 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Centralised Multi-Agent Reinforcement Learning with Policy-Embedded Training
Sep 02, 2022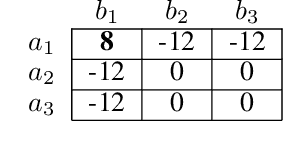
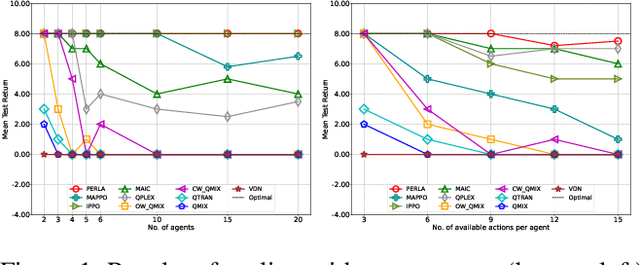
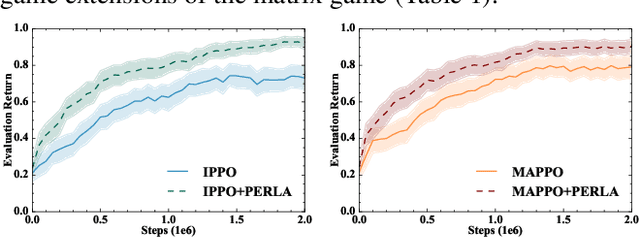
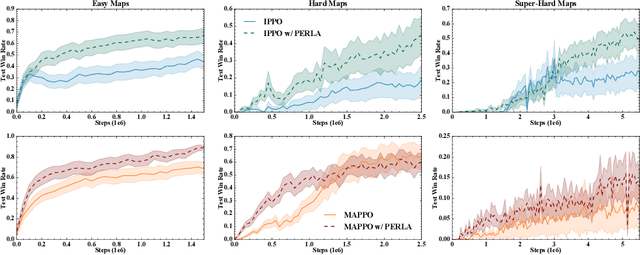
Centralised training (CT) is the basis for many popular multi-agent reinforcement learning (MARL) methods because it allows agents to quickly learn high-performing policies. However, CT relies on agents learning from one-off observations of other agents' actions at a given state. Because MARL agents explore and update their policies during training, these observations often provide poor predictions about other agents' behaviour and the expected return for a given action. CT methods therefore suffer from high variance and error-prone estimates, harming learning. CT methods also suffer from explosive growth in complexity due to the reliance on global observations, unless strong factorisation restrictions are imposed (e.g., monotonic reward functions for QMIX). We address these challenges with a new semi-centralised MARL framework that performs policy-embedded training and decentralised execution. Our method, policy embedded reinforcement learning algorithm (PERLA), is an enhancement tool for Actor-Critic MARL algorithms that leverages a novel parameter sharing protocol and policy embedding method to maintain estimates that account for other agents' behaviour. Our theory proves PERLA dramatically reduces the variance in value estimates. Unlike various CT