 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim2Sea: Sim-to-Real Policy Transfer for Maritime Vessel Navigation in Congested Waters
Mar 04, 2026Autonomous navigation in congested maritime environments is a critical capability for a wide range of real-world applications. However, it remains an unresolved challenge due to complex vessel interactions and significant environmental uncertainties. Existing methods often fail in practical deployment due to a substantial sim-to-real gap, which stems from imprecise simulation, inadequate situational awareness, and unsafe exploration strategies. To address these, we propose \textbf{Sim2Sea}, a comprehensive framework designed to bridge simulation and real-world execution. Sim2Sea advances in three key aspects. First, we develop a GPU-accelerated parallel simulator for scalable and accurate maritime scenario simulation. Second, we design a dual-stream spatiotemporal policy that handles complex dynamics and multi-modal perception, augmented with a velocity-obstacle-guided action masking mechanism to ensure safe and efficient exploration. Finally, a targeted domain randomization scheme helps bridge the sim-to-real gap. Simulation results demonstrate that our method achieves faster convergence and safer trajectories than established baselines. In addition, our policy trained purely in simulation successfully transfers zero-shot to a 17-ton unmanned vessel operating in real-world congested waters. These results validate the effectiveness of Sim2Sea in achieving reliable sim-to-real transfer for practical autonomous maritime navigation.
Efficient Reinforcement Learning with Large Language Model Priors
Oct 10, 2024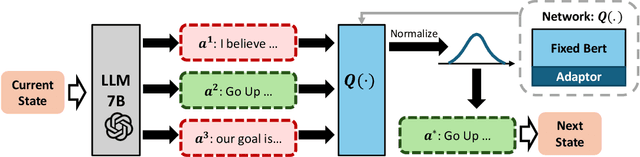
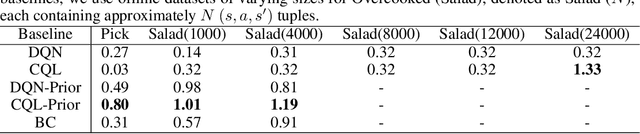
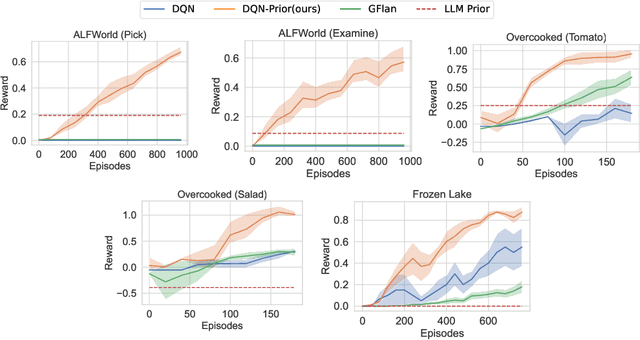
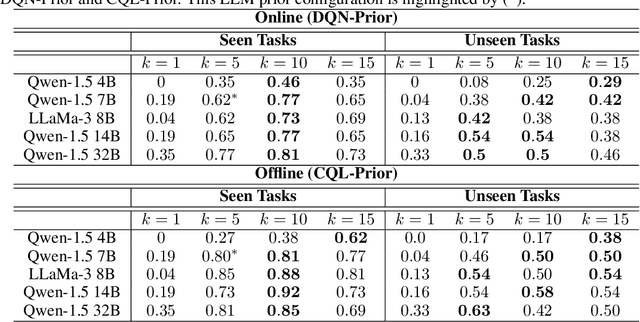
In sequential decision-making (SDM) tasks, methods like reinforcement learning (RL) and heuristic search have made notable advances in specific cases. However, they often require extensive exploration and face challenges in generalizing across diverse environments due to their limited grasp of the underlying decision dynamics. In contrast, large language models (LLMs) have recently emerged as powerful general-purpose tools, due to their capacity to maintain vast amounts of domain-specific knowledge. To harness this rich prior knowledge for efficiently solving complex SDM tasks, we propose treating LLMs as prior action distributions and integrating them into RL frameworks through Bayesian inference methods, making use of variational inference and direct posterior sampling. The proposed approaches facilitate the seamless incorporation of fixed LLM priors into both policy-based and value-based RL frameworks. Our experiments show that incorporating LLM-based action priors significantly reduces exploration and optimization complexity, substantially improving sample efficiency compared to traditional RL techniques, e.g., using LLM priors decreases the number of required samples by over 90% in offline learning scenarios.
Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach
Dec 19, 2023



StarCraft II is a challenging benchmark for AI agents due to the necessity of both precise micro level operations and strategic macro awareness. Previous works, such as Alphastar and SCC, achieve impressive performance on tackling StarCraft II , however, still exhibit deficiencies in long term strategic planning and strategy interpretability. Emerging large language model (LLM) agents, such as Voyage and MetaGPT, presents the immense potential in solving intricate tasks. Motivated by this, we aim to validate the capabilities of LLMs on StarCraft II, a highly complex RTS game.To conveniently take full advantage of LLMs` reasoning abilities, we first develop textual StratCraft II environment, called TextStarCraft II, which LLM agent can interact. Secondly, we propose a Chain of Summarization method, including single frame summarization for processing raw observations and multi frame summarization for analyzing game information, providing command recommendations, and generating strategic decisions. Our experiment consists of two parts: first, an evaluation by human experts, which includes assessing the LLMs`s mastery of StarCraft II knowledge and the performance of LLM agents in the game; second, the in game performance of LLM agents, encompassing aspects like win rate and the impact of Chain of Summarization.Experiment results demonstrate that: 1. LLMs possess the relevant knowledge and complex planning abilities needed to address StarCraft II scenarios; 2. Human experts consider the performance of LLM agents to be close to that of an average player who has played StarCraft II for eight years; 3. LLM agents are capable of defeating the built in AI at the Harder(Lv5) difficulty level. We have open sourced the code and released demo videos of LLM agent playing StarCraft II.
Ask more, know better: Reinforce-Learned Prompt Questions for Decision Making with Large Language Models
Oct 27, 2023Large language models (LLMs) demonstrate their promise in tackling complicated practical challenges by combining action-based policies with chain of thought (CoT) reasoning. Having high-quality prompts on hand, however, is vital to the framework's effectiveness. Currently, these prompts are handcrafted utilizing extensive human labor, resulting in CoT policies that frequently fail to generalize. Human intervention is also required in order to develop grounding functions that ensure low-level controllers appropriately process CoT reasoning. In this paper, we take the first step towards a fully integrated end-to-end framework for task-solving in real settings employing complicated reasoning. To that purpose, we offer a new leader-follower bilevel framework capable of learning to ask relevant questions (prompts) and subsequently undertaking reasoning to guide the learning of actions to be performed in an environment. A good prompt should make introspective revisions based on historical findings, leading the CoT to consider the anticipated goals. A prompt-generator policy has its own aim in our system, allowing it to adapt to the action policy and automatically root the CoT process towards outputs that lead to decisive, high-performing actions. Meanwhile, the action policy is learning how to use the CoT outputs to take specific actions. Our empirical data reveal that our system outperforms leading methods in agent learning benchmarks such as Overcooked and FourRoom.
