 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Q-learning For Antibody Design
Sep 13, 2022
Optimizing combinatorial structures is core to many real-world problems, such as those encountered in life sciences. For example, one of the crucial steps involved in antibody design is to find an arrangement of amino acids in a protein sequence that improves its binding with a pathogen. Combinatorial optimization of antibodies is difficult due to extremely large search spaces and non-linear objectives. Even for modest antibody design problems, where proteins have a sequence length of eleven, we are faced with searching over 2.05 x 10^14 structures. Applying traditional Reinforcement Learning algorithms such as Q-learning to combinatorial optimization results in poor performance. We propose Structured Q-learning (SQL), an extension of Q-learning that incorporates structural priors for combinatorial optimization. Using a molecular docking simulator, we demonstrate that SQL finds high binding energy sequences and performs favourably against baselines on eight challenging antibody design tasks, including designing antibodies for SARS-COV.
Enhancing Safe Exploration Using Safety State Augmentation
Jun 06, 2022
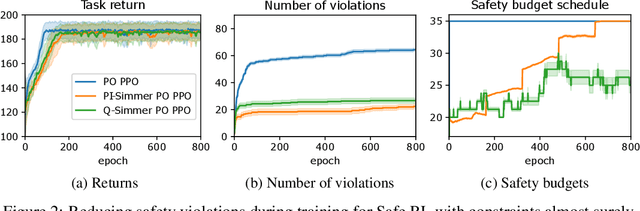
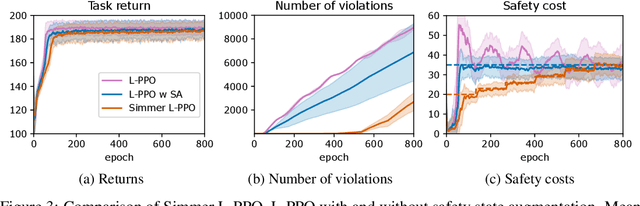
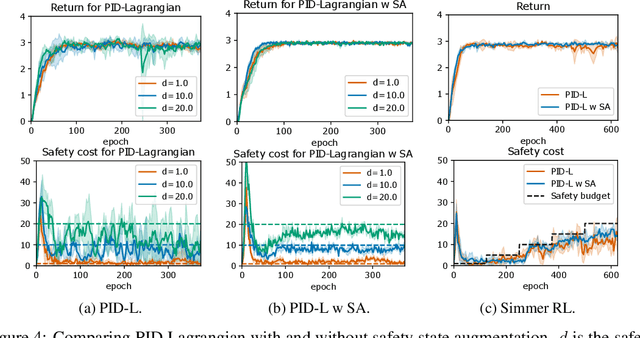
Safe exploration is a challenging and important problem in model-free reinforcement learning (RL). Often the safety cost is sparse and unknown, which unavoidably leads to constraint violations -- a phenomenon ideally to be avoided in safety-critical applications. We tackle this problem by augmenting the state-space with a safety state, which is nonnegative if and only if the constraint is satisfied. The value of this state also serves as a distance toward constraint violation, while its initial value indicates the available safety budget. This idea allows us to derive policies for scheduling the safety budget during training. We call our approach Simmer (Safe policy IMproveMEnt for RL) to reflect the careful nature of these schedules. We apply this idea to two safe RL problems: RL with constraints imposed on an average cost, and RL with constraints imposed on a cost with probability one. Our experiments suggest that simmering a safe algorithm can improve safety during training for both settings. We further show that Simmer can stabilize training and improve the performance of safe RL with average constraints.
