 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reinforcement Learning with Large Language Model Priors
Oct 10, 2024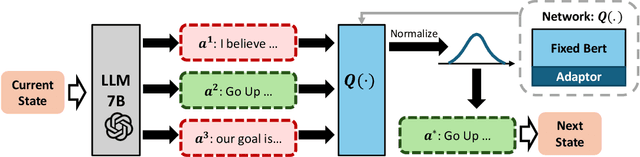
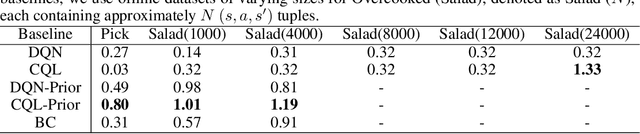
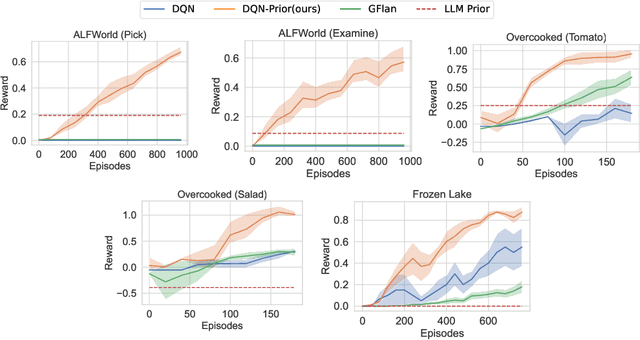
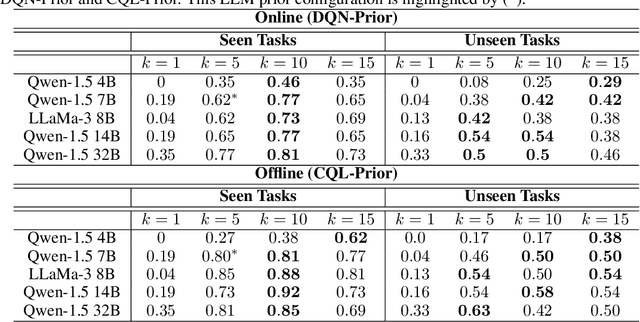
In sequential decision-making (SDM) tasks, methods like reinforcement learning (RL) and heuristic search have made notable advances in specific cases. However, they often require extensive exploration and face challenges in generalizing across diverse environments due to their limited grasp of the underlying decision dynamics. In contrast, large language models (LLMs) have recently emerged as powerful general-purpose tools, due to their capacity to maintain vast amounts of domain-specific knowledge. To harness this rich prior knowledge for efficiently solving complex SDM tasks, we propose treating LLMs as prior action distributions and integrating them into RL frameworks through Bayesian inference methods, making use of variational inference and direct posterior sampling. The proposed approaches facilitate the seamless incorporation of fixed LLM priors into both policy-based and value-based RL frameworks. Our experiments show that incorporating LLM-based action priors significantly reduces exploration and optimization complexity, substantially improving sample efficiency compared to traditional RL techniques, e.g., using LLM priors decreases the number of required samples by over 90% in offline learning scenarios.
Natural Language Reinforcement Learning
Feb 14, 2024



Reinforcement Learning (RL) has shown remarkable abilities in learning policies for decision-making tasks. However, RL is often hindered by issues such as low sample efficiency, lack of interpretability, and sparse supervision signals. To tackle these limitations, we take inspiration from the human learning process and introduce Natural Language Reinforcement Learning (NLRL), which innovatively combines RL principles with natural language representation. Specifically, NLRL redefines RL concepts like task objectives, policy, value function, Bellman equation, and policy iteration in natural language space. We present how NLRL can be practically implemented with the latest advancements in large language models (LLMs) like GPT-4. Initial experiments over tabular MDPs demonstrate the effectiveness, efficiency, and also interpretability of the NLRL framework.
