 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Cooperation in Multi-agent Learning
Dec 08, 2023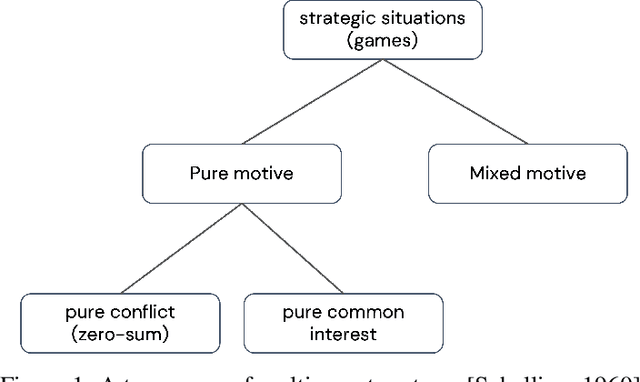
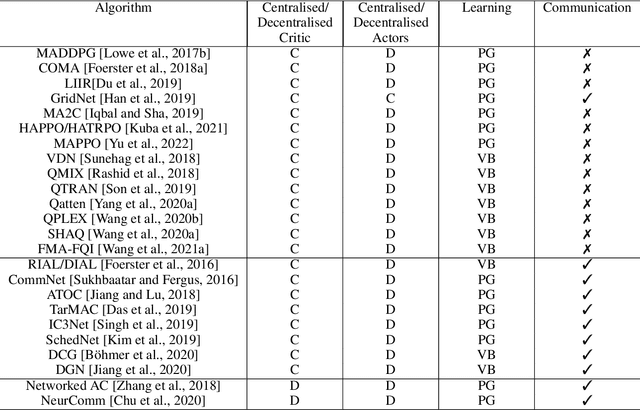

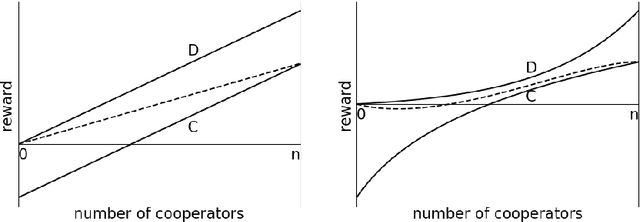
Cooperation in multi-agent learning (MAL) is a topic at the intersection of numerous disciplines, including game theory, economics, social sciences, and evolutionary biology. Research in this area aims to understand both how agents can coordinate effectively when goals are aligned and how they may cooperate in settings where gains from working together are possible but possibilities for conflict abound. In this paper we provide an overview of the fundamental concepts, problem settings and algorithms of multi-agent learning. This encompasses reinforcement learning, multi-agent sequential decision-making, challenges associated with multi-agent cooperation, and a comprehensive review of recent progress, along with an evaluation of relevant metrics. Finally we discuss open challenges in the field with the aim of inspiring new avenues for research.
DESTA: A Framework for Safe Reinforcement Learning with Markov Games of Intervention
Oct 27, 2021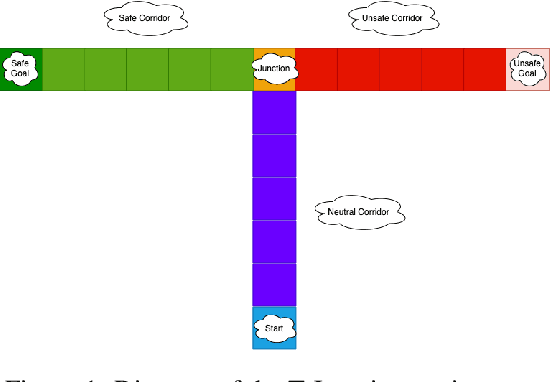
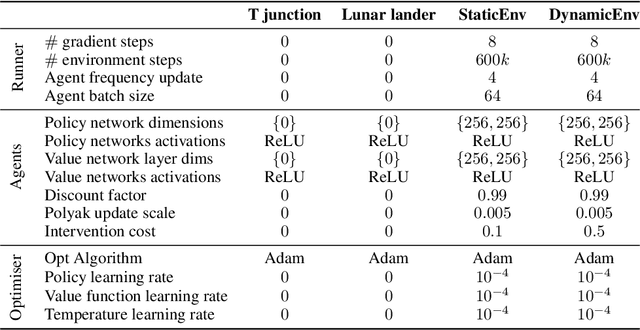
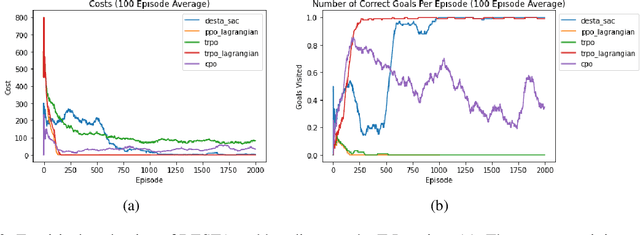

Exploring in an unknown system can place an agent in dangerous situations, exposing to potentially catastrophic hazards. Many current approaches for tackling safe learning in reinforcement learning (RL) lead to a trade-off between safe exploration and fulfilling the task. Though these methods possibly incur fewer safety violations, they often also lead to reduced task performance. In this paper, we take the first step in introducing a generation of RL solvers that learn to minimise safety violations while maximising the task reward to the extend that can be tolerated by safe policies. Our approach uses a new two-player framework for safe RL called Distributive Exploration Safety Training Algorithm (DESTA). The core of DESTA is a novel game between two RL agents: SAFETY AGENT that is delegated the task of minimising safety violations and TASK AGENT whose goal is to maximise the reward set by the environment task. SAFETY AGENT can selectively take control of the system at any given point to prevent safety violations while TASK AGENT is free to execute its actions at all other states. This framework enables SAFETY AGENT to learn to take actions that minimise future safety violations (during and after training) by performing safe actions at certain states while TASK AGENT performs actions that maximise the task performance everywhere else. We demonstrate DESTA's ability to tackle challenging tasks and compare against state-of-the-art RL methods in Safety Gym Benchmarks which simulate real-world physical systems and OpenAI's Lunar Lander.