 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Value Functions for Efficient Exploration in Multi-Agent Reinforcement Learning
Mar 02, 2023



Cooperative multi-agent reinforcement learning (MARL) requires agents to explore to learn to cooperate. Existing value-based MARL algorithms commonly rely on random exploration, such as $\epsilon$-greedy, which is inefficient in discovering multi-agent cooperation. Additionally, the environment in MARL appears non-stationary to any individual agent due to the simultaneous training of other agents, leading to highly variant and thus unstable optimisation signals. In this work, we propose ensemble value functions for multi-agent exploration (EMAX), a general framework to extend any value-based MARL algorithm. EMAX trains ensembles of value functions for each agent to address the key challenges of exploration and non-stationarity: (1) The uncertainty of value estimates across the ensemble is used in a UCB policy to guide the exploration of agents to parts of the environment which require cooperation. (2) Average value estimates across the ensemble serve as target values. These targets exhibit lower variance compared to commonly applied target networks and we show that they lead to more stable gradients during the optimisation. We instantiate three value-based MARL algorithms with EMAX, independent DQN, VDN and QMIX, and evaluate them in 21 tasks across four environments. Using ensembles of five value functions, EMAX improves sample efficiency and final evaluation returns of these algorithms by 54%, 55%, and 844%, respectively, averaged all 21 tasks.
Timing is Everything: Learning to Act Selectively with Costly Actions and Budgetary Constraints
Jun 06, 2022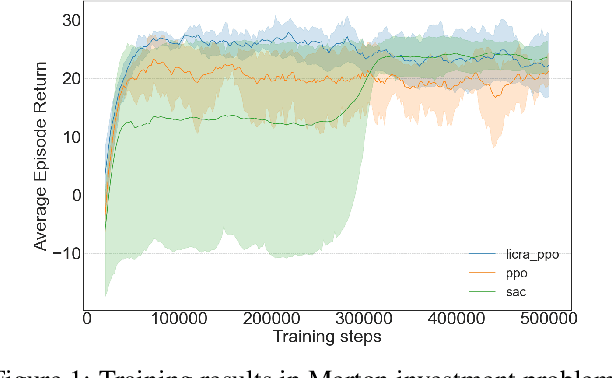
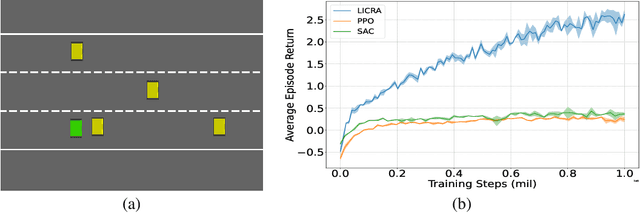
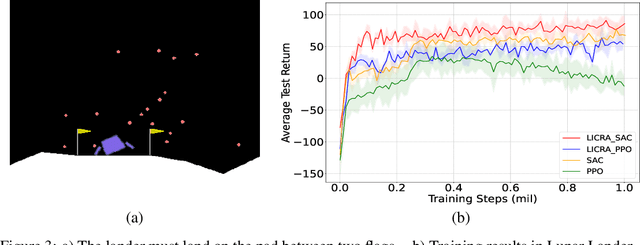
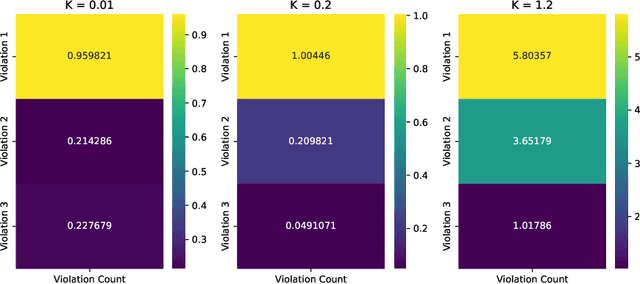
Many real-world settings involve costs for performing actions; transaction costs in financial systems and fuel costs being common examples. In these settings, performing actions at each time step quickly accumulates costs leading to vastly suboptimal outcomes. Additionally, repeatedly acting produces wear and tear and ultimately, damage. Determining when to act is crucial for achieving successful outcomes and yet, the challenge of efficiently learning to behave optimally when actions incur minimally bounded costs remains unresolved. In this paper, we introduce a reinforcement learning (RL) framework named Learnable Impulse Control Reinforcement Algorithm (LICRA), for learning to optimally select both when to act and which actions to take when actions incur costs. At the core of LICRA is a nested structure that combines RL and a form of policy known as impulse control which learns to maximise objectives when actions incur costs. We prove that LICRA, which seamlessly adopts any RL method, converges to policies that optimally select when to perform actions and their optimal magnitudes. We then augment LICRA to handle problems in which the agent can perform at most $k<\infty$ actions and more generally, faces a budget constraint. We show LICRA learns the optimal value function and ensures budget constraints are satisfied almost surely. We demonstrate empirically LICRA's superior performance against benchmark RL methods in OpenAI gym's Lunar Lander and in Highway environments and a variant of the Merton portfolio problem within finance.
