 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Individual Human Preferences with Reward Features
Mar 21, 2025



Reinforcement learning from human feedback usually models preferences using a reward model that does not distinguish between people. We argue that this is unlikely to be a good design choice in contexts with high potential for disagreement, like in the training of large language models. We propose a method to specialise a reward model to a person or group of people. Our approach builds on the observation that individual preferences can be captured as a linear combination of a set of general reward features. We show how to learn such features and subsequently use them to quickly adapt the reward model to a specific individual, even if their preferences are not reflected in the training data. We present experiments with large language models comparing the proposed architecture with a non-adaptive reward model and also adaptive counterparts, including models that do in-context personalisation. Depending on how much disagreement there is in the training data, our model either significantly outperforms the baselines or matches their performance with a simpler architecture and more stable training.
Spiking Network Initialisation and Firing Rate Collapse
May 13, 2023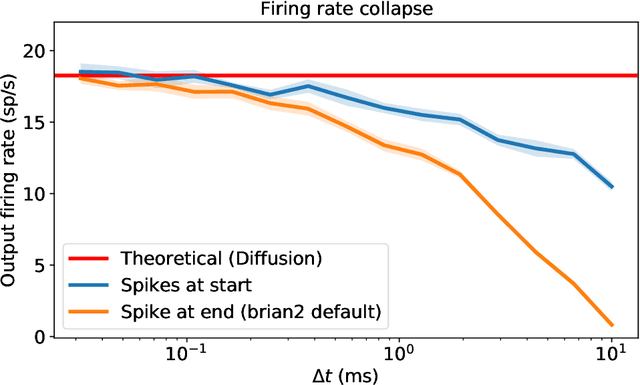
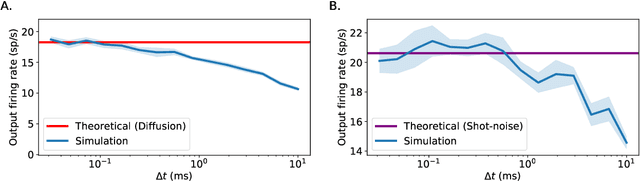
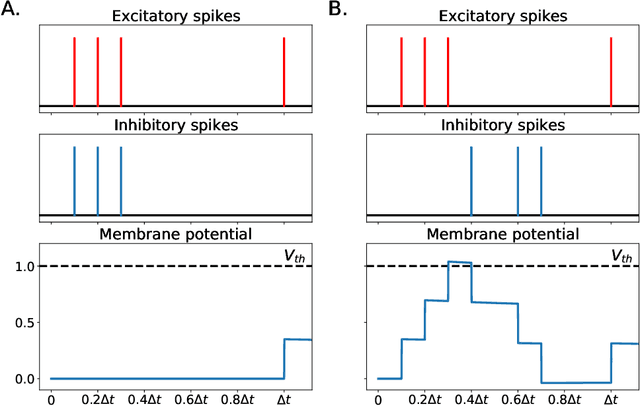
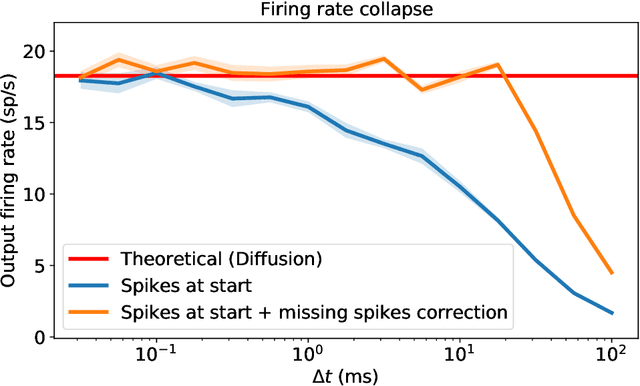
In recent years, newly developed methods to train spiking neural networks (SNNs) have rendered them as a plausible alternative to Artificial Neural Networks (ANNs) in terms of accuracy, while at the same time being much more energy efficient at inference and potentially at training time. However, it is still unclear what constitutes a good initialisation for an SNN. We often use initialisation schemes developed for ANN training which are often inadequate and require manual tuning. In this paper, we attempt to tackle this issue by using techniques from the ANN initialisation literature as well as computational neuroscience results. We show that the problem of weight initialisation for ANNs is a more nuanced problem than it is for ANNs due to the spike-and-reset non-linearity of SNNs and the firing rate collapse problem. We firstly identify and propose several solutions to the firing rate collapse problem under different sets of assumptions which successfully solve the issue by leveraging classical random walk and Wiener processes results. Secondly, we devise a general strategy for SNN initialisation which combines variance propagation techniques from ANNs and different methods to obtain the expected firing rate and membrane potential distribution based on diffusion and shot-noise approximations. Altogether, we obtain theoretical results to solve the SNN initialisation which consider the membrane potential distribution in the presence of a threshold. Yet, to what extent can these methods be successfully applied to SNNs on real datasets remains an open question.