Timing is Everything: Learning to Act Selectively with Costly Actions and Budgetary Constraints
Jun 06, 2022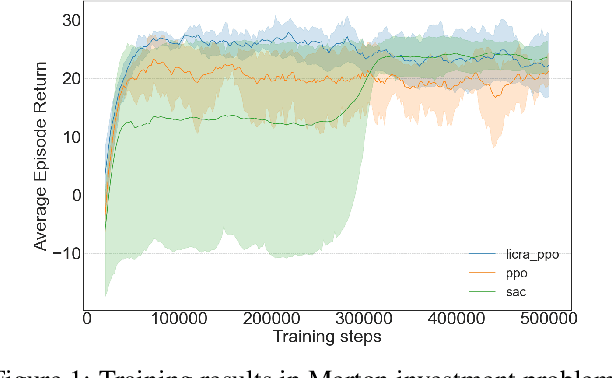
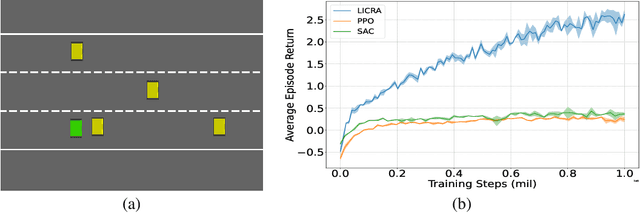
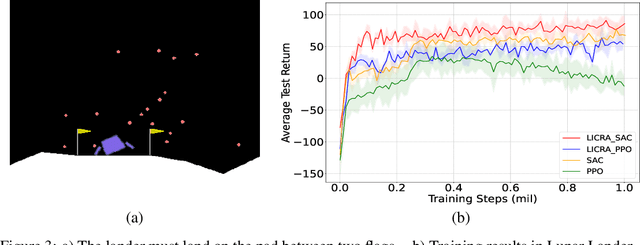
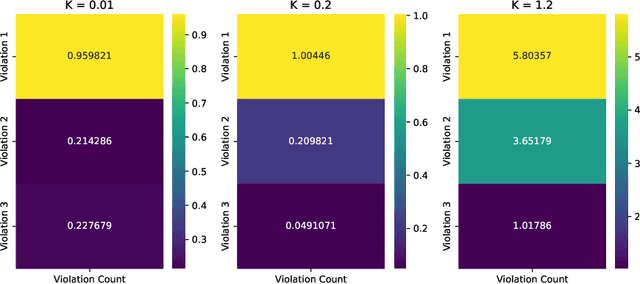
Many real-world settings involve costs for performing actions; transaction costs in financial systems and fuel costs being common examples. In these settings, performing actions at each time step quickly accumulates costs leading to vastly suboptimal outcomes. Additionally, repeatedly acting produces wear and tear and ultimately, damage. Determining when to act is crucial for achieving successful outcomes and yet, the challenge of efficiently learning to behave optimally when actions incur minimally bounded costs remains unresolved. In this paper, we introduce a reinforcement learning (RL) framework named Learnable Impulse Control Reinforcement Algorithm (LICRA), for learning to optimally select both when to act and which actions to take when actions incur costs. At the core of LICRA is a nested structure that combines RL and a form of policy known as impulse control which learns to maximise objectives when actions incur costs. We prove that LICRA, which seamlessly adopts any RL method, converges to policies that optimally select when to perform actions and their optimal magnitudes. We then augment LICRA to handle problems in which the agent can perform at most $k<\infty$ actions and more generally, faces a budget constraint. We show LICRA learns the optimal value function and ensures budget constraints are satisfied almost surely. We demonstrate empirically LICRA's superior performance against benchmark RL methods in OpenAI gym's Lunar Lander and in Highway environments and a variant of the Merton portfolio problem within finance.
