-spatial tasks and provides an explanation for theta phase precession and path integration in grid cell firing. We also discuss the efficient generalisation of our approach to deal with local changes in transition structure and its contribution to behavioural policy via a "sense of direction" corresponding to prediction of the effects of fixed ratios of actions.
Probabilistic Successor Representations with Kalman Temporal Differences
Oct 06, 2019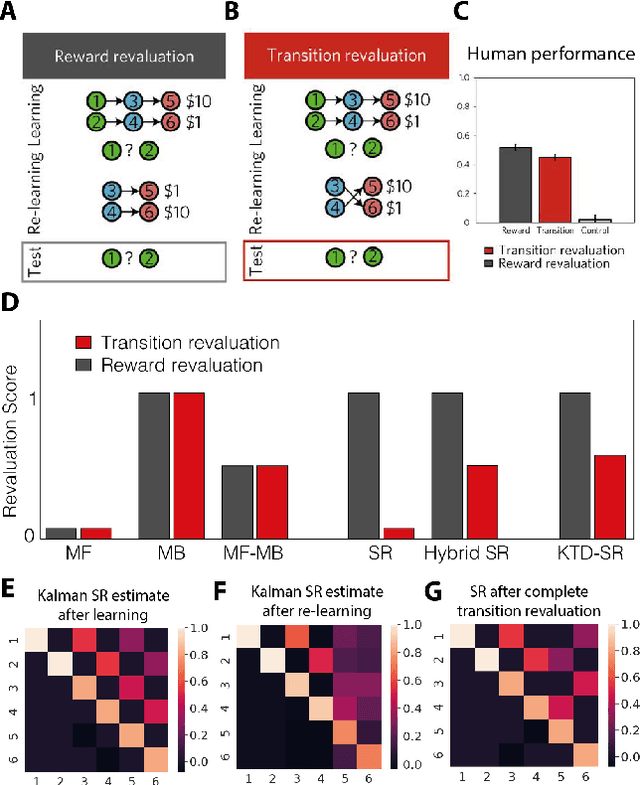
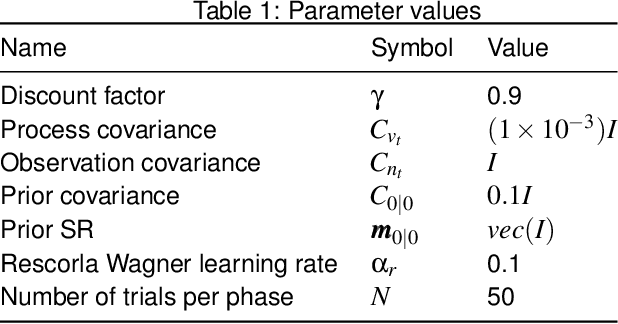
The effectiveness of Reinforcement Learning (RL) depends on an animal's ability to assign credit for rewards to the appropriate preceding stimuli. One aspect of understanding the neural underpinnings of this process involves understanding what sorts of stimulus representations support generalisation. The Successor Representation (SR), which enforces generalisation over states that predict similar outcomes, has become an increasingly popular model in this space of inquiries. Another dimension of credit assignment involves understanding how animals handle uncertainty about learned associations, using probabilistic methods such as Kalman Temporal Differences (KTD). Combining these approaches, we propose using KTD to estimate a distribution over the SR. KTD-SR captures uncertainty about the estimated SR as well as covariances between different long-term predictions. We show that because of this, KTD-SR exhibits partial transition revaluation as humans do in this experiment without additional replay, unlike the standard TD-SR algorithm. We conclude by discussing future applications of the KTD-SR as a model of the interaction between predictive and probabilistic animal reasoning.