 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty of Thoughts: Uncertainty-Aware Planning Enhances Information Seeking in Large Language Models
Paper and Code



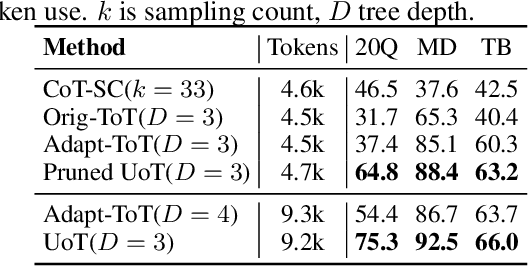
In the face of uncertainty, the ability to seek information is of fundamental importance. In many practical applications, such as medical diagnosis and troubleshooting, the information needed to solve the task is not initially given, and has to be actively sought by asking follow-up questions (for example, a doctor asking a patient for more details about their symptoms). In this work, we introduce Uncertainty of Thoughts (UoT), an algorithm to augment large language models with the ability to actively seek information by asking effective questions. UoT combines 1) an uncertainty-aware simulation approach which enables the model to simulate possible future scenarios and how likely they are to occur, 2) uncertainty-based rewards motivated by information gain which incentivizes the model to seek information, and 3) a reward propagation scheme to select the optimal question to ask in a way that maximizes the expected reward. In experiments on medical diagnosis, troubleshooting and the '20 Questions' game, UoT achieves an average performance improvement of 57.8% in the rate of successful task completion across multiple LLMs compared with direct prompting, and also improves efficiency (i.e., the number of questions needed to complete the task).