SEREN: Knowing When to Explore and When to Exploit
May 30, 2022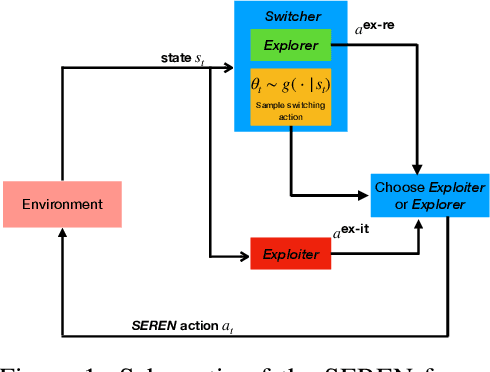
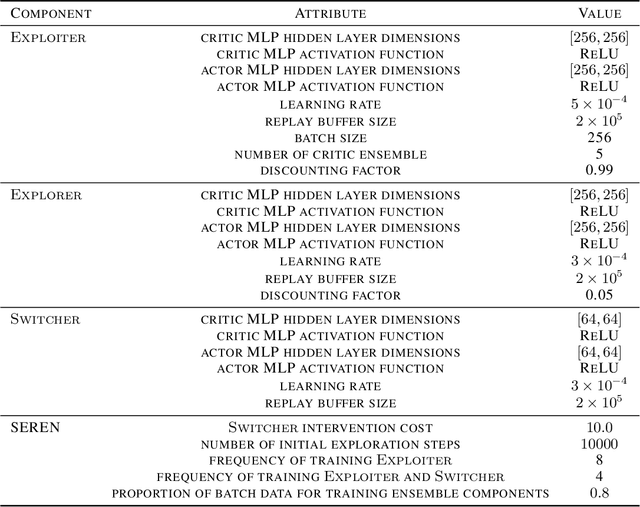
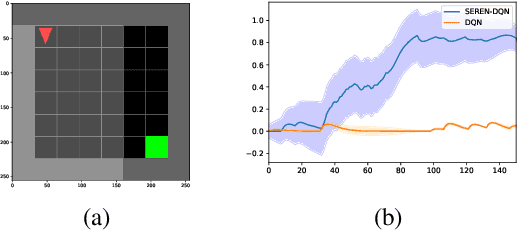
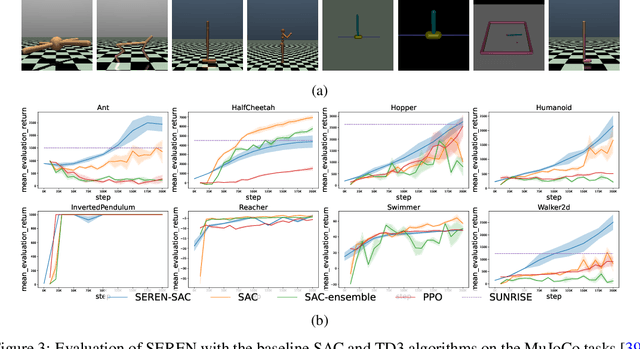
Efficient reinforcement learning (RL) involves a trade-off between "exploitative" actions that maximise expected reward and "explorative'" ones that sample unvisited states. To encourage exploration, recent approaches proposed adding stochasticity to actions, separating exploration and exploitation phases, or equating reduction in uncertainty with reward. However, these techniques do not necessarily offer entirely systematic approaches making this trade-off. Here we introduce SElective Reinforcement Exploration Network (SEREN) that poses the exploration-exploitation trade-off as a game between an RL agent -- \exploiter, which purely exploits known rewards, and another RL agent -- \switcher, which chooses at which states to activate a pure exploration policy that is trained to minimise system uncertainty and override Exploiter. Using a form of policies known as impulse control, \switcher is able to determine the best set of states to switch to the exploration policy while Exploiter is free to execute its actions everywhere else. We prove that SEREN converges quickly and induces a natural schedule towards pure exploitation. Through extensive empirical studies in both discrete (MiniGrid) and continuous (MuJoCo) control benchmarks, we show that SEREN can be readily combined with existing RL algorithms to yield significant improvement in performance relative to state-of-the-art algorithms.