Uncertainty of Thoughts: Uncertainty-Aware Planning Enhances Information Seeking in Large Language Models
Feb 05, 2024


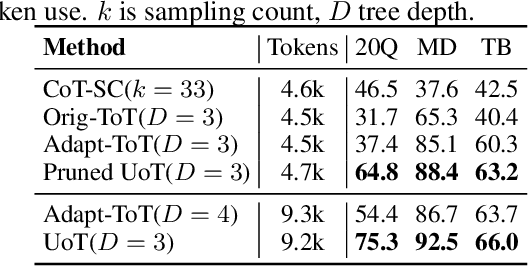
In the face of uncertainty, the ability to seek information is of fundamental importance. In many practical applications, such as medical diagnosis and troubleshooting, the information needed to solve the task is not initially given, and has to be actively sought by asking follow-up questions (for example, a doctor asking a patient for more details about their symptoms). In this work, we introduce Uncertainty of Thoughts (UoT), an algorithm to augment large language models with the ability to actively seek information by asking effective questions. UoT combines 1) an uncertainty-aware simulation approach which enables the model to simulate possible future scenarios and how likely they are to occur, 2) uncertainty-based rewards motivated by information gain which incentivizes the model to seek information, and 3) a reward propagation scheme to select the optimal question to ask in a way that maximizes the expected reward. In experiments on medical diagnosis, troubleshooting and the '20 Questions' game, UoT achieves an average performance improvement of 57.8% in the rate of successful task completion across multiple LLMs compared with direct prompting, and also improves efficiency (i.e., the number of questions needed to complete the task).
Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
Dec 22, 2023



A key method for creating Artificial Intelligence (AI) agents is Reinforcement Learning (RL). However, constructing a standalone RL policy that maps perception to action directly encounters severe problems, chief among them being its lack of generality across multiple tasks and the need for a large amount of training data. The leading cause is that it cannot effectively integrate prior information into the perception-action cycle when devising the policy. Large language models (LLMs) emerged as a fundamental way to incorporate cross-domain knowledge into AI agents but lack crucial learning and adaptation toward specific decision problems. This paper presents a general framework model for integrating and learning structured reasoning into AI agents' policies. Our methodology is motivated by the modularity found in the human brain. The framework utilises the construction of intrinsic and extrinsic functions to add previous understandings of reasoning structures. It also provides the adaptive ability to learn models inside every module or function, consistent with the modular structure of cognitive processes. We describe the framework in-depth and compare it with other AI pipelines and existing frameworks. The paper explores practical applications, covering experiments that show the effectiveness of our method. Our results indicate that AI agents perform and adapt far better when organised reasoning and prior knowledge are embedded. This opens the door to more resilient and general AI agent systems.
Alphazero-like Tree-Search can Guide Large Language Model Decoding and Training
Sep 29, 2023

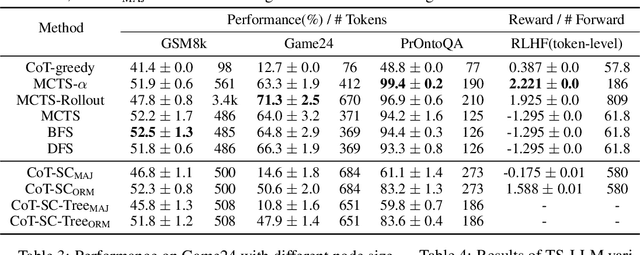
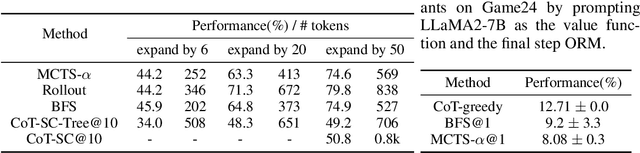
Large language models (LLMs) typically employ sampling or beam search, accompanied by prompts such as Chain-of-Thought (CoT), to boost reasoning and decoding ability. Recent work like Tree-of-Thought (ToT) and Reasoning via Planning (RAP) aim to augment the reasoning capabilities of LLMs by utilizing tree-search algorithms to guide multi-step reasoning. These methods mainly focus on LLMs' reasoning ability during inference and heavily rely on human-designed prompts to activate LLM as a value function, which lacks general applicability and scalability. To address these limitations, we present an AlphaZero-like tree-search framework for LLMs (termed TS-LLM), systematically illustrating how tree-search with a learned value function can guide LLMs' decoding ability. TS-LLM distinguishes itself in two key ways: (1) Leveraging a learned value function, our approach can be generally applied to different tasks beyond reasoning (such as RLHF alignment), and LLMs of any size, without prompting advanced, large-scale models. (2) It can guide LLM's decoding during both inference and training. Empirical evaluations across reasoning, planning, and RLHF alignment tasks validate the effectiveness of TS-LLM, even on trees with a depth of 64.
