 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Geometry of Games and their Solvers
May 28, 2026A central challenge in game theory and learning systems such as GANs is understanding which algorithms can efficiently compute equilibria across the heterogeneous landscape of games. Equilibrium computation is typically studied solver by solver and game class by game class, yielding strong local guarantees but a fragmented view of solver behaviour. Existing discrete taxonomies often provide an incomplete account of where algorithms succeed. We study this problem through a solver-game map linking games to effective solver dynamics. Classical theory identifies isolated regions of this map but provides limited insight into intermediate or overlapping regimes, suggesting that solvability is governed by latent structural properties defining a continuous solver-aligned geometry of games. We formalise this perspective through structure-aware solver synthesis. A learned structure recogniser maps each game to a low-dimensional solver-aligned representation, and a policy maps this representation to effective primitive mechanisms, adapting solver behaviour across regimes. This reveals regions where particular solver dynamics are effective and where mixtures of primitives are required rather than a single dominant solver. A bounded residual acts as a local corrector and diagnostic signal for incomplete solver bases or representations. The framework yields both an adaptive solver and an analytical lens: games with similar optimisation dynamics cluster together, revealing continuous regions of algorithmic validity and overlapping solver behaviour. Empirically, we show that fixed primitives exhibit systematic regime mismatch, while the learned representation organises game space into a structured cartography aligned with solver behaviour. These results suggest viewing equilibrium computation as the joint problem of learning solver mechanisms and mapping the geometry of solvability.
All Language Models Large and Small
Feb 19, 2024



Many leading language models (LMs) use high-intensity computational resources both during training and execution. This poses the challenge of lowering resource costs for deployment and faster execution of decision-making tasks among others. We introduce a novel plug-and-play LM framework named Language Optimising Network Distribution (LONDI) framework. LONDI learns to selectively