SAUTE RL: Almost Surely Safe Reinforcement Learning Using State Augmentation
Feb 16, 2022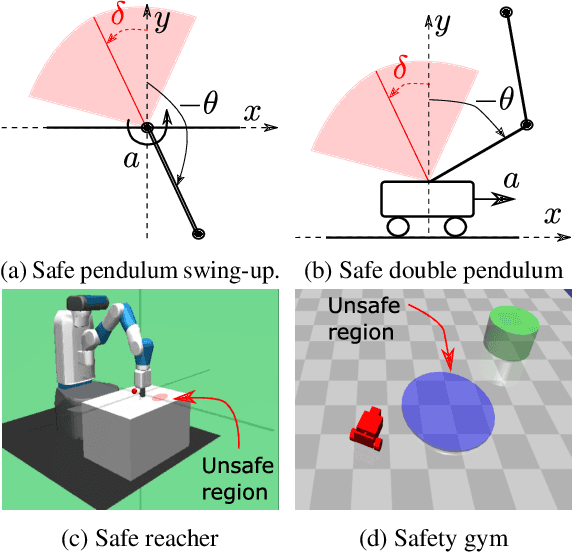
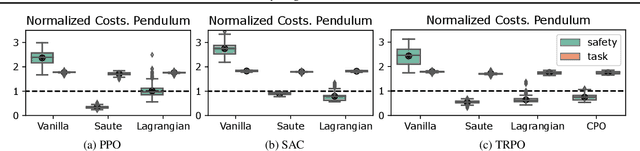
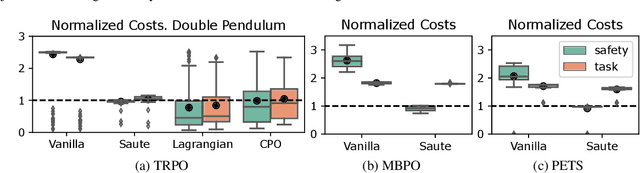
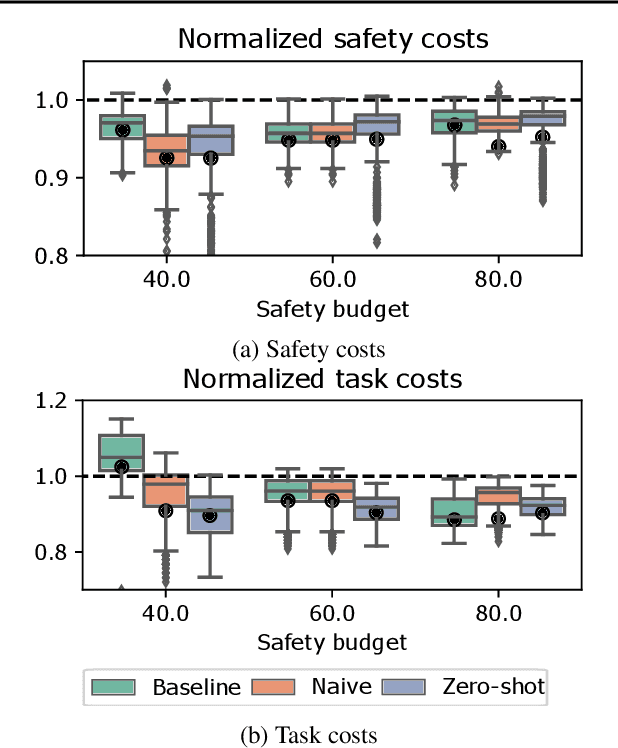
Satisfying safety constraints almost surely (or with probability one) can be critical for deployment of Reinforcement Learning (RL) in real-life applications. For example, plane landing and take-off should ideally occur with probability one. We address the problem by introducing Safety Augmented (Saute) Markov Decision Processes (MDPs), where the safety constraints are eliminated by augmenting them into the state-space and reshaping the objective. We show that Saute MDP satisfies the Bellman equation and moves us closer to solving Safe RL with constraints satisfied almost surely. We argue that Saute MDP allows to view Safe RL problem from a different perspective enabling new features. For instance, our approach has a plug-and-play nature, i.e., any RL algorithm can be "sauteed". Additionally, state augmentation allows for policy generalization across safety constraints. We finally show that Saute RL algorithms can outperform their state-of-the-art counterparts when constraint satisfaction is of high importance.