ChessGPT: Bridging Policy Learning and Language Modeling
Jun 15, 2023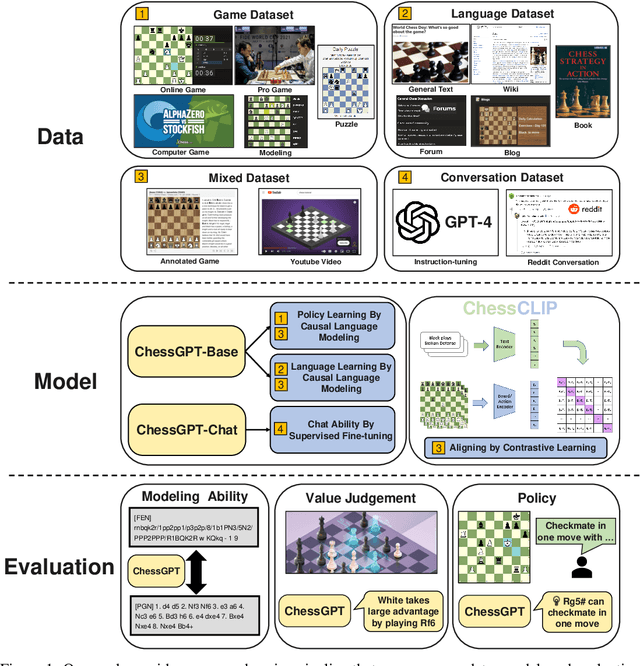
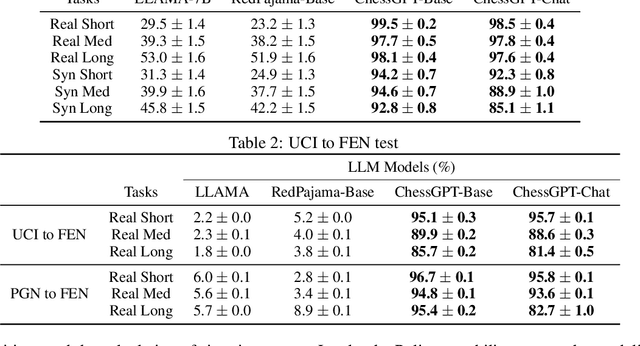
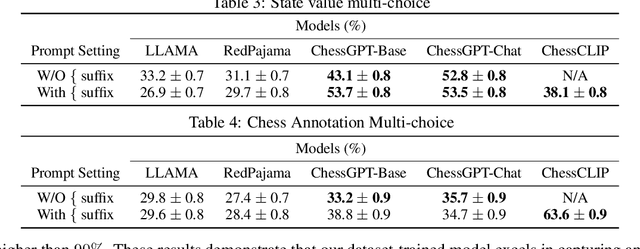
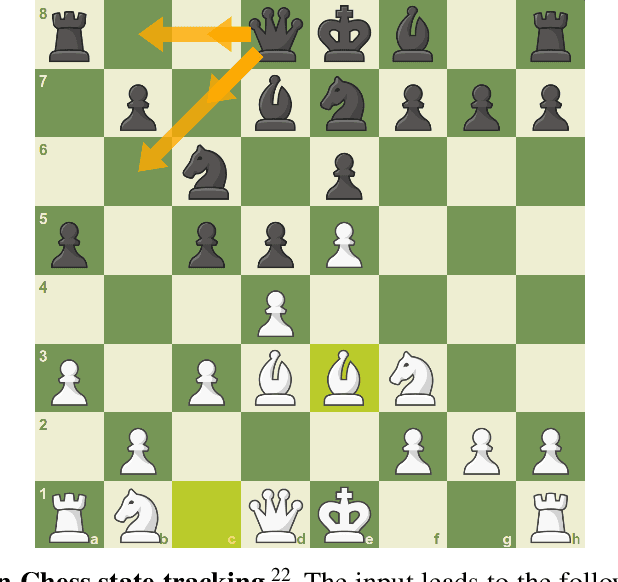
When solving decision-making tasks, humans typically depend on information from two key sources: (1) Historical policy data, which provides interaction replay from the environment, and (2) Analytical insights in natural language form, exposing the invaluable thought process or strategic considerations. Despite this, the majority of preceding research focuses on only one source: they either use historical replay exclusively to directly learn policy or value functions, or engaged in language model training utilizing mere language corpus. In this paper, we argue that a powerful autonomous agent should cover both sources. Thus, we propose ChessGPT, a GPT model bridging policy learning and language modeling by integrating data from these two sources in Chess games. Specifically, we build a large-scale game and language dataset related to chess. Leveraging the dataset, we showcase two model examples ChessCLIP and ChessGPT, integrating policy learning and language modeling. Finally, we propose a full evaluation framework for evaluating language model's chess ability. Experimental results validate our model and dataset's effectiveness. We open source our code, model, and dataset at https://github.com/waterhorse1/ChessGPT.