Learning Risk-Averse Equilibria in Multi-Agent Systems
May 30, 2022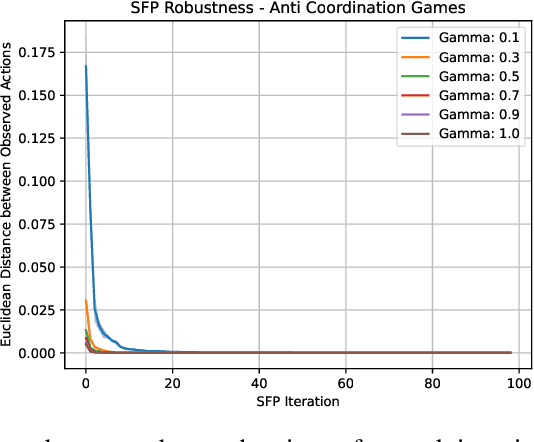
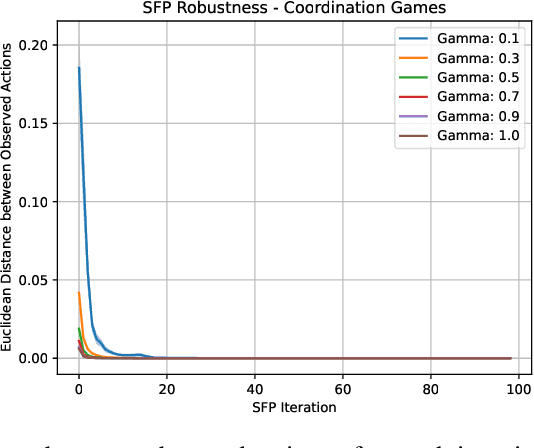
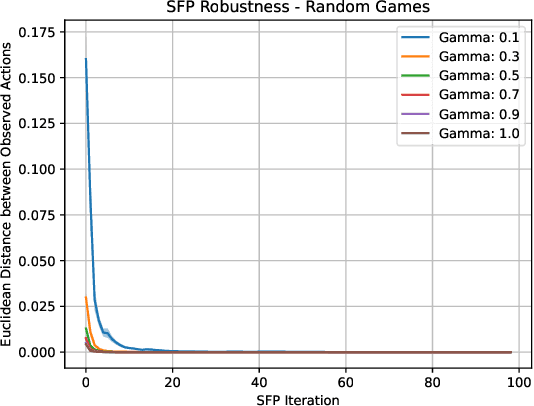
In multi-agent systems, intelligent agents are tasked with making decisions that have optimal outcomes when the actions of the other agents are as expected, whilst also being prepared for unexpected behaviour. In this work, we introduce a new risk-averse solution concept that allows the learner to accommodate unexpected actions by finding the minimum variance strategy given any level of expected return. We prove the existence of such a risk-averse equilibrium, and propose one fictitious-play type learning algorithm for smaller games that enjoys provable convergence guarantees in certain games classes (e.g., zero-sum or potential). Furthermore, we propose an approximation method for larger games based on iterative population-based training that generates a population of risk-averse agents. Empirically, our equilibrium is shown to be able to reduce the reward variance, specifically in the sense that off-equilibrium behaviour has a far smaller impact on our risk-averse agents in comparison to playing other equilibrium solutions. Importantly, we show that our population of agents that approximate a risk-averse equilibrium is particularly effective in the presence of unseen opposing populations, especially in the case of guaranteeing a minimal level of performance which is critical to safety-aware multi-agent systems.