employ large LMs only where complex decision-making and reasoning are required while using low-resource LMs everywhere else. LONDI consists of a system of two (off-)policy networks, an LM, a large LM (LLM), and a reinforcement learning module that uses switching controls to quickly learn which system states to call the LLM. We then introduce a variant of LONDI that maintains budget constraints on LLM calls and hence its resource usage. Theoretically, we prove LONDI learns the subset of system states to activate the LLM required to solve the task. We then prove that LONDI converges to optimal solutions while also preserving budgetary constraints on LLM calls almost surely enabling it to solve various tasks while significantly lowering computational costs. We test LONDI's performance in a range of tasks in ScienceWorld and BabyAI-Text and demonstrate that LONDI can solve tasks only solvable by resource-intensive LLMs while reducing GPU usage by up to 30%.
ChessGPT: Bridging Policy Learning and Language Modeling
Jun 15, 2023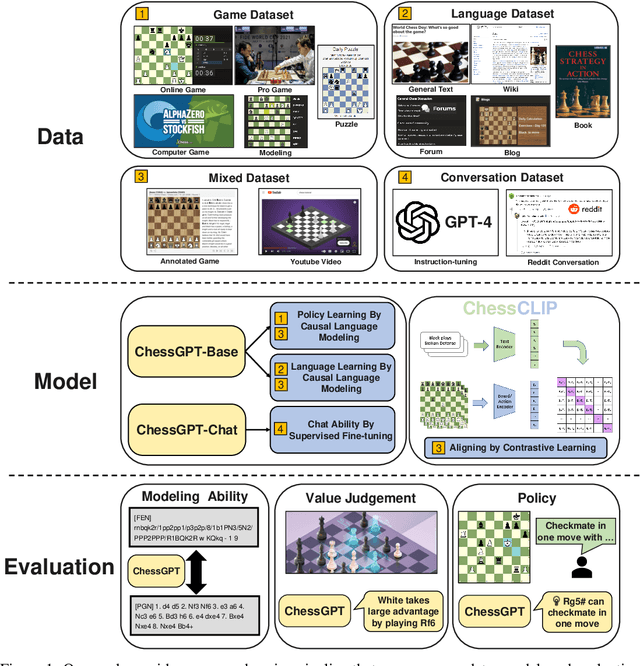
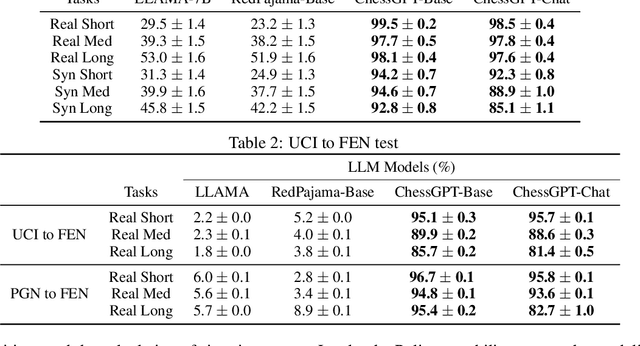
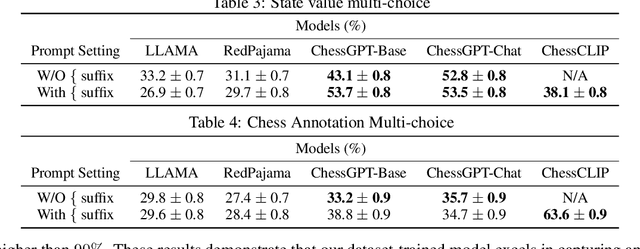
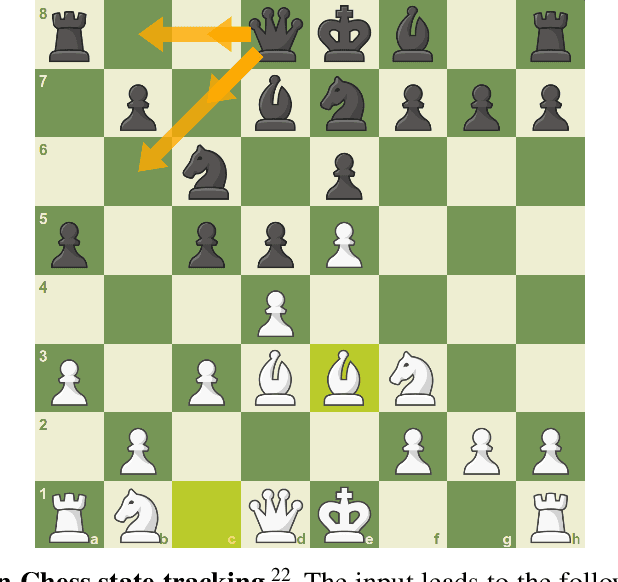
When solving decision-making tasks, humans typically depend on information from two key sources: (1) Historical policy data, which provides interaction replay from the environment, and (2) Analytical insights in natural language form, exposing the invaluable thought process or strategic considerations. Despite this, the majority of preceding research focuses on only one source: they either use historical replay exclusively to directly learn policy or value functions, or engaged in language model training utilizing mere language corpus. In this paper, we argue that a powerful autonomous agent should cover both sources. Thus, we propose ChessGPT, a GPT model bridging policy learning and language modeling by integrating data from these two sources in Chess games. Specifically, we build a large-scale game and language dataset related to chess. Leveraging the dataset, we showcase two model examples ChessCLIP and ChessGPT, integrating policy learning and language modeling. Finally, we propose a full evaluation framework for evaluating language model's chess ability. Experimental results validate our model and dataset's effectiveness. We open source our code, model, and dataset at https://github.com/waterhorse1/ChessGPT.