Contextual Transformer for Offline Meta Reinforcement Learning
Nov 15, 2022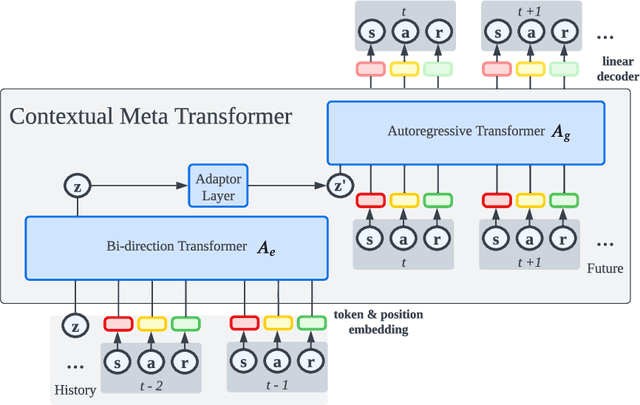
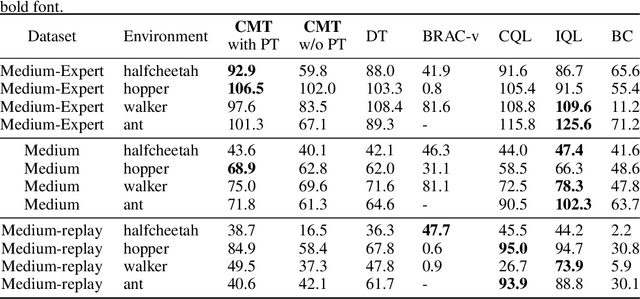
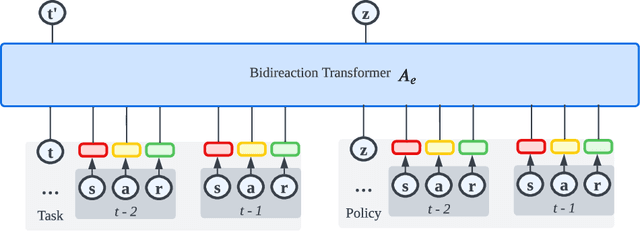
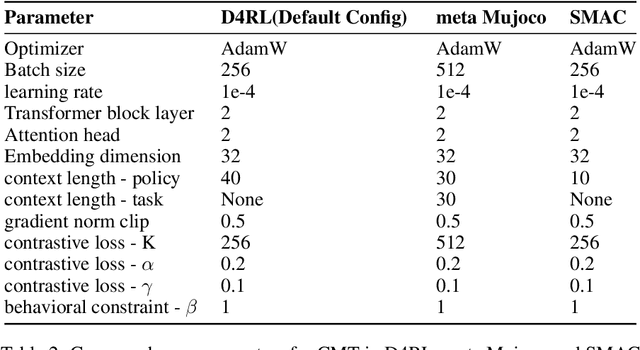
The pretrain-finetuning paradigm in large-scale sequence models has made significant progress in natural language processing and computer vision tasks. However, such a paradigm is still hindered by several challenges in Reinforcement Learning (RL), including the lack of self-supervised pretraining algorithms based on offline data and efficient fine-tuning/prompt-tuning over unseen downstream tasks. In this work, we explore how prompts can improve sequence modeling-based offline reinforcement learning (offline-RL) algorithms. Firstly, we propose prompt tuning for offline RL, where a context vector sequence is concatenated with the input to guide the conditional policy generation. As such, we can pretrain a model on the offline dataset with self-supervised loss and learn a prompt to guide the policy towards desired actions. Secondly, we extend our framework to Meta-RL settings and propose Contextual Meta Transformer (CMT); CMT leverages the context among different tasks as the prompt to improve generalization on unseen tasks. We conduct extensive experiments across three different offline-RL settings: offline single-agent RL on the D4RL dataset, offline Meta-RL on the MuJoCo benchmark, and offline MARL on the SMAC benchmark. Superior results validate the strong performance, and generality of our methods.