A Game-Theoretic Approach for Improving Generalization Ability of TSP Solvers
Oct 29, 2021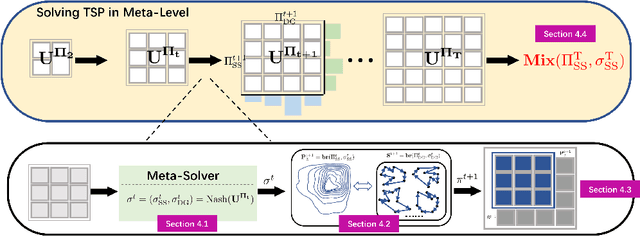
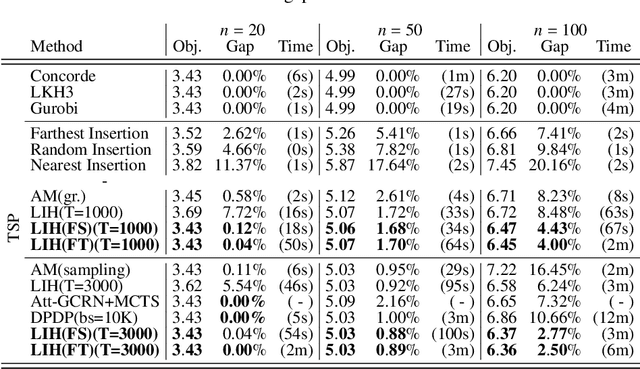
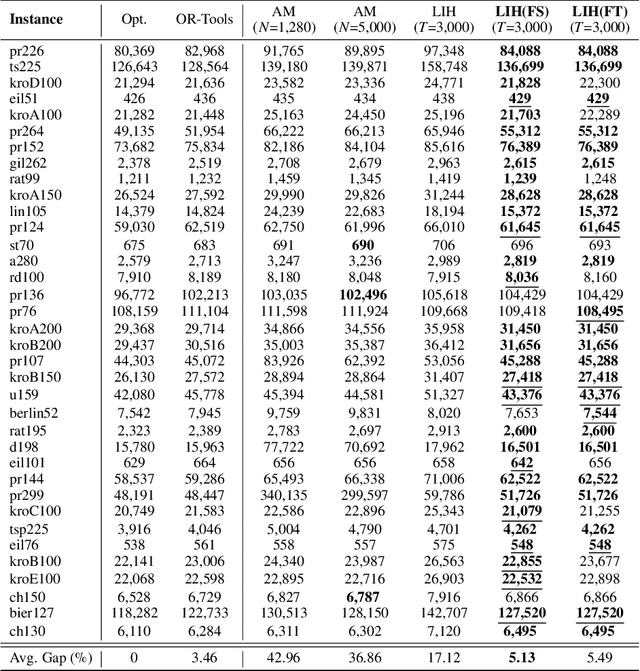
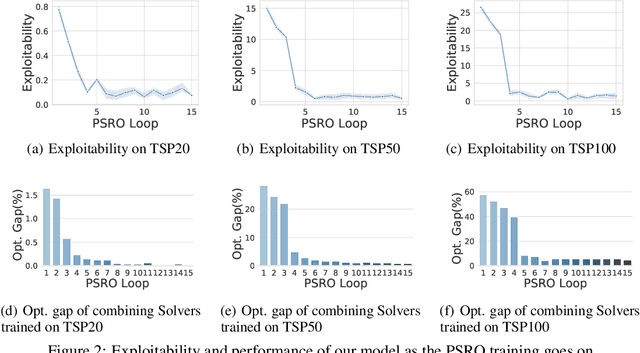
In this paper, we shed new light on the generalization ability of deep learning-based solvers for Traveling Salesman Problems (TSP). Specifically, we introduce a two-player zero-sum framework between a trainable \emph{Solver} and a \emph{Data Generator}, where the Solver aims to solve the task instances provided by the Generator, and the Generator aims to generate increasingly difficult instances for improving the Solver. Grounded in \textsl{Policy Space Response Oracle} (PSRO) methods, our two-player framework outputs a population of best-responding Solvers, over which we can mix and output a combined model that achieves the least exploitability against the Generator, and thereby the most generalizable performance on different TSP tasks. We conduct experiments on a variety of TSP instances with different types and sizes. Results suggest that our Solvers achieve the state-of-the-art performance even on tasks the Solver never meets, whilst the performance of other deep learning-based Solvers drops sharply due to over-fitting. On real-world instances from \textsc{TSPLib}, our method also attains a \textbf{12\%} improvement, in terms of optimal gap, over the best baseline model. To demonstrate the principle of our framework, we study the learning outcome of the proposed two-player game and demonstrate that the exploitability of the Solver population decreases during training, and it eventually approximates the Nash equilibrium along with the Generator.