Reinforcement Learning in Presence of Discrete Markovian Context Evolution
Feb 14, 2022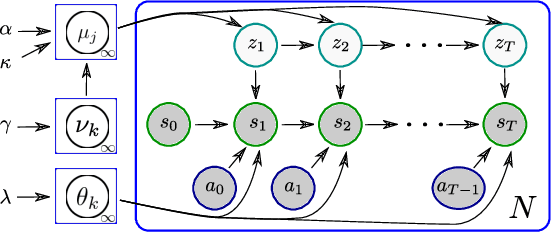
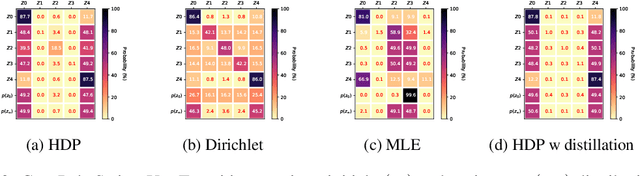
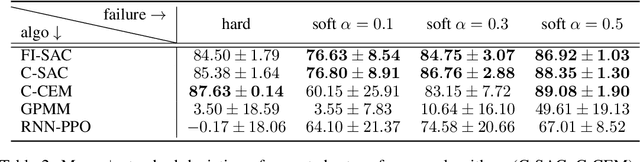
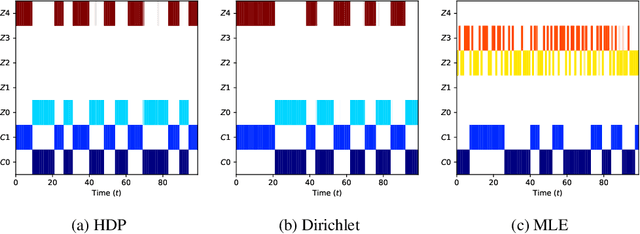
We consider a context-dependent Reinforcement Learning (RL) setting, which is characterized by: a) an unknown finite number of not directly observable contexts; b) abrupt (discontinuous) context changes occurring during an episode; and c) Markovian context evolution. We argue that this challenging case is often met in applications and we tackle it using a Bayesian approach and variational inference. We adapt a sticky Hierarchical Dirichlet Process (HDP) prior for model learning, which is arguably best-suited for Markov process modeling. We then derive a context distillation procedure, which identifies and removes spurious contexts in an unsupervised fashion. We argue that the combination of these two components allows to infer the number of contexts from data thus dealing with the context cardinality assumption. We then find the representation of the optimal policy enabling efficient policy learning using off-the-shelf RL algorithms. Finally, we demonstrate empirically (using gym environments cart-pole swing-up, drone, intersection) that our approach succeeds where state-of-the-art methods of other frameworks fail and elaborate on the reasons for such failures.
DESTA: A Framework for Safe Reinforcement Learning with Markov Games of Intervention
Oct 27, 2021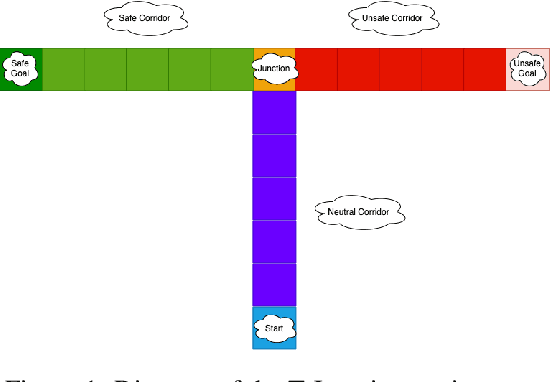
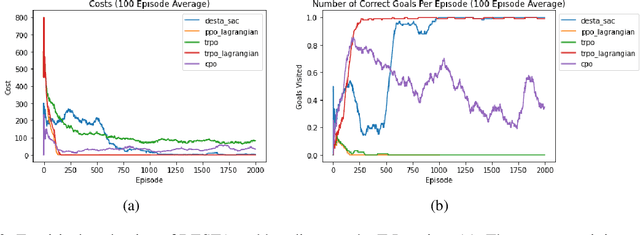

Exploring in an unknown system can place an agent in dangerous situations, exposing to potentially catastrophic hazards. Many current approaches for tackling safe learning in reinforcement learning (RL) lead to a trade-off between safe exploration and fulfilling the task. Though these methods possibly incur fewer safety violations, they often also lead to reduced task performance. In this paper, we take the first step in introducing a generation of RL solvers that learn to minimise safety violations while maximising the task reward to the extend that can be tolerated by safe policies. Our approach uses a new two-player framework for safe RL called Distributive Exploration Safety Training Algorithm (DESTA). The core of DESTA is a novel game between two RL agents: SAFETY AGENT that is delegated the task of minimising safety violations and TASK AGENT whose goal is to maximise the reward set by the environment task. SAFETY AGENT can selectively take control of the system at any given point to prevent safety violations while TASK AGENT is free to execute its actions at all other states. This framework enables SAFETY AGENT to learn to take actions that minimise future safety violations (during and after training) by performing safe actions at certain states while TASK AGENT performs actions that maximise the task performance everywhere else. We demonstrate DESTA's ability to tackle challenging tasks and compare against state-of-the-art RL methods in Safety Gym Benchmarks which simulate real-world physical systems and OpenAI's Lunar Lander.
