 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphazero-like Tree-Search can Guide Large Language Model Decoding and Training
Paper and Code


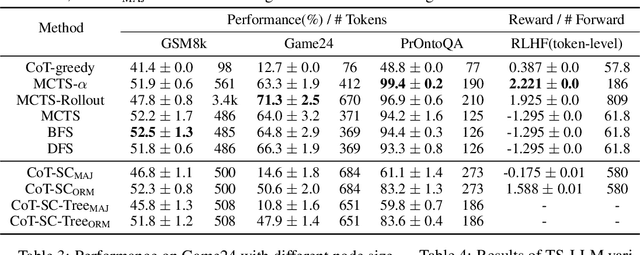
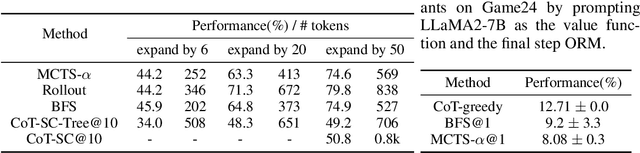
Large language models (LLMs) typically employ sampling or beam search, accompanied by prompts such as Chain-of-Thought (CoT), to boost reasoning and decoding ability. Recent work like Tree-of-Thought (ToT) and Reasoning via Planning (RAP) aim to augment the reasoning capabilities of LLMs by utilizing tree-search algorithms to guide multi-step reasoning. These methods mainly focus on LLMs' reasoning ability during inference and heavily rely on human-designed prompts to activate LLM as a value function, which lacks general applicability and scalability. To address these limitations, we present an AlphaZero-like tree-search framework for LLMs (termed TS-LLM), systematically illustrating how tree-search with a learned value function can guide LLMs' decoding ability. TS-LLM distinguishes itself in two key ways: (1) Leveraging a learned value function, our approach can be generally applied to different tasks beyond reasoning (such as RLHF alignment), and LLMs of any size, without prompting advanced, large-scale models. (2) It can guide LLM's decoding during both inference and training. Empirical evaluations across reasoning, planning, and RLHF alignment tasks validate the effectiveness of TS-LLM, even on trees with a depth of 64.