Human-Timescale Adaptation in an Open-Ended Task Space
Jan 18, 2023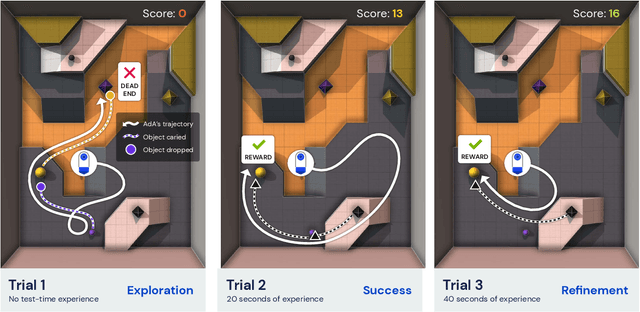
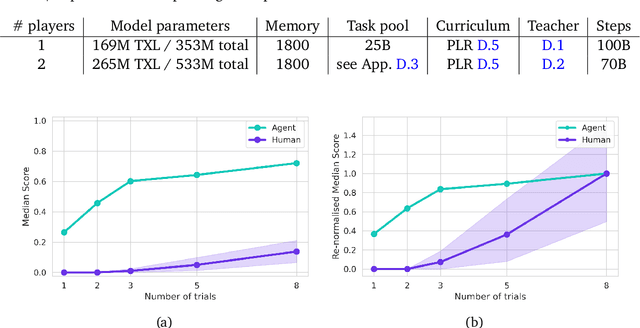
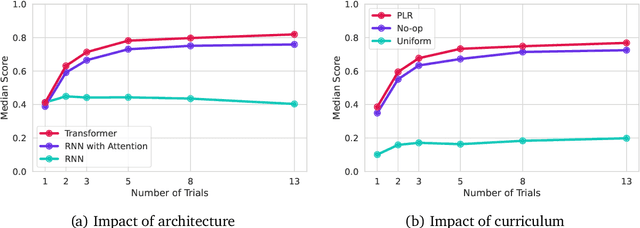
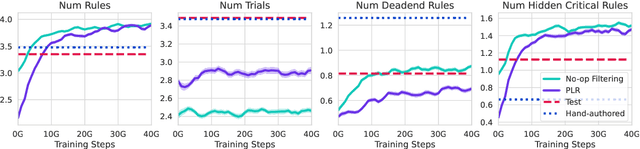
Foundation models have shown impressive adaptation and scalability in supervised and self-supervised learning problems, but so far these successes have not fully translated to reinforcement learning (RL). In this work, we demonstrate that training an RL agent at scale leads to a general in-context learning algorithm that can adapt to open-ended novel embodied 3D problems as quickly as humans. In a vast space of held-out environment dynamics, our adaptive agent (AdA) displays on-the-fly hypothesis-driven exploration, efficient exploitation of acquired knowledge, and can successfully be prompted with first-person demonstrations. Adaptation emerges from three ingredients: (1) meta-reinforcement learning across a vast, smooth and diverse task distribution, (2) a policy parameterised as a large-scale attention-based memory architecture, and (3) an effective automated curriculum that prioritises tasks at the frontier of an agent's capabilities. We demonstrate characteristic scaling laws with respect to network size, memory length, and richness of the training task distribution. We believe our results lay the foundation for increasingly general and adaptive RL agents that perform well across ever-larger open-ended domains.
Sparse Spiking Gradient Descent
May 18, 2021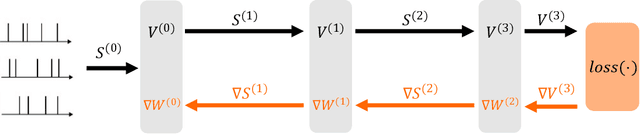
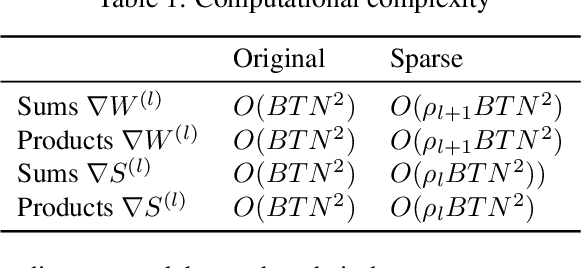
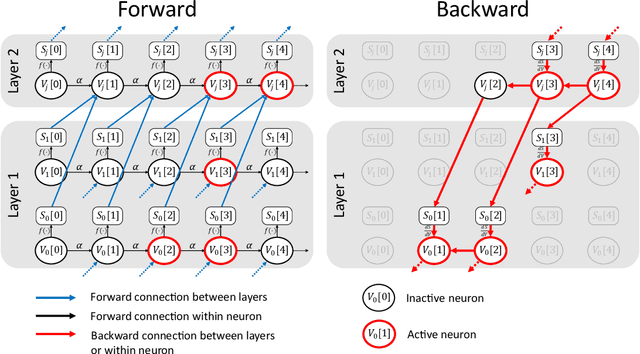

There is an increasing interest in emulating Spiking Neural Networks (SNNs) on neuromorphic computing devices due to their low energy consumption. Recent advances have allowed training SNNs to a point where they start to compete with traditional Artificial Neural Networks (ANNs) in terms of accuracy, while at the same time being energy efficient when run on neuromorphic hardware. However, the process of training SNNs is still based on dense tensor operations originally developed for ANNs which do not leverage the spatiotemporally sparse nature of SNNs. We present here the first sparse SNN backpropagation algorithm which achieves the same or better accuracy as current state of the art methods while being significantly faster and more memory efficient. We show the effectiveness of our method on real datasets of varying complexity (Fashion-MNIST, Neuromophic-MNIST and Spiking Heidelberg Digits) achieving a speedup in the backward pass of up to 70x, and 40% more memory efficient, without losing accuracy.