Discovering Multi-Agent Auto-Curricula in Two-Player Zero-Sum Games
Jun 04, 2021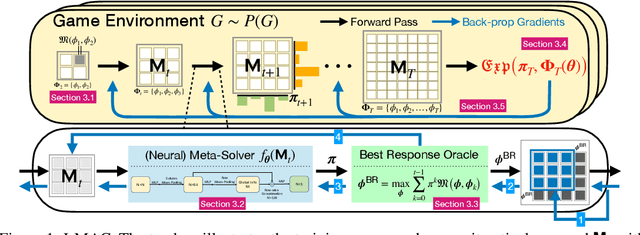
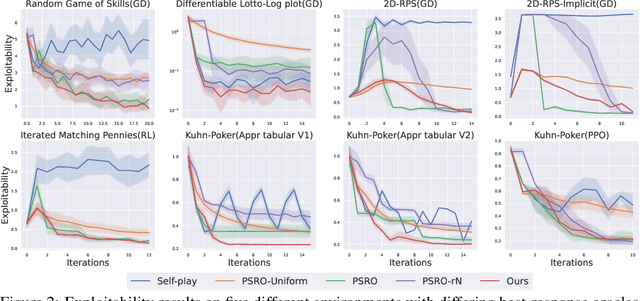

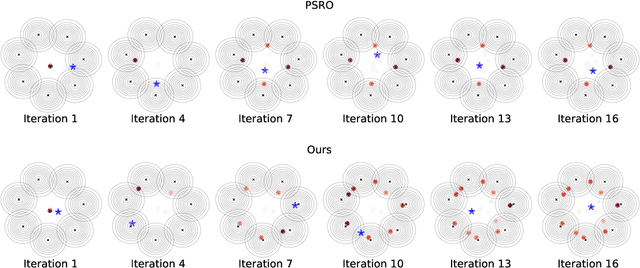
When solving two-player zero-sum games, multi-agent reinforcement learning (MARL) algorithms often create populations of agents where, at each iteration, a new agent is discovered as the best response to a mixture over the opponent population. Within such a process, the update rules of "who to compete with" (i.e., the opponent mixture) and "how to beat them" (i.e., finding best responses) are underpinned by manually developed game theoretical principles such as fictitious play and Double Oracle. In this paper we introduce a framework, LMAC, based on meta-gradient descent that automates the discovery of the update rule without explicit human design. Specifically, we parameterise the opponent selection module by neural networks and the best-response module by optimisation subroutines, and update their parameters solely via interaction with the game engine, where both players aim to minimise their exploitability. Surprisingly, even without human design, the discovered MARL algorithms achieve competitive or even better performance with the state-of-the-art population-based game solvers (e.g., PSRO) on Games of Skill, differentiable Lotto, non-transitive Mixture Games, Iterated Matching Pennies, and Kuhn Poker. Additionally, we show that LMAC is able to generalise from small games to large games, for example training on Kuhn Poker and outperforming PSRO on Leduc Poker. Our work inspires a promising future direction to discover general MARL algorithms solely from data.