methods, PERLA, which seamlessly adopts MARL algorithms, scales easily with the number of agents without the need for restrictive factorisation assumptions. We demonstrate PERLA's superior empirical performance and efficient scaling in benchmark environments including StarCraft Micromanagement II and Multi-agent Mujoco
SAUTE RL: Almost Surely Safe Reinforcement Learning Using State Augmentation
Feb 16, 2022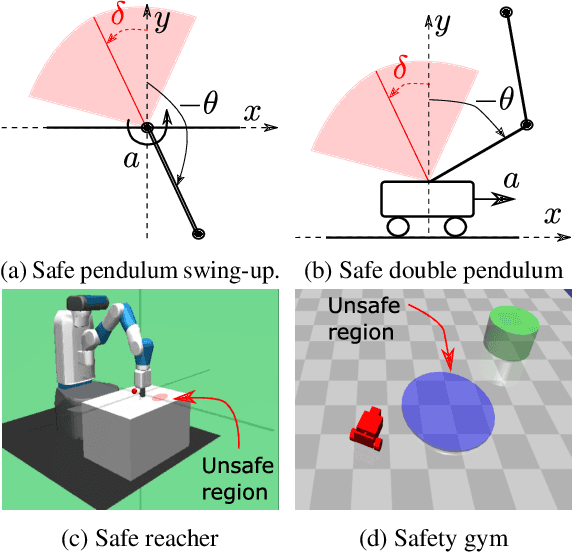
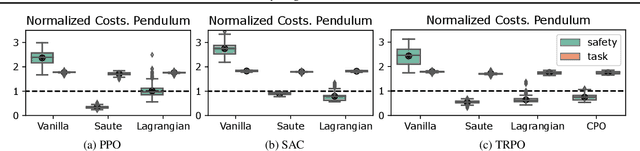
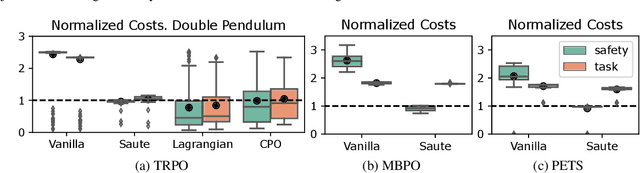
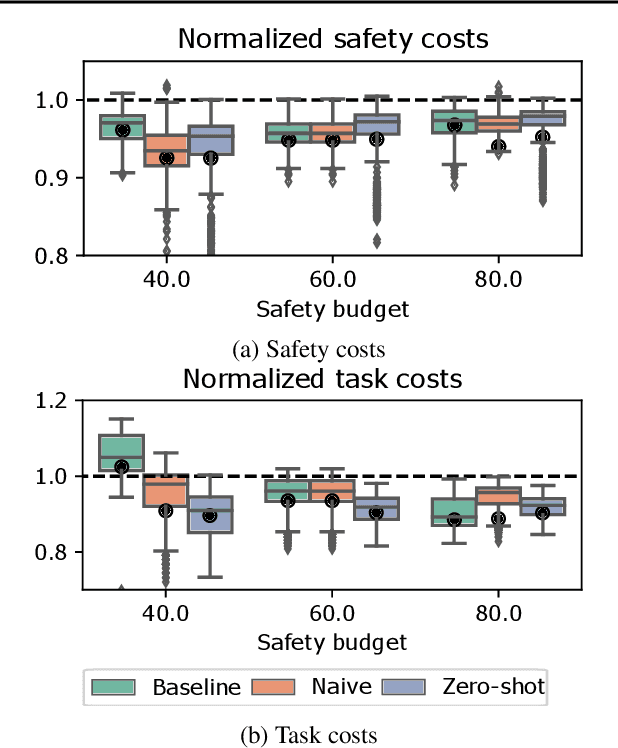
Satisfying safety constraints almost surely (or with probability one) can be critical for deployment of Reinforcement Learning (RL) in real-life applications. For example, plane landing and take-off should ideally occur with probability one. We address the problem by introducing Safety Augmented (Saute) Markov Decision Processes (MDPs), where the safety constraints are eliminated by augmenting them into the state-space and reshaping the objective. We show that Saute MDP satisfies the Bellman equation and moves us closer to solving Safe RL with constraints satisfied almost surely. We argue that Saute MDP allows to view Safe RL problem from a different perspective enabling new features. For instance, our approach has a plug-and-play nature, i.e., any RL algorithm can be "sauteed". Additionally, state augmentation allows for policy generalization across safety constraints. We finally show that Saute RL algorithms can outperform their state-of-the-art counterparts when constraint satisfaction is of high importance.