Implicit Variational Conditional Sampling with Normalizing Flows
Jul 06, 2021
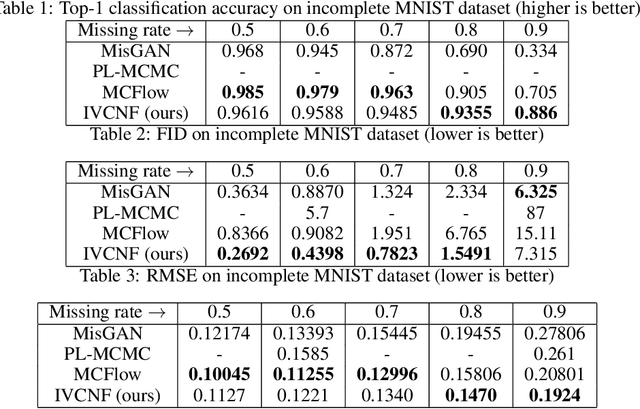
We present a method for conditional sampling with normalizing flows when only part of an observation is available. We rely on the following fact: if the flow's domain can be partitioned in such a way that the flow restrictions to subdomains keep the bijectivity property, a lower bound to the conditioning variable log-probability can be derived. Simulation from the variational conditional flow then amends to solving an equality constraint. Our contribution is three-fold: a) we provide detailed insights on the choice of variational distributions; b) we propose how to partition the input space of the flow to preserve bijectivity property; c) we propose a set of methods to optimise the variational distribution in specific cases. Through extensive experiments, we show that our sampling method can be applied with success to invertible residual networks for inference and classification.
Diagnosing and Preventing Instabilities in Recurrent Video Processing
Oct 17, 2020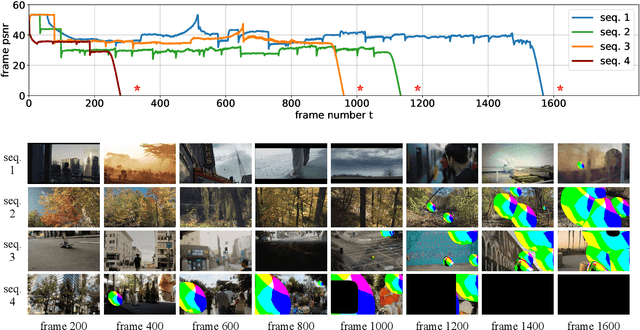


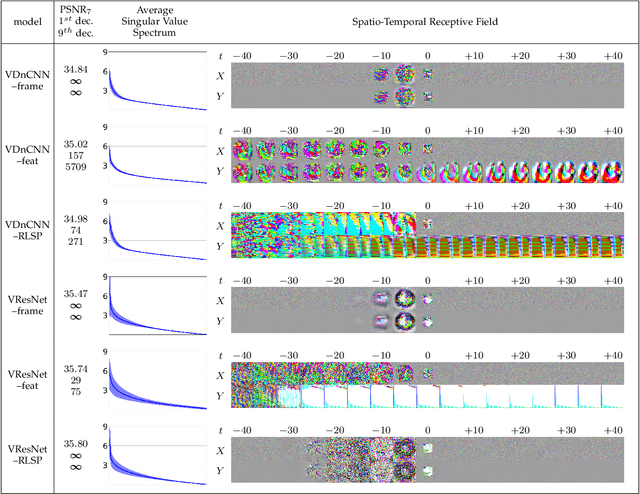
Recurrent models are becoming a popular choice for video enhancement tasks such as video denoising. In this work, we focus on their stability as dynamical systems and show that they tend to fail catastrophically at inference time on long video sequences. To address this issue, we (1) introduce a diagnostic tool which produces adversarial input sequences optimized to trigger instabilities and that can be interpreted as visualizations of spatio-temporal receptive fields, and (2) propose two approaches to enforce the stability of a model: constraining the spectral norm or constraining the stable rank of its convolutional layers. We then introduce Stable Rank Normalization of the Layers (SRNL), a new algorithm that enforces these constraints, and verify experimentally that it successfully results in stable recurrent video processing.