Learning to Shape Rewards using a Game of Switching Controls
Mar 16, 2021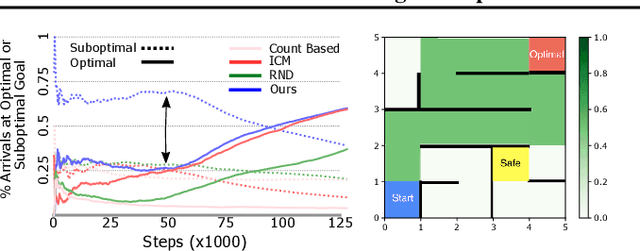
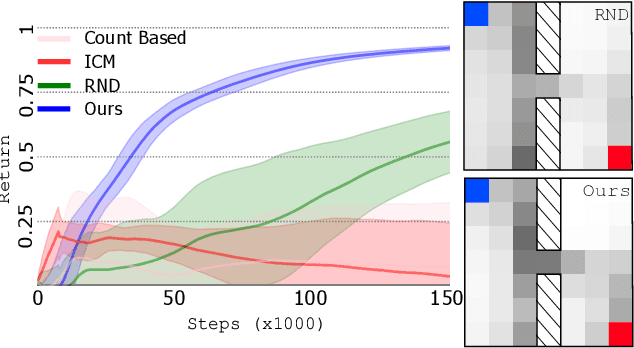
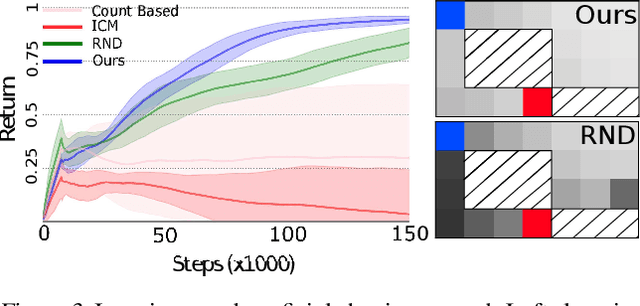
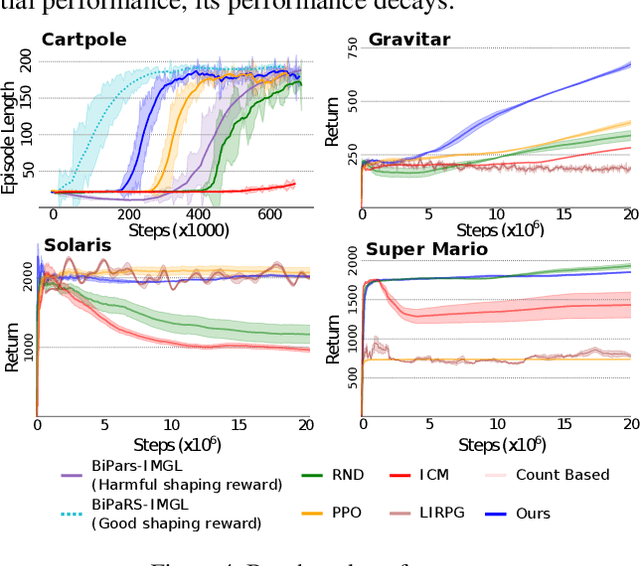
Reward shaping (RS) is a powerful method in reinforcement learning (RL) for overcoming the problem of sparse and uninformative rewards. However, RS relies on manually engineered shaping-reward functions whose construction is typically time-consuming and error-prone. It also requires domain knowledge which runs contrary to the goal of autonomous learning. In this paper, we introduce an automated RS framework in which the shaping-reward function is constructed in a novel stochastic game between two agents. One agent learns both which states to add shaping rewards and their optimal magnitudes and the other agent learns the optimal policy for the task using the shaped rewards. We prove theoretically that our framework, which easily adopts existing RL algorithms, learns to construct a shaping-reward function that is tailored to the task and ensures convergence to higher performing policies for the given task. We demonstrate the superior performance of our method against state-of-the-art RS algorithms in Cartpole and the challenging console games Gravitar, Solaris and Super Mario.