TorchOpt: An Efficient Library for Differentiable Optimization
Nov 13, 2022
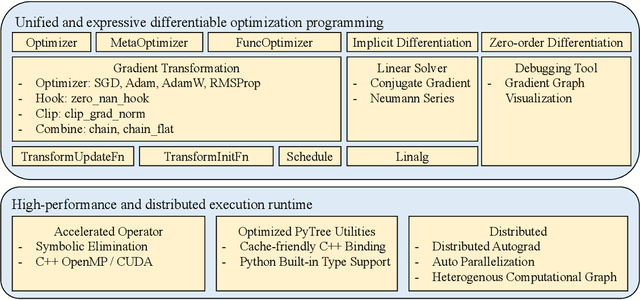
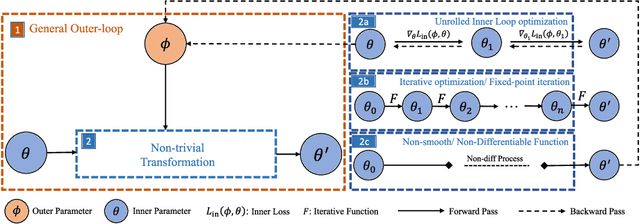

Recent years have witnessed the booming of various differentiable optimization algorithms. These algorithms exhibit different execution patterns, and their execution needs massive computational resources that go beyond a single CPU and GPU. Existing differentiable optimization libraries, however, cannot support efficient algorithm development and multi-CPU/GPU execution, making the development of differentiable optimization algorithms often cumbersome and expensive. This paper introduces TorchOpt, a PyTorch-based efficient library for differentiable optimization. TorchOpt provides a unified and expressive differentiable optimization programming abstraction. This abstraction allows users to efficiently declare and analyze various differentiable optimization programs with explicit gradients, implicit gradients, and zero-order gradients. TorchOpt further provides a high-performance distributed execution runtime. This runtime can fully parallelize computation-intensive differentiation operations (e.g. tensor tree flattening) on CPUs / GPUs and automatically distribute computation to distributed devices. Experimental results show that TorchOpt achieves $5.2\times$ training time speedup on an 8-GPU server. TorchOpt is available at: https://github.com/metaopt/torchopt/.