SAMBA: Safe Model-Based & Active Reinforcement Learning
Jun 12, 2020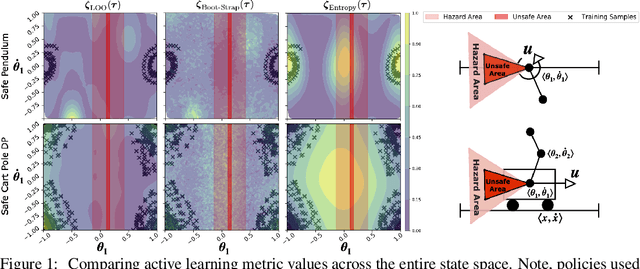
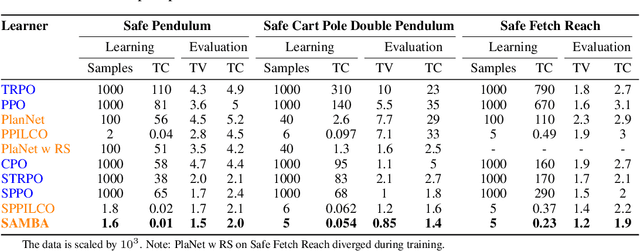
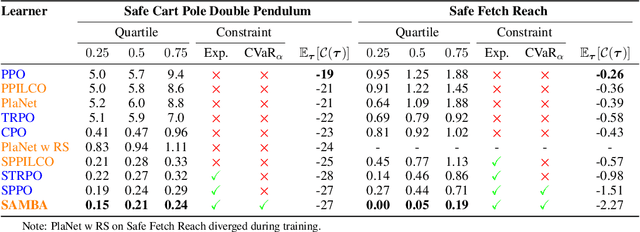
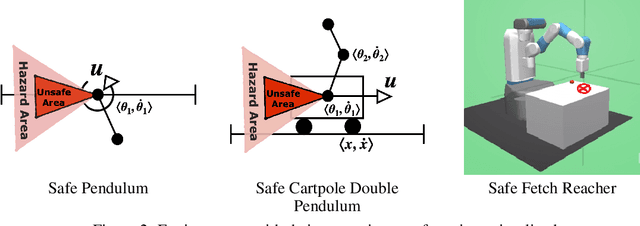
In this paper, we propose SAMBA, a novel framework for safe reinforcement learning that combines aspects from probabilistic modelling, information theory, and statistics. Our method builds upon PILCO to enable active exploration using novel(semi-)metrics for out-of-sample Gaussian process evaluation optimised through a multi-objective problem that supports conditional-value-at-risk constraints. We evaluate our algorithm on a variety of safe dynamical system benchmarks involving both low and high-dimensional state representations. Our results show orders of magnitude reductions in samples and violations compared to state-of-the-art methods. Lastly, we provide intuition as to the effectiveness of the framework by a detailed analysis of our active metrics and safety constraints.