Learning to Identify Top Elo Ratings: A Dueling Bandits Approach
Jan 20, 2022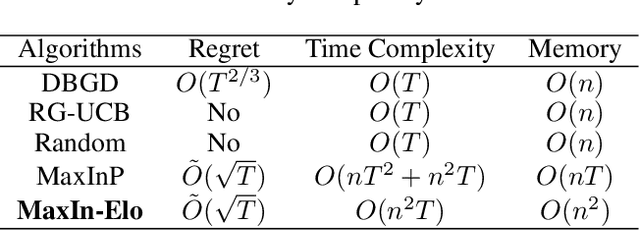
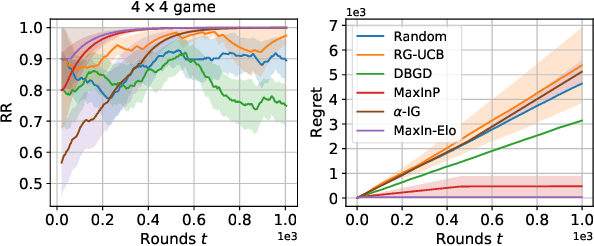
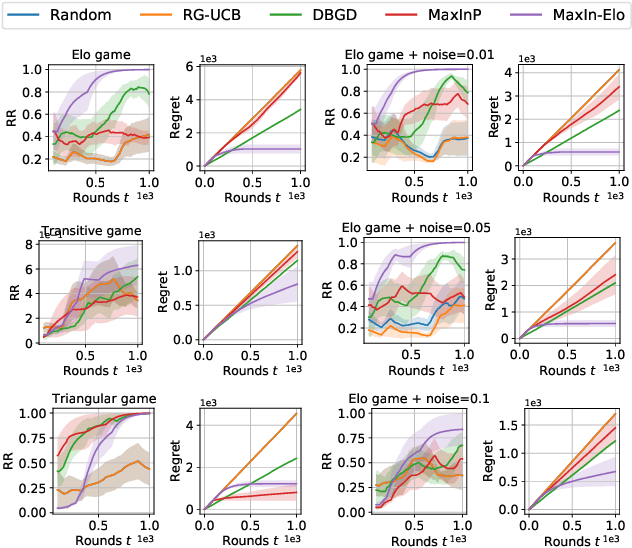
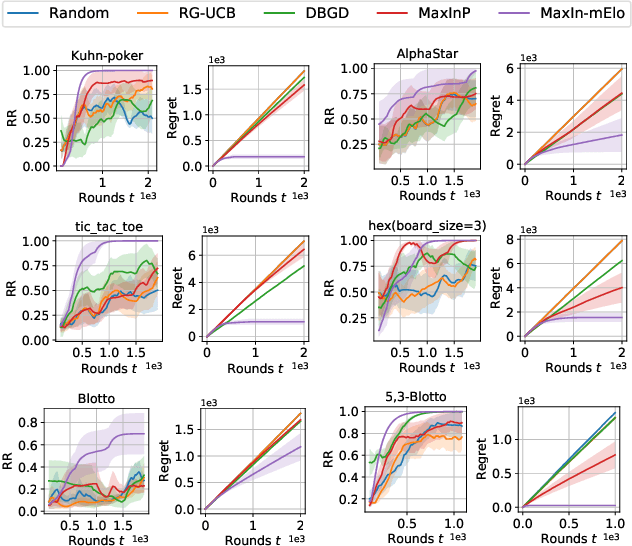
The Elo rating system is widely adopted to evaluate the skills of (chess) game and sports players. Recently it has been also integrated into machine learning algorithms in evaluating the performance of computerised AI agents. However, an accurate estimation of the Elo rating (for the top players) often requires many rounds of competitions, which can be expensive to carry out. In this paper, to improve the sample efficiency of the Elo evaluation (for top players), we propose an efficient online match scheduling algorithm. Specifically, we identify and match the top players through a dueling bandits framework and tailor the bandit algorithm to the gradient-based update of Elo. We show that it reduces the per-step memory and time complexity to constant, compared to the traditional likelihood maximization approaches requiring $O(t)$ time. Our algorithm has a regret guarantee of $\tilde{O}(\sqrt{T})$, sublinear in the number of competition rounds and has been extended to the multidimensional Elo ratings for handling intransitive games. We empirically demonstrate that our method achieves superior convergence speed and time efficiency on a variety of gaming tasks.