 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Double Oracle
Mar 16, 2021
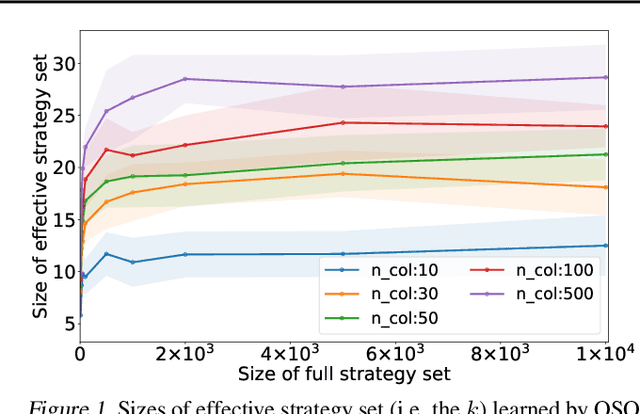
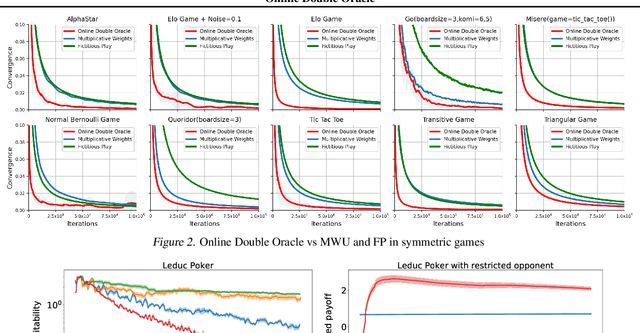
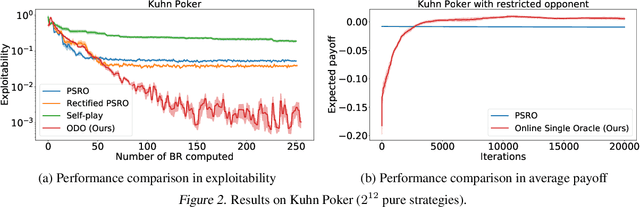
Solving strategic games whose action space is prohibitively large is a critical yet under-explored topic in economics, computer science and artificial intelligence. This paper proposes new learning algorithms in two-player zero-sum games where the number of pure strategies is huge or even infinite. Specifically, we combine no-regret analysis from online learning with double oracle methods from game theory. Our method -- \emph{Online Double Oracle (ODO)} -- achieves the regret bound of $\mathcal{O}(\sqrt{T k \log(k)})$ in self-play setting where $k$ is NOT the size of the game, but rather the size of \emph{effective strategy set} that is linearly dependent on the support size of the Nash equilibrium. On tens of different real-world games, including Leduc Poker that contains $3^{936}$ pure strategies, our methods outperform no-regret algorithms and double oracle methods by a large margin, both in convergence rate to Nash equilibrium and average payoff against strategic adversary.
Modelling Behavioural Diversity for Learning in Open-Ended Games
Mar 14, 2021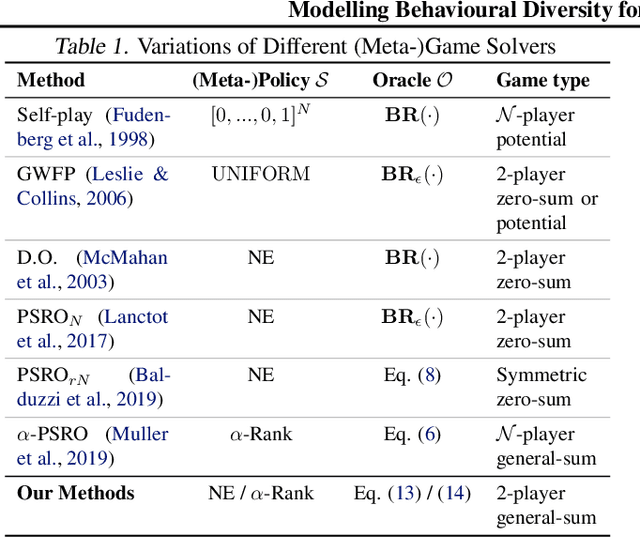

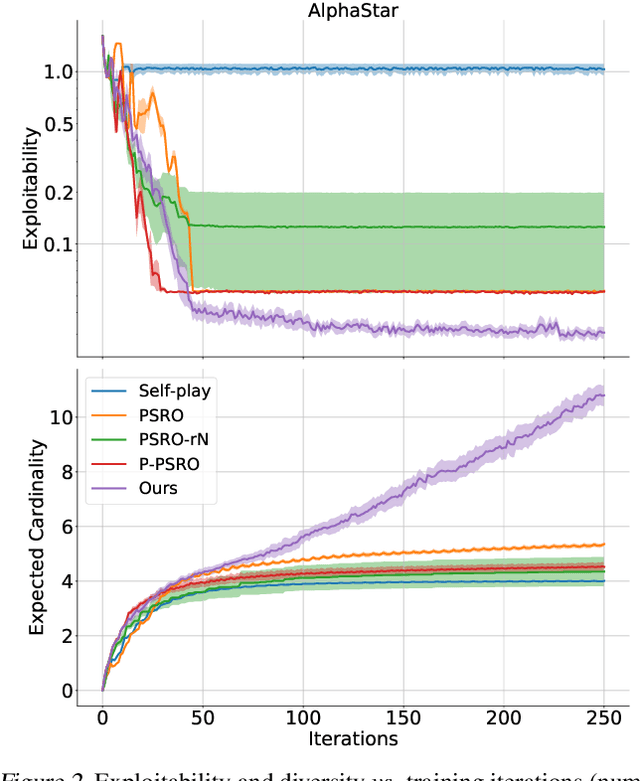
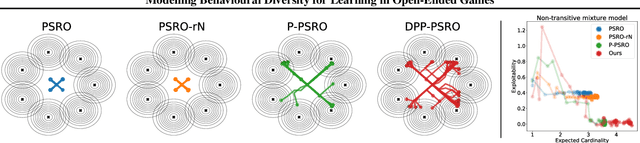
Promoting behavioural diversity is critical for solving games with non-transitive dynamics where strategic cycles exist, and there is no consistent winner (e.g., Rock-Paper-Scissors). Yet, there is a lack of rigorous treatment for defining diversity and constructing diversity-aware learning dynamics. In this work, we offer a geometric interpretation of behavioural diversity in games and introduce a novel diversity metric based on \emph{determinantal point processes} (DPP). By incorporating the diversity metric into best-response dynamics, we develop \emph{diverse fictitious play} and \emph{diverse policy-space response oracle} for