Ensemble Value Functions for Efficient Exploration in Multi-Agent Reinforcement Learning
Mar 02, 2023



Cooperative multi-agent reinforcement learning (MARL) requires agents to explore to learn to cooperate. Existing value-based MARL algorithms commonly rely on random exploration, such as $\epsilon$-greedy, which is inefficient in discovering multi-agent cooperation. Additionally, the environment in MARL appears non-stationary to any individual agent due to the simultaneous training of other agents, leading to highly variant and thus unstable optimisation signals. In this work, we propose ensemble value functions for multi-agent exploration (EMAX), a general framework to extend any value-based MARL algorithm. EMAX trains ensembles of value functions for each agent to address the key challenges of exploration and non-stationarity: (1) The uncertainty of value estimates across the ensemble is used in a UCB policy to guide the exploration of agents to parts of the environment which require cooperation. (2) Average value estimates across the ensemble serve as target values. These targets exhibit lower variance compared to commonly applied target networks and we show that they lead to more stable gradients during the optimisation. We instantiate three value-based MARL algorithms with EMAX, independent DQN, VDN and QMIX, and evaluate them in 21 tasks across four environments. Using ensembles of five value functions, EMAX improves sample efficiency and final evaluation returns of these algorithms by 54%, 55%, and 844%, respectively, averaged all 21 tasks.
Semi-Centralised Multi-Agent Reinforcement Learning with Policy-Embedded Training
Sep 02, 2022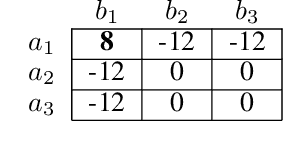
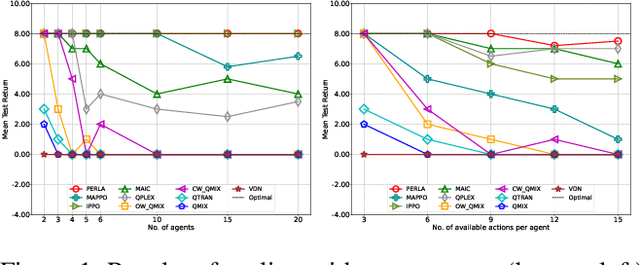
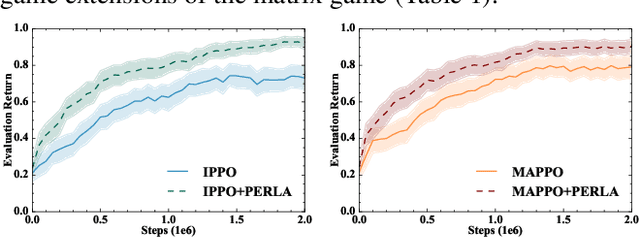
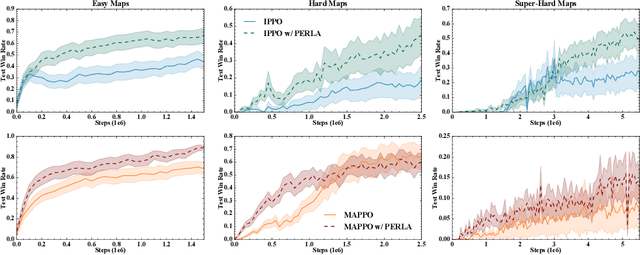
Centralised training (CT) is the basis for many popular multi-agent reinforcement learning (MARL) methods because it allows agents to quickly learn high-performing policies. However, CT relies on agents learning from one-off observations of other agents' actions at a given state. Because MARL agents explore and update their policies during training, these observations often provide poor predictions about other agents' behaviour and the expected return for a given action. CT methods therefore suffer from high variance and error-prone estimates, harming learning. CT methods also suffer from explosive growth in complexity due to the reliance on global observations, unless strong factorisation restrictions are imposed (e.g., monotonic reward functions for QMIX). We address these challenges