 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucinating Value: A Pitfall of Dyna-style Planning with Imperfect Environment Models
Jun 08, 2020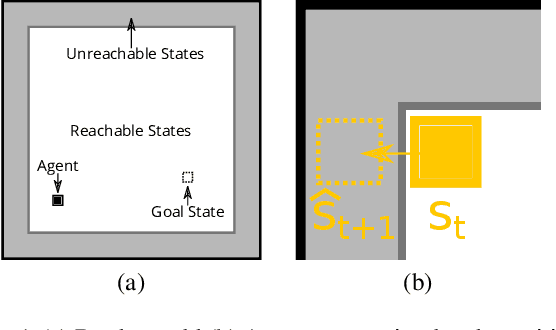
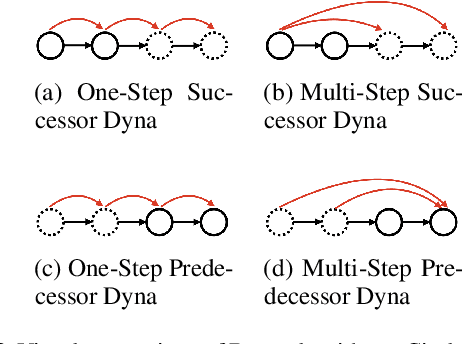
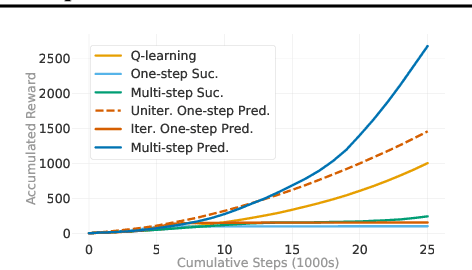
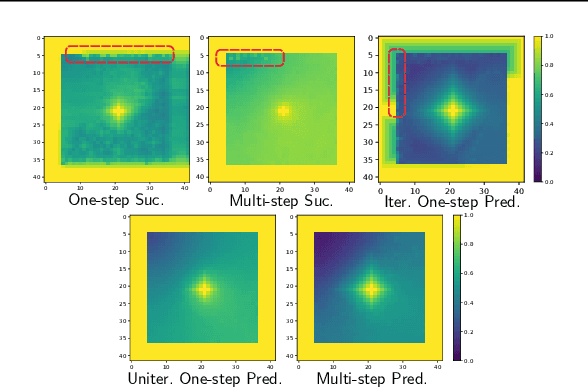
Dyna-style reinforcement learning (RL) agents improve sample efficiency over model-free RL agents by updating the value function with simulated experience generated by an environment model. However, it is often difficult to learn accurate models of environment dynamics, and even small errors may result in failure of Dyna agents. In this paper, we investigate one type of model error: hallucinated states. These are states generated by the model, but that are not real states of the environment. We present the Hallucinated Value Hypothesis (HVH): updating values of real states towards values of hallucinated states results in misleading state-action values which adversely affect the control policy. We discuss and evaluate four Dyna variants; three which update real states toward simulated -- and therefore potentially hallucinated -- states and one which does not. The experimental results provide evidence for the HVH thus suggesting a fruitful direction toward developing Dyna algorithms robust to model error.