Online Double Oracle
Mar 16, 2021
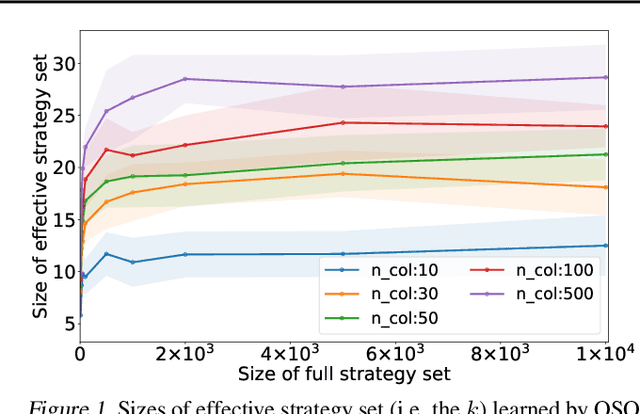
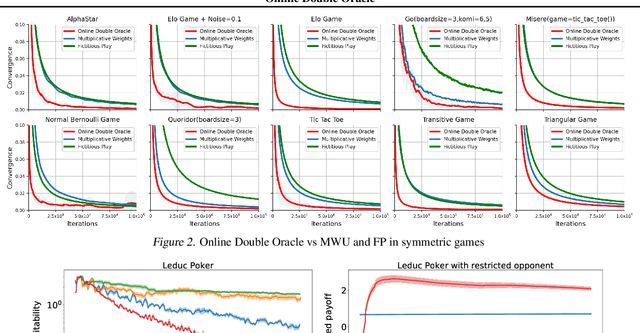
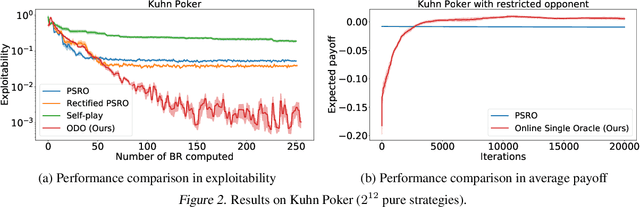
Solving strategic games whose action space is prohibitively large is a critical yet under-explored topic in economics, computer science and artificial intelligence. This paper proposes new learning algorithms in two-player zero-sum games where the number of pure strategies is huge or even infinite. Specifically, we combine no-regret analysis from online learning with double oracle methods from game theory. Our method -- \emph{Online Double Oracle (ODO)} -- achieves the regret bound of $\mathcal{O}(\sqrt{T k \log(k)})$ in self-play setting where $k$ is NOT the size of the game, but rather the size of \emph{effective strategy set} that is linearly dependent on the support size of the Nash equilibrium. On tens of different real-world games, including Leduc Poker that contains $3^{936}$ pure strategies, our methods outperform no-regret algorithms and double oracle methods by a large margin, both in convergence rate to Nash equilibrium and average payoff against strategic adversary.