Heterogeneous-Agent Mirror Learning: A Continuum of Solutions to Cooperative MARL
Aug 02, 2022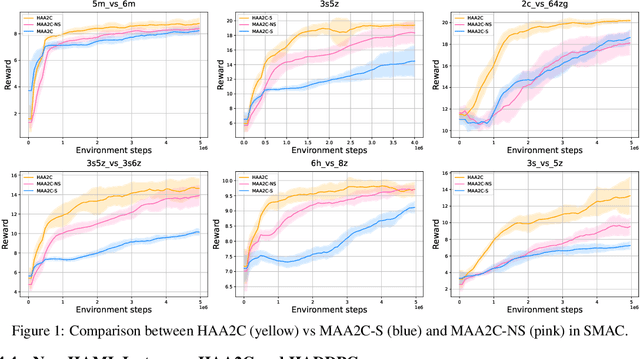


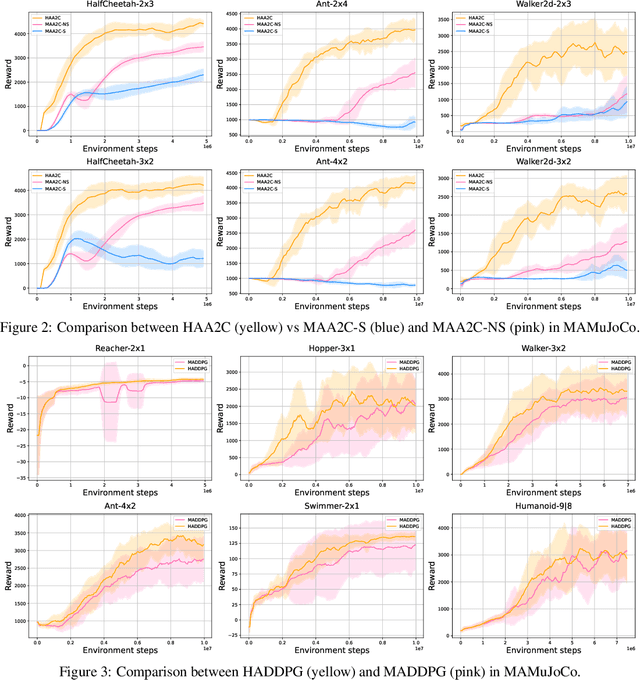
The necessity for cooperation among intelligent machines has popularised cooperative multi-agent reinforcement learning (MARL) in the artificial intelligence (AI) research community. However, many research endeavors have been focused on developing practical MARL algorithms whose effectiveness has been studied only empirically, thereby lacking theoretical guarantees. As recent studies have revealed, MARL methods often achieve performance that is unstable in terms of reward monotonicity or suboptimal at convergence. To resolve these issues, in this paper, we introduce a novel framework named Heterogeneous-Agent Mirror Learning (HAML) that provides a general template for MARL algorithmic designs. We prove that algorithms derived from the HAML template satisfy the desired properties of the monotonic improvement of the joint reward and the convergence to Nash equilibrium. We verify the practicality of HAML by proving that the current state-of-the-art cooperative MARL algorithms, HATRPO and HAPPO, are in fact HAML instances. Next, as a natural outcome of our theory, we propose HAML extensions of two well-known RL algorithms, HAA2C (for A2C) and HADDPG (for DDPG), and demonstrate their effectiveness against strong baselines on StarCraftII and Multi-Agent MuJoCo tasks.
