 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAppVLM: A Lightweight Vision Language Model for Online App Control
Feb 10, 2025



The utilisation of foundation models as smartphone assistants, termed app agents, is a critical research challenge. These agents aim to execute human instructions on smartphones by interpreting textual instructions and performing actions via the device's interface. While promising, current approaches face significant limitations. Methods that use large proprietary models, such as GPT-4o, are computationally expensive, while those that use smaller fine-tuned models often lack adaptability to out-of-distribution tasks. In this work, we introduce AppVLM, a lightweight Vision-Language Model (VLM). First, we fine-tune it offline on the AndroidControl dataset. Then, we refine its policy by collecting data from the AndroidWorld environment and performing further training iterations. Our results indicate that AppVLM achieves the highest action prediction accuracy in offline evaluation on the AndroidControl dataset, compared to all evaluated baselines, and matches GPT-4o in online task completion success rate in the AndroidWorld environment, while being up to ten times faster. This makes AppVLM a practical and efficient solution for real-world deployment.
Lightweight Neural App Control
Oct 23, 2024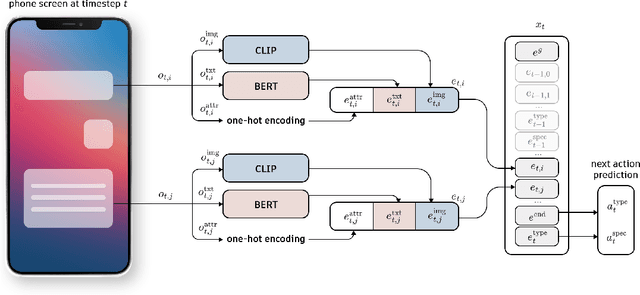
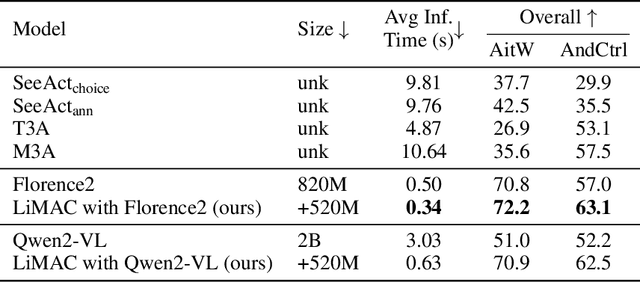
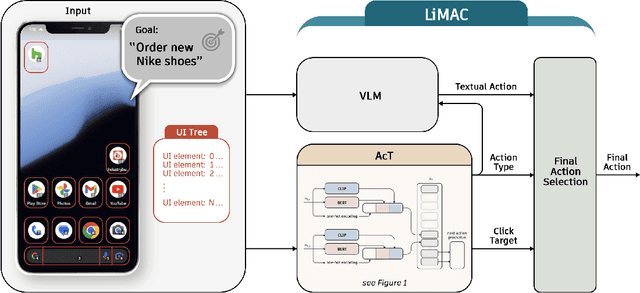
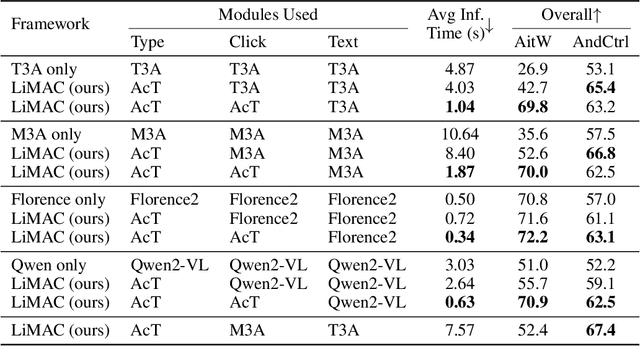
This paper introduces a novel mobile phone control architecture, termed ``app agents", for efficient interactions and controls across various Android apps. The proposed Lightweight Multi-modal App Control (LiMAC) takes as input a textual goal and a sequence of past mobile observations, such as screenshots and corresponding UI trees, to generate precise actions. To address the computational constraints inherent to smartphones, within LiMAC, we introduce a small Action Transformer (AcT) integrated with a fine-tuned vision-language model (VLM) for real-time decision-making and task execution. We evaluate LiMAC on two open-source mobile control datasets, demonstrating the superior performance of our small-form-factor approach against fine-tuned versions of open-source VLMs, such as Florence2 and Qwen2-VL. It also significantly outperforms prompt engineering baselines utilising closed-source foundation models like GPT-4o. More specifically, LiMAC increases the overall action accuracy by up to 19% compared to fine-tuned VLMs, and up to 42% compared to prompt-engineering baselines.
Bayesian Reward Models for LLM Alignment
Feb 20, 2024