with a new semi-centralised MARL framework that performs policy-embedded training and decentralised execution. Our method, policy embedded reinforcement learning algorithm (PERLA), is an enhancement tool for Actor-Critic MARL algorithms that leverages a novel parameter sharing protocol and policy embedding method to maintain estimates that account for other agents' behaviour. Our theory proves PERLA dramatically reduces the variance in value estimates. Unlike various CT methods, PERLA, which seamlessly adopts MARL algorithms, scales easily with the number of agents without the need for restrictive factorisation assumptions. We demonstrate PERLA's superior empirical performance and efficient scaling in benchmark environments including StarCraft Micromanagement II and Multi-agent Mujoco
Timing is Everything: Learning to Act Selectively with Costly Actions and Budgetary Constraints
Jun 06, 2022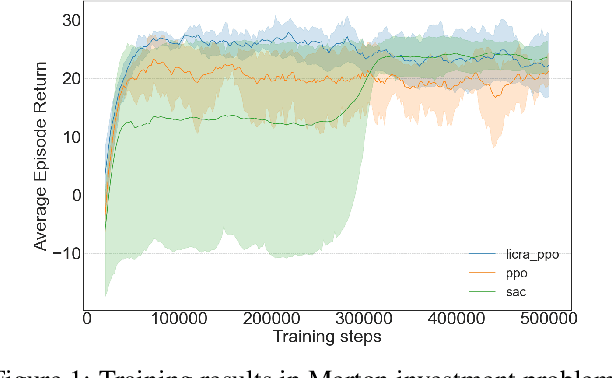
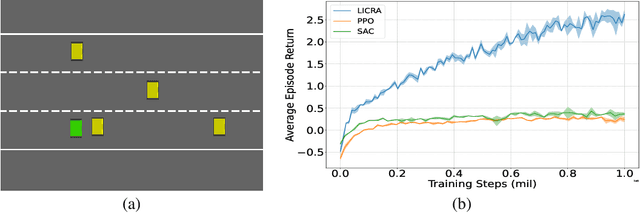
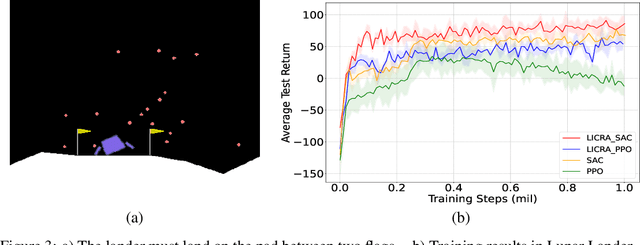
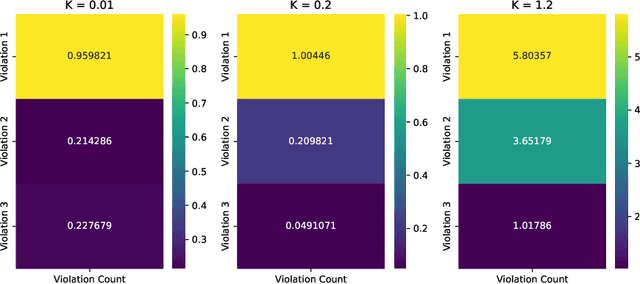
Many real-world settings involve costs for performing actions; transaction costs in financial systems and fuel costs being common examples. In these settings, performing actions at each time step quickly accumulates costs leading to vastly suboptimal outcomes. Additionally, repeatedly acting produces wear and tear and ultimately, damage. Determining when to act is crucial for achieving successful outcomes and yet, the challenge of efficiently learning to behave optimally when actions incur minimally bounded costs remains unresolved. In this paper, we introduce a reinforcement learning (RL) framework named Learnable Impulse Control Reinforcement Algorithm (LICRA), for learning to optimally select both when to act and which actions to take when actions incur costs. At the core of LICRA is a nested structure that combines RL and a form of policy known as impulse control which learns to maximise objectives when actions incur costs. We prove that LICRA, which seamlessly adopts any RL method, converges to policies that optimally select when to perform actions and their optimal magnitudes. We then augment LICRA to handle problems in which the agent can perform at most $k<\infty$ actions and more generally, faces a budget constraint. We show LICRA learns the optimal value function and ensures budget constraints are satisfied almost surely. We demonstrate empirically LICRA's superior performance against benchmark RL methods in OpenAI gym's Lunar Lander and in Highway environments and a variant of the Merton portfolio problem within finance.
