 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Next Token Prediction: A Multilingual Benchmark for Personalized Response Generation
Oct 16, 2025



Large language models (LLMs) excel at general next-token prediction but still struggle to generate responses that reflect how individuals truly communicate, such as replying to emails or social messages in their own style. However, real SNS or email histories are difficult to collect due to privacy concerns. To address this, we propose the task of "Your Next Token Prediction (YNTP)", which models a user's precise word choices through controlled human-agent conversations. We build a multilingual benchmark of 100 dialogue sessions across English, Japanese, and Chinese, where users interact for five days with psychologically grounded NPCs based on MBTI dimensions. This setup captures natural, daily-life communication patterns and enables analysis of users' internal models. We evaluate prompt-based and fine-tuning-based personalization methods, establishing the first benchmark for YNTP and a foundation for user-aligned language modeling. The dataset is available at: https://github.com/AnonymousHub4Submissions/your-next-token-prediction-dataset-100
Self-Agreement: A Framework for Fine-tuning Language Models to Find Agreement among Diverse Opinions
May 19, 2023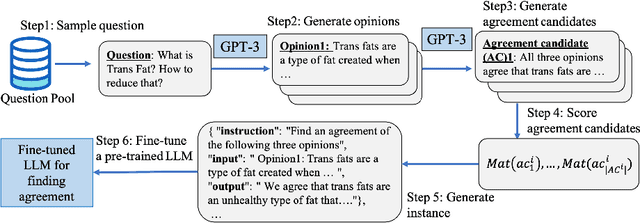
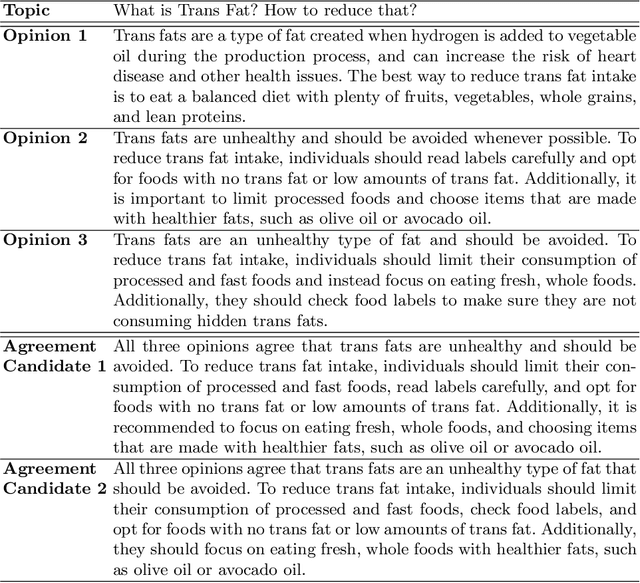
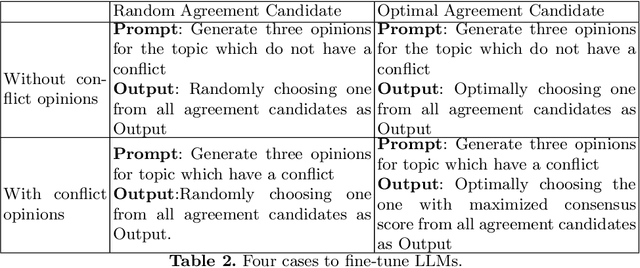
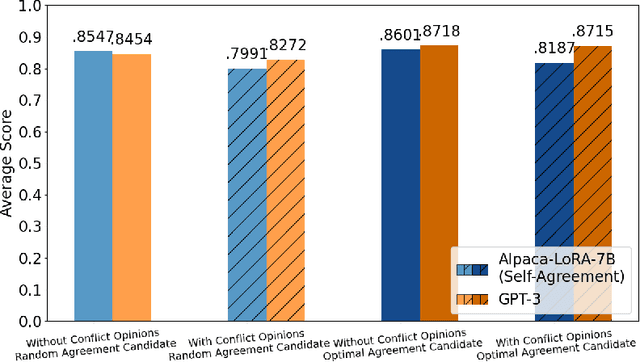
Finding an agreement among diverse opinions is a challenging topic in multiagent systems. Recently, large language models (LLMs) have shown great potential in addressing this challenge due to their remarkable capabilities in comprehending human opinions and generating human-like text. However, they typically rely on extensive human-annotated data. In this paper, we propose Self-Agreement, a novel framework for fine-tuning LLMs to autonomously find agreement using data generated by LLM itself. Specifically, our approach employs the generative pre-trained transformer-3 (GPT-3) to generate multiple opinions for each question in a question dataset and create several agreement candidates among these opinions. Then, a bidirectional encoder representations from transformers (BERT)-based model evaluates the agreement score of each agreement candidate and selects the one with the highest agreement score. This process yields a dataset of question-opinion-agreements, which we use to fine-tune a pre-trained LLM for discovering agreements among diverse opinions. Remarkably, a pre-trained LLM fine-tuned by our Self-Agreement framework achieves comparable performance to GPT-3 with only 1/25 of its parameters, showcasing its ability to identify agreement among various opinions without the need for human-annotated data.