To ensure that large language model (LLM) responses are helpful and non-toxic, we usually fine-tune a reward model on human preference data. We then select policy responses with high rewards (best-of-n sampling) or further optimize the policy to produce responses with high rewards (reinforcement learning from human feedback). However, this process is vulnerable to reward overoptimization or hacking, in which the responses selected have high rewards due to errors in the reward model rather than a genuine preference. This is especially problematic as the prompt or response diverges from the training data. It should be possible to mitigate these issues by training a Bayesian reward model, which signals higher uncertainty further from the training data distribution. Therefore, we trained Bayesian reward models using Laplace-LoRA (Yang et al., 2024) and found that the resulting uncertainty estimates can successfully mitigate reward overoptimization in best-of-n sampling.
Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
Dec 22, 2023



A key method for creating Artificial Intelligence (AI) agents is Reinforcement Learning (RL). However, constructing a standalone RL policy that maps perception to action directly encounters severe problems, chief among them being its lack of generality across multiple tasks and the need for a large amount of training data. The leading cause is that it cannot effectively integrate prior information into the perception-action cycle when devising the policy. Large language models (LLMs) emerged as a fundamental way to incorporate cross-domain knowledge into AI agents but lack crucial learning and adaptation toward specific decision problems. This paper presents a general framework model for integrating and learning structured reasoning into AI agents' policies. Our methodology is motivated by the modularity found in the human brain. The framework utilises the construction of intrinsic and extrinsic functions to add previous understandings of reasoning structures. It also provides the adaptive ability to learn models inside every module or function, consistent with the modular structure of cognitive processes. We describe the framework in-depth and compare it with other AI pipelines and existing frameworks. The paper explores practical applications, covering experiments that show the effectiveness of our method. Our results indicate that AI agents perform and adapt far better when organised reasoning and prior knowledge are embedded. This opens the door to more resilient and general AI agent systems.
Reward Model Ensembles Help Mitigate Overoptimization
Oct 04, 2023Reinforcement learning from human feedback (RLHF) is a standard approach for fine-tuning large language models to follow instructions. As part of this process, learned reward models are used to approximately model human preferences. However, as imperfect representations of the "true" reward, these learned reward models are susceptible to \textit{overoptimization}. Gao et al. (2023) studied this phenomenon in a synthetic human feedback setup with a significantly larger "gold" reward model acting as the true reward (instead of humans) and showed that overoptimization remains a persistent problem regardless of the size of the proxy reward model and training data used. Using a similar setup, we conduct a systematic study to evaluate the efficacy of using ensemble-based conservative optimization objectives, specifically worst-case optimization (WCO) and uncertainty-weighted optimization (UWO), for mitigating reward model overoptimization when using two optimization methods: (a) best-of-n sampling (BoN) (b) proximal policy optimization (PPO). We additionally extend the setup of Gao et al. (2023) to include 25% label noise to better mirror real-world conditions. Both with and without label noise, we find that conservative optimization practically eliminates overoptimization and improves performance by up to 70% for BoN sampling. For PPO, ensemble-based conservative optimization always reduces overoptimization and outperforms single reward model optimization