SEREN: Knowing When to Explore and When to Exploit
May 30, 2022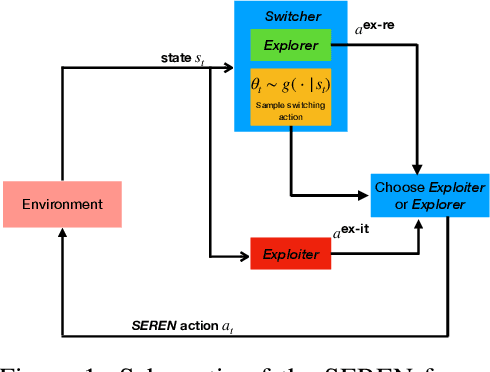
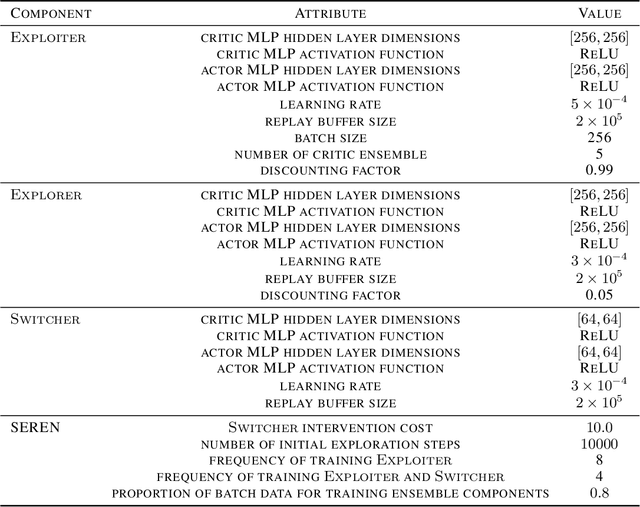
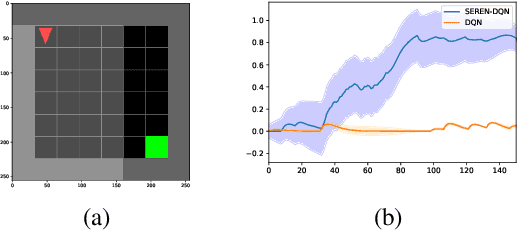
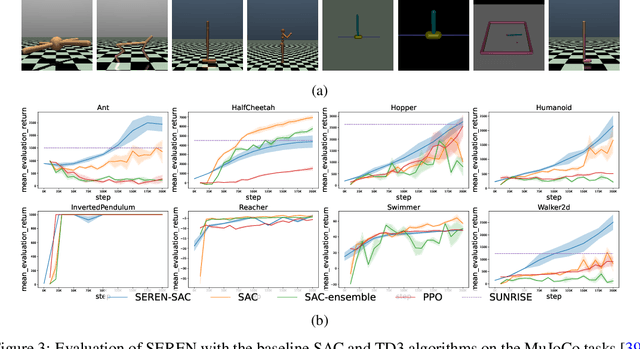
Efficient reinforcement learning (RL) involves a trade-off between "exploitative" actions that maximise expected reward and "explorative'" ones that sample unvisited states. To encourage exploration, recent approaches proposed adding stochasticity to actions, separating exploration and exploitation phases, or equating reduction in uncertainty with reward. However, these techniques do not necessarily offer entirely systematic approaches making this trade-off. Here we introduce SElective Reinforcement Exploration Network (SEREN) that poses the exploration-exploitation trade-off as a game between an RL agent -- \exploiter, which purely exploits known rewards, and another RL agent -- \switcher, which chooses at which states to activate a pure exploration policy that is trained to minimise system uncertainty and override Exploiter. Using a form of policies known as impulse control, \switcher is able to determine the best set of states to switch to the exploration policy while Exploiter is free to execute its actions everywhere else. We prove that SEREN converges quickly and induces a natural schedule towards pure exploitation. Through extensive empirical studies in both discrete (MiniGrid) and continuous (MuJoCo) control benchmarks, we show that SEREN can be readily combined with existing RL algorithms to yield significant improvement in performance relative to state-of-the-art algorithms.