Modelling Behavioural Diversity for Learning in Open-Ended Games
Mar 14, 2021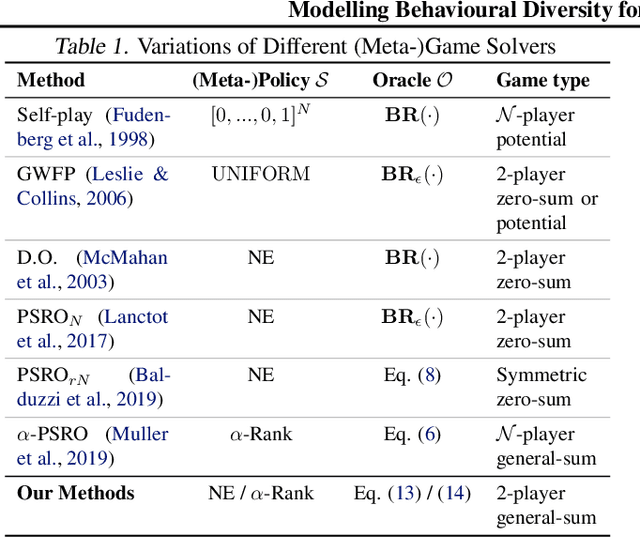

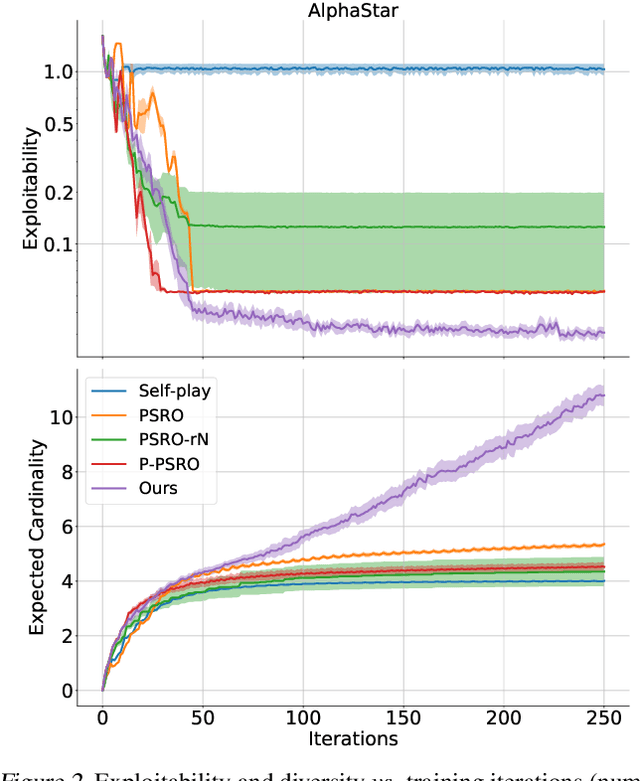
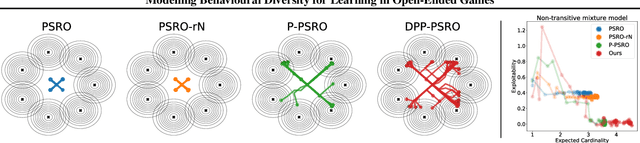
Promoting behavioural diversity is critical for solving games with non-transitive dynamics where strategic cycles exist, and there is no consistent winner (e.g., Rock-Paper-Scissors). Yet, there is a lack of rigorous treatment for defining diversity and constructing diversity-aware learning dynamics. In this work, we offer a geometric interpretation of behavioural diversity in games and introduce a novel diversity metric based on \emph{determinantal point processes} (DPP). By incorporating the diversity metric into best-response dynamics, we develop \emph{diverse fictitious play} and \emph{diverse policy-space response oracle} for solving normal-form games and open-ended games. We prove the uniqueness of the diverse best response and the convergence of our algorithms on two-player games. Importantly, we show that maximising the DPP-based diversity metric guarantees to enlarge the \emph{gamescape} -- convex polytopes spanned by agents' mixtures of strategies. To validate our diversity-aware solvers, we test on tens of games that show strong non-transitivity. Results suggest that our methods achieve much lower exploitability than state-of-the-art solvers by finding effective and diverse strategies.
Diverse Auto-Curriculum is Critical for Successful Real-World Multiagent Learning Systems
Feb 16, 2021Multiagent reinforcement learning (MARL) has achieved a remarkable amount of success in solving various types of video games. A cornerstone of this success is the auto-curriculum framework, which shapes the learning process by continually creating new challenging tasks for agents to adapt to, thereby facilitating the acquisition of new skills. In order to extend MARL methods to real-world domains outside of video games, we envision in this blue sky paper that maintaining a diversity-aware auto-curriculum is critical for successful MARL applications. Specifically, we argue that \emph{behavioural diversity} is a pivotal, yet under-explored, component for real-world multiagent learning systems, and that significant work remains in understanding how to design a diversity-aware auto-curriculum. We list four open challenges for auto-curriculum techniques, which we believe deserve more attention from this community. Towards validating our vision, we recommend modelling realistic interactive behaviours in autonomous driving as an important test bed, and recommend the SMARTS/ULTRA benchmark.