 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Transformer for Offline Meta Reinforcement Learning
Nov 15, 2022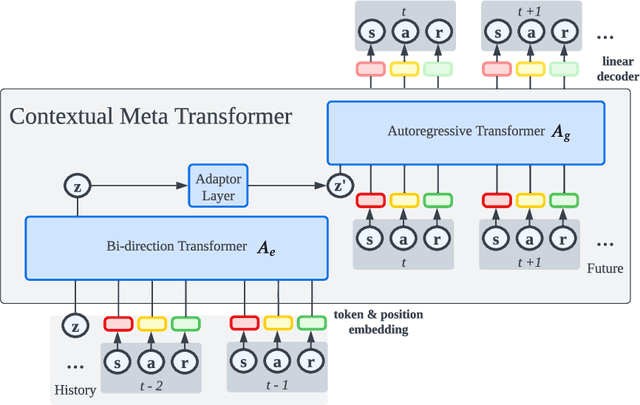
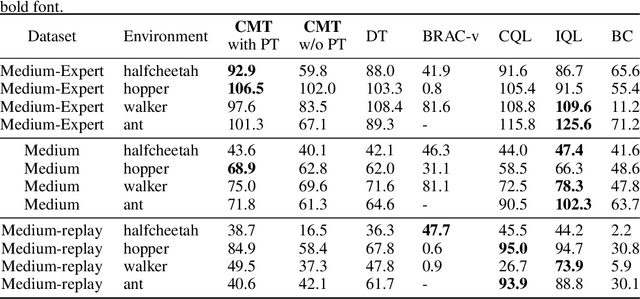
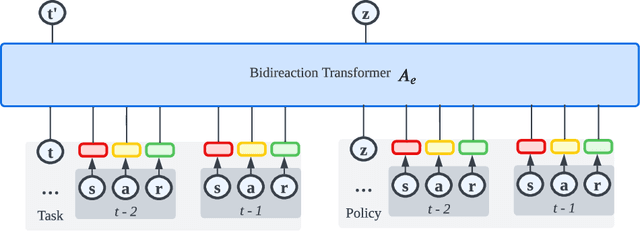
The pretrain-finetuning paradigm in large-scale sequence models has made significant progress in natural language processing and computer vision tasks. However, such a paradigm is still hindered by several challenges in Reinforcement Learning (RL), including the lack of self-supervised pretraining algorithms based on offline data and efficient fine-tuning/prompt-tuning over unseen downstream tasks. In this work, we explore how prompts can improve sequence modeling-based offline reinforcement learning (offline-RL) algorithms. Firstly, we propose prompt tuning for offline RL, where a context vector sequence is concatenated with the input to guide the conditional policy generation. As such, we can pretrain a model on the offline dataset with self-supervised loss and learn a prompt to guide the policy towards desired actions. Secondly, we extend our framework to Meta-RL settings and propose Contextual Meta Transformer (CMT); CMT leverages the context among different tasks as the prompt to improve generalization on unseen tasks. We conduct extensive experiments across three different offline-RL settings: offline single-agent RL on the D4RL dataset, offline Meta-RL on the MuJoCo benchmark, and offline MARL on the SMAC benchmark. Superior results validate the strong performance, and generality of our methods.