solving normal-form games and open-ended games. We prove the uniqueness of the diverse best response and the convergence of our algorithms on two-player games. Importantly, we show that maximising the DPP-based diversity metric guarantees to enlarge the \emph{gamescape} -- convex polytopes spanned by agents' mixtures of strategies. To validate our diversity-aware solvers, we test on tens of games that show strong non-transitivity. Results suggest that our methods achieve much lower exploitability than state-of-the-art solvers by finding effective and diverse strategies.
SMARTS: Scalable Multi-Agent Reinforcement Learning Training School for Autonomous Driving
Nov 01, 2020
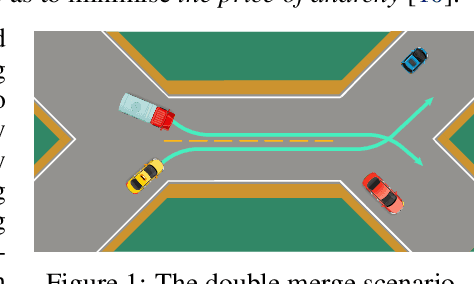
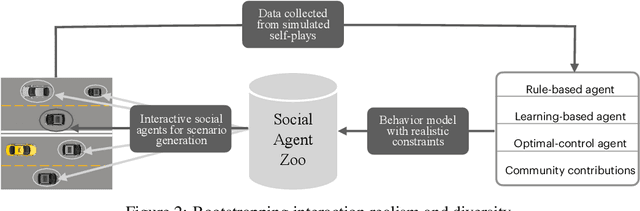
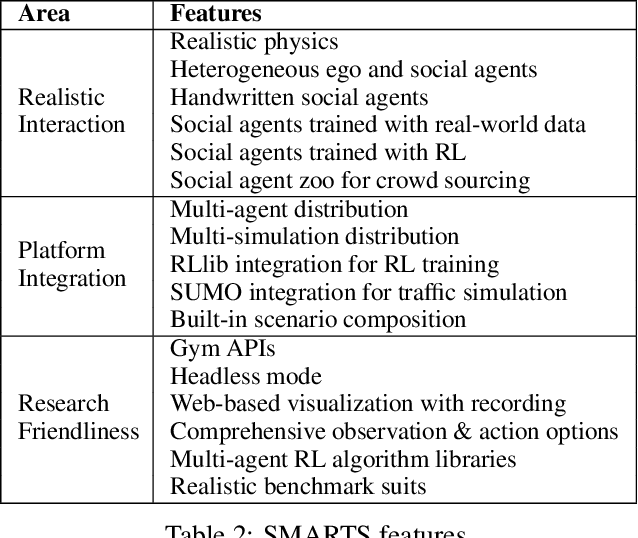
Multi-agent interaction is a fundamental aspect of autonomous driving in the real world. Despite more than a decade of research and development, the problem of how to competently interact with diverse road users in diverse scenarios remains largely unsolved. Learning methods have much to offer towards solving this problem. But they require a realistic multi-agent simulator that generates diverse and competent driving interactions. To meet this need, we develop a dedicated simulation platform called SMARTS (Scalable Multi-Agent RL Training School). SMARTS supports the training, accumulation, and use of diverse behavior models of road users. These are in turn used to create increasingly more realistic and diverse interactions that enable deeper and broader research on multi-agent interaction. In this paper, we describe the design goals of SMARTS, explain its basic architecture and its key features, and illustrate its use through concrete multi-agent experiments on interactive scenarios. We open-source the SMARTS platform and the associated benchmark tasks and evaluation metrics to encourage and empower research on multi-agent learning for autonomous driving. Our code is available at https://github.com/huawei-noah/SMARTS.