On the Convergence of Fictitious Play: A Decomposition Approach
May 03, 2022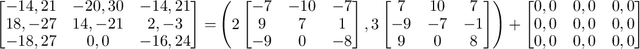
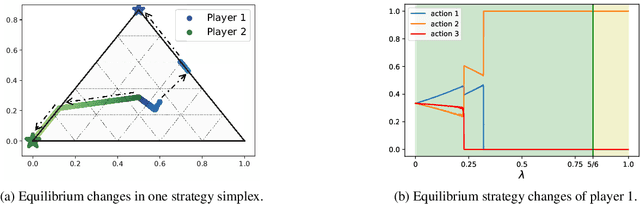
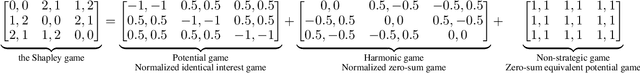

Fictitious play (FP) is one of the most fundamental game-theoretical learning frameworks for computing Nash equilibrium in $n$-player games, which builds the foundation for modern multi-agent learning algorithms. Although FP has provable convergence guarantees on zero-sum games and potential games, many real-world problems are often a mixture of both and the convergence property of FP has not been fully studied yet. In this paper, we extend the convergence results of FP to the combinations of such games and beyond. Specifically, we derive new conditions for FP to converge by leveraging game decomposition techniques. We further develop a linear relationship unifying cooperation and competition in the sense that these two classes of games are mutually transferable. Finally, we analyze a non-convergent example of FP, the Shapley game, and develop sufficient conditions for FP to converge.
SAUTE RL: Almost Surely Safe Reinforcement Learning Using State Augmentation
Feb 16, 2022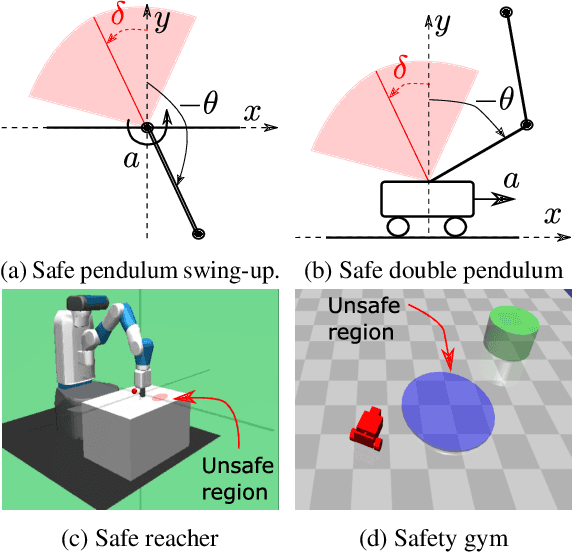
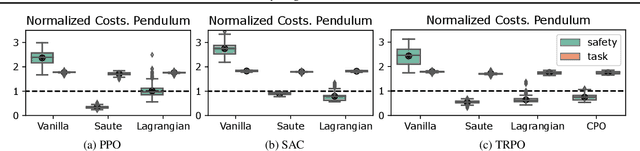
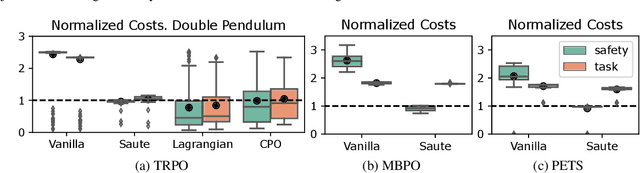
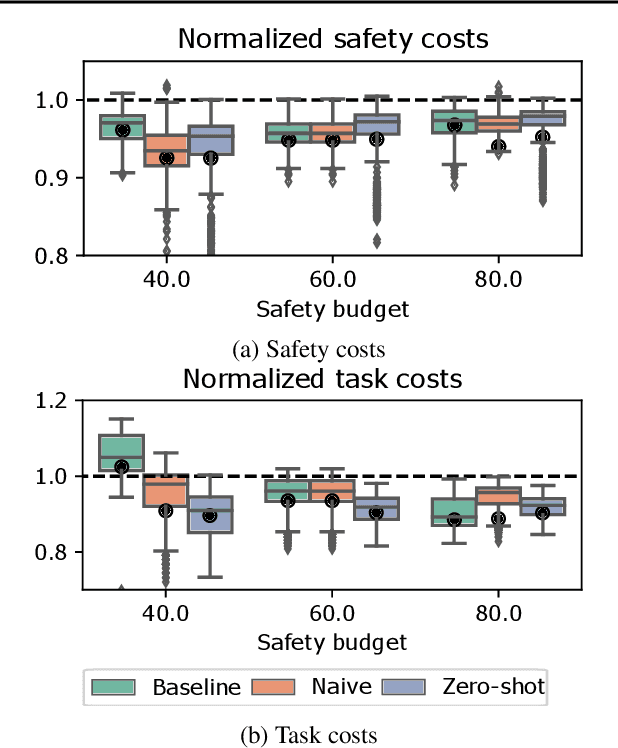
Satisfying safety constraints almost surely (or with probability one) can be critical for deployment of Reinforcement Learning (RL) in real-life applications. For example, plane landing and take-off should ideally occur with probability one. We address the problem by introducing Safety Augmented (Saute) Markov Decision Processes (MDPs), where the safety constraints are eliminated by augmenting them into the state-space and reshaping the objective. We show that Saute MDP satisfies the Bellman equation and moves us closer to solving Safe RL with constraints satisfied almost surely. We argue that Saute MDP allows to view Safe RL problem from a different perspective enabling new features. For instance, our