Heterogeneous-Agent Mirror Learning: A Continuum of Solutions to Cooperative MARL
Aug 02, 2022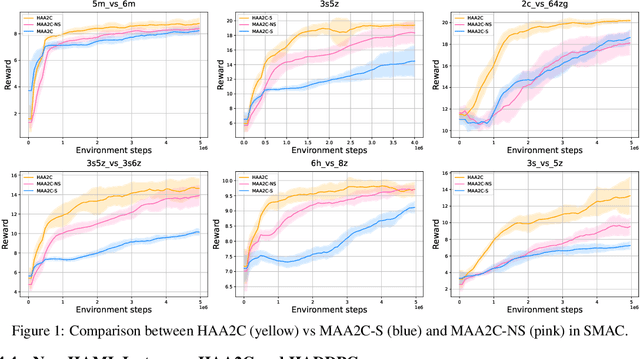


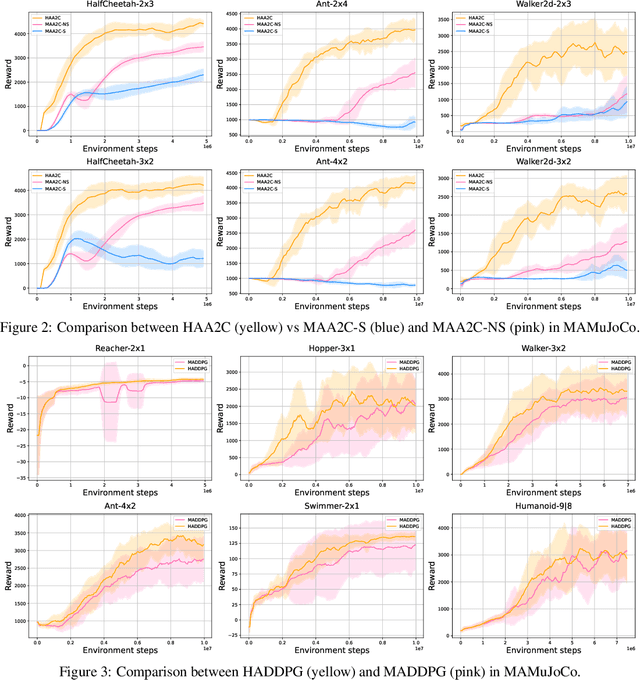
The necessity for cooperation among intelligent machines has popularised cooperative multi-agent reinforcement learning (MARL) in the artificial intelligence (AI) research community. However, many research endeavors have been focused on developing practical MARL algorithms whose effectiveness has been studied only empirically, thereby lacking theoretical guarantees. As recent studies have revealed, MARL methods often achieve performance that is unstable in terms of reward monotonicity or suboptimal at convergence. To resolve these issues, in this paper, we introduce a novel framework named Heterogeneous-Agent Mirror Learning (HAML) that provides a general template for MARL algorithmic designs. We prove that algorithms derived from the HAML template satisfy the desired properties of the monotonic improvement of the joint reward and the convergence to Nash equilibrium. We verify the practicality of HAML by proving that the current state-of-the-art cooperative MARL algorithms, HATRPO and HAPPO, are in fact HAML instances. Next, as a natural outcome of our theory, we propose HAML extensions of two well-known RL algorithms, HAA2C (for A2C) and HADDPG (for DDPG), and demonstrate their effectiveness against strong baselines on StarCraftII and Multi-Agent MuJoCo tasks.