Reinforcement Learning in Presence of Discrete Markovian Context Evolution
Feb 14, 2022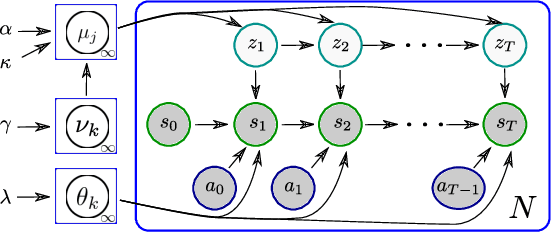
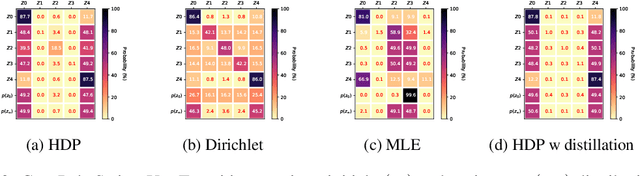
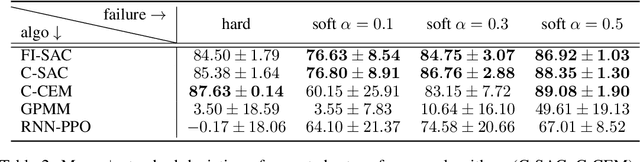
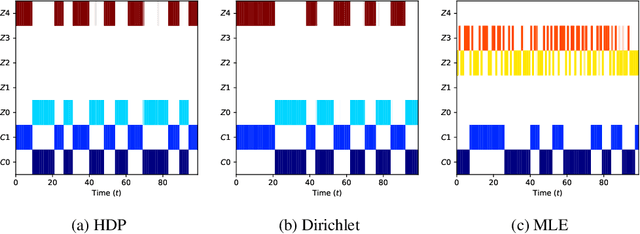
We consider a context-dependent Reinforcement Learning (RL) setting, which is characterized by: a) an unknown finite number of not directly observable contexts; b) abrupt (discontinuous) context changes occurring during an episode; and c) Markovian context evolution. We argue that this challenging case is often met in applications and we tackle it using a Bayesian approach and variational inference. We adapt a sticky Hierarchical Dirichlet Process (HDP) prior for model learning, which is arguably best-suited for Markov process modeling. We then derive a context distillation procedure, which identifies and removes spurious contexts in an unsupervised fashion. We argue that the combination of these two components allows to infer the number of contexts from data thus dealing with the context cardinality assumption. We then find the representation of the optimal policy enabling efficient policy learning using off-the-shelf RL algorithms. Finally, we demonstrate empirically (using gym environments cart-pole swing-up, drone, intersection) that our approach succeeds where state-of-the-art methods of other frameworks fail and elaborate on the reasons for such failures.
DESTA: A Framework for Safe Reinforcement Learning with Markov Games of Intervention
Oct 27, 2021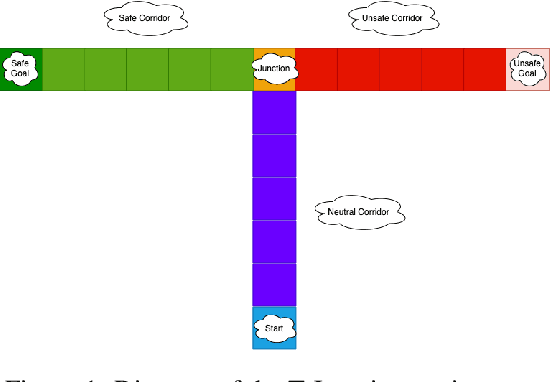
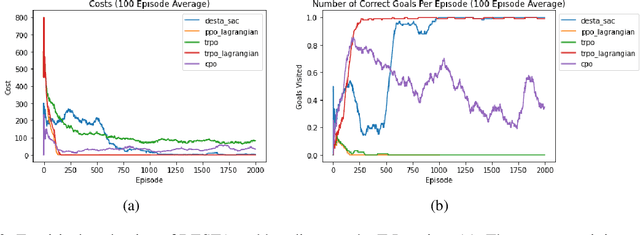

Exploring in an unknown system can place an agent in dangerous situations, exposing to potentially catastrophic hazards. Many current approaches for tackling safe learning in reinforcement learning (RL) lead to a trade-off between safe exploration and fulfilling the task. Though these methods possibly incur fewer safety violations, they often also lead to reduced task performance. In this paper, we take the first step in introducing a generation of RL solvers that learn to minimise safety violations while maximising the task reward to the extend that can be tolerated by safe policies. Our approach uses a new two-player framework for safe RL called Distributive Exploration Safety Training Algorithm (DESTA). The core of DESTA is a novel game between two RL agents: SAFETY AGENT that is delegated the task of minimising safety violations and TASK AGENT whose goal is to maximise the reward set by the environment task. SAFETY AGENT can selectively take control of the system at any given point to prevent safety violations while TASK AGENT is free to execute its actions at all other states. This framework enables SAFETY AGENT to learn to take actions that minimise future safety violations (during and after training) by performing safe actions at certain states while TASK AGENT performs actions that maximise the task performance everywhere else. We demonstrate DESTA's ability to tackle challenging tasks and compare against state-of-the-art RL methods in Safety Gym Benchmarks which simulate real-world physical systems and OpenAI's Lunar Lander.