Towards Human-Level Bimanual Dexterous Manipulation with Reinforcement Learning
Jun 17, 2022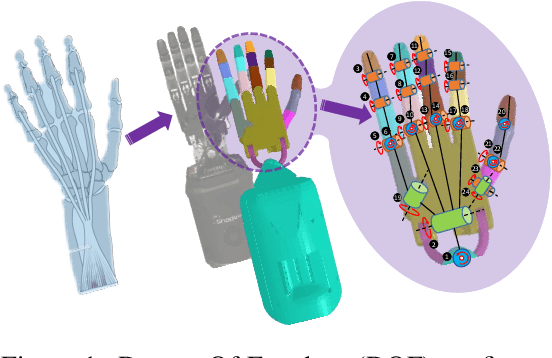
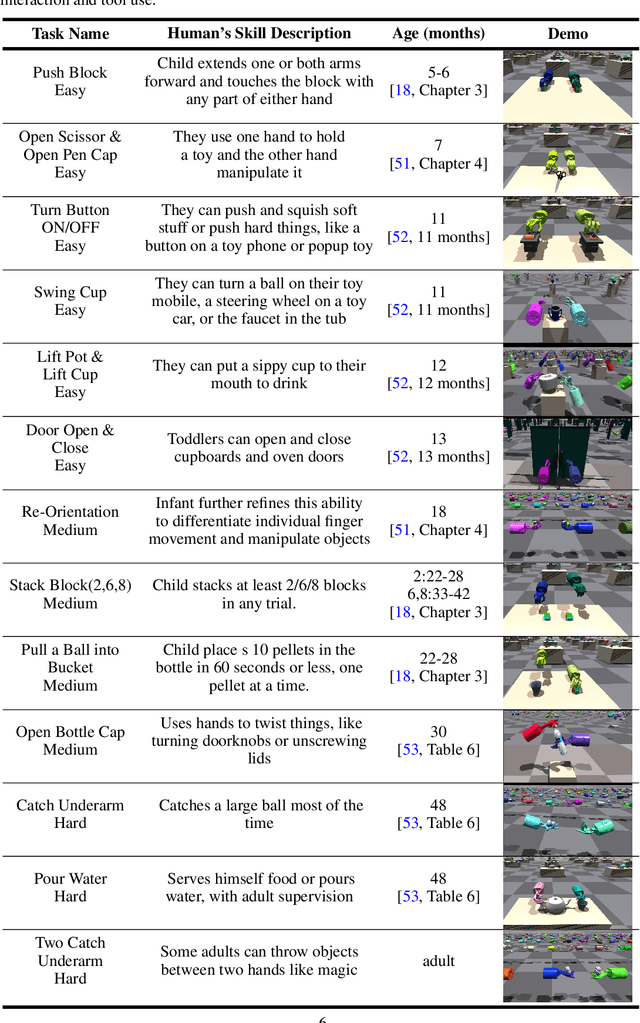


Achieving human-level dexterity is an important open problem in robotics. However, tasks of dexterous hand manipulation, even at the baby level, are challenging to solve through reinforcement learning (RL). The difficulty lies in the high degrees of freedom and the required cooperation among heterogeneous agents (e.g., joints of fingers). In this study, we propose the Bimanual Dexterous Hands Benchmark (Bi-DexHands), a simulator that involves two dexterous hands with tens of bimanual manipulation tasks and thousands of target objects. Specifically, tasks in Bi-DexHands are designed to match different levels of human motor skills according to cognitive science literature. We built Bi-DexHands in the Issac Gym; this enables highly efficient RL training, reaching 30,000+ FPS by only one single NVIDIA RTX 3090. We provide a comprehensive benchmark for popular RL algorithms under different settings; this includes Single-agent/Multi-agent RL, Offline RL, Multi-task RL, and Meta RL. Our results show that the PPO type of on-policy algorithms can master simple manipulation tasks that are equivalent up to 48-month human babies (e.g., catching a flying object, opening a bottle), while multi-agent RL can further help to master manipulations that require skilled bimanual cooperation (e.g., lifting a pot, stacking blocks). Despite the success on each single task, when it comes to acquiring multiple manipulation skills, existing RL algorithms fail to work in most of the multi-task and the few-shot learning settings, which calls for more substantial development from the RL community. Our project is open sourced at https://github.com/PKU-MARL/DexterousHands.