approach has a plug-and-play nature, i.e., any RL algorithm can be "sauteed". Additionally, state augmentation allows for policy generalization across safety constraints. We finally show that Saute RL algorithms can outperform their state-of-the-art counterparts when constraint satisfaction is of high importance.
DESTA: A Framework for Safe Reinforcement Learning with Markov Games of Intervention
Oct 27, 2021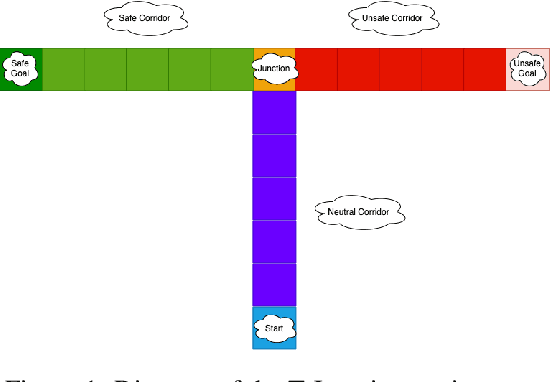
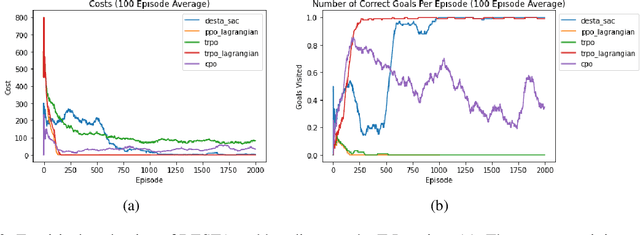

Exploring in an unknown system can place an agent in dangerous situations, exposing to potentially catastrophic hazards. Many current approaches for tackling safe learning in reinforcement learning (RL) lead to a trade-off between safe exploration and fulfilling the task. Though these methods possibly incur fewer safety violations, they often also lead to reduced task performance. In this paper, we take the first step in introducing a generation of RL solvers that learn to minimise safety violations while maximising the task reward to the extend that can be tolerated by safe policies. Our approach uses a new two-player framework for safe RL called Distributive Exploration Safety Training Algorithm (DESTA). The core of DESTA is a novel game between two RL agents: SAFETY AGENT that is delegated the task of minimising safety violations and TASK AGENT whose goal is to maximise the reward set by the environment task. SAFETY AGENT can selectively take control of the system at any given point to prevent safety violations while TASK AGENT is free to execute its actions at all other states. This framework enables SAFETY AGENT to learn to take actions that minimise future safety violations (during and after training) by performing safe actions at certain states while TASK AGENT performs actions that maximise the task performance everywhere else. We demonstrate DESTA's ability to tackle challenging tasks and compare against state-of-the-art RL methods in Safety Gym Benchmarks which simulate real-world physical systems and OpenAI's Lunar Lander.