Learning to Shape Rewards using a Game of Switching Controls
Mar 16, 2021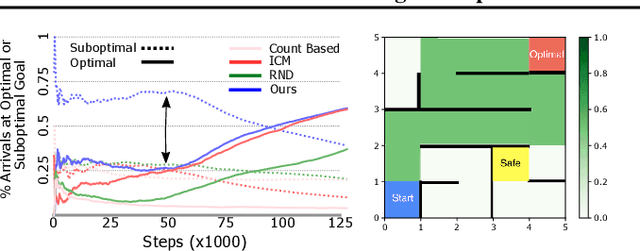
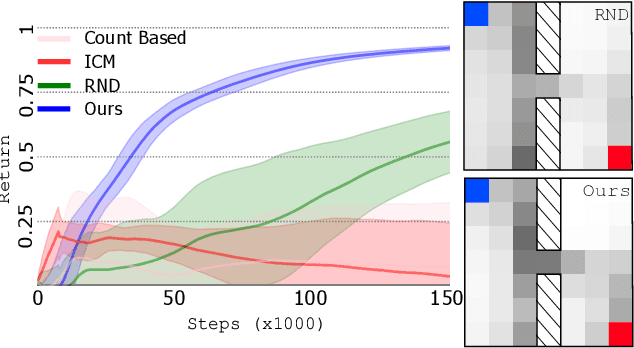
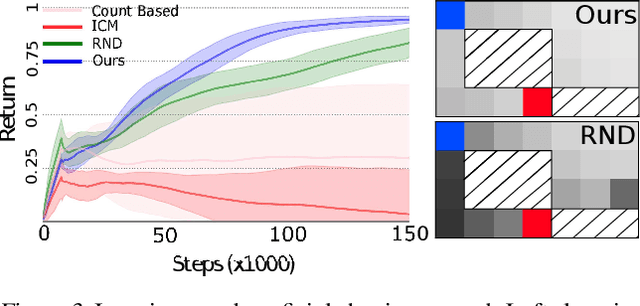
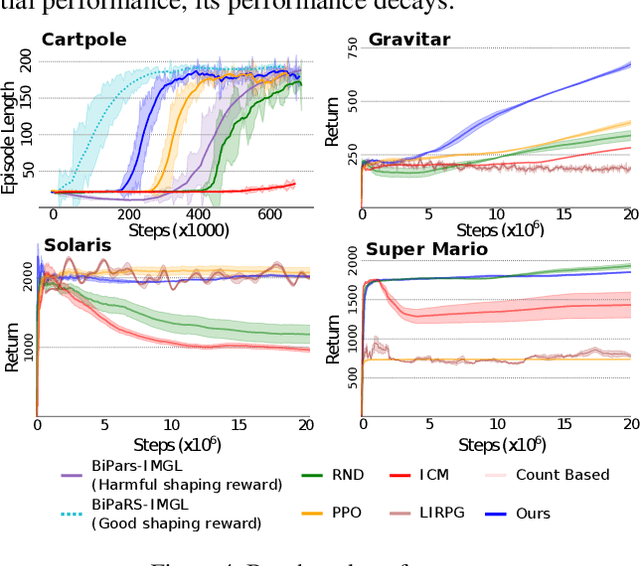
Reward shaping (RS) is a powerful method in reinforcement learning (RL) for overcoming the problem of sparse and uninformative rewards. However, RS relies on manually engineered shaping-reward functions whose construction is typically time-consuming and error-prone. It also requires domain knowledge which runs contrary to the goal of autonomous learning. In this paper, we introduce an automated RS framework in which the shaping-reward function is constructed in a novel stochastic game between two agents. One agent learns both which states to add shaping rewards and their optimal magnitudes and the other agent learns the optimal policy for the task using the shaped rewards. We prove theoretically that our framework, which easily adopts existing RL algorithms, learns to construct a shaping-reward function that is tailored to the task and ensures convergence to higher performing policies for the given task. We demonstrate the superior performance of our method against state-of-the-art RS algorithms in Cartpole and the challenging console games Gravitar, Solaris and Super Mario.
Hallucinating Value: A Pitfall of Dyna-style Planning with Imperfect Environment Models
Jun 08, 2020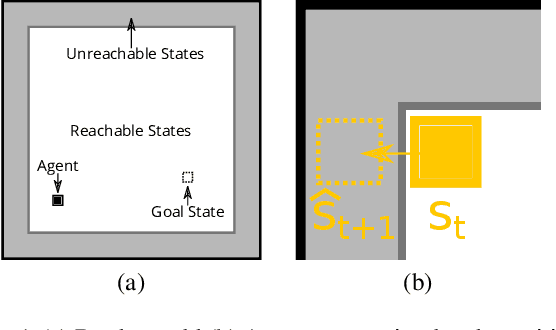
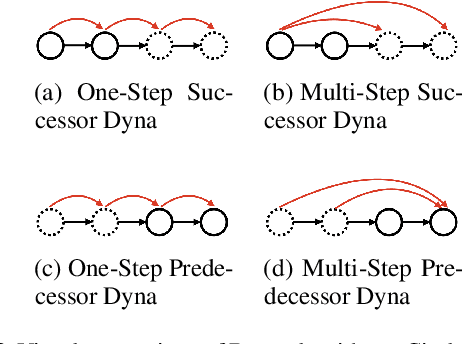
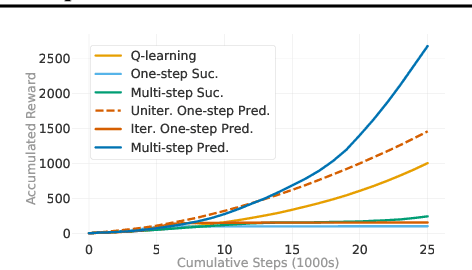
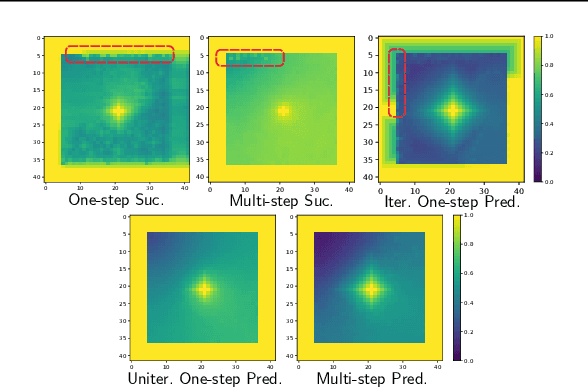
Dyna-style reinforcement learning (RL) agents improve sample efficiency over model-free RL agents by updating the value function with simulated experience generated by an environment model. However, it is often difficult to learn accurate models of environment dynamics, and even small errors may result in failure of Dyna agents. In this paper, we investigate one type of model error: hallucinated states. These are states generated by the model, but that are not real states of the environment. We present the Hallucinated Value Hypothesis (HVH): updating values of real states towards values of hallucinated states results in misleading state-action values which adversely affect the control policy. We discuss and evaluate four Dyna variants; three which update real states toward simulated -- and therefore potentially hallucinated -- states and one which does not. The experimental results provide evidence for the HVH thus suggesting a fruitful direction toward developing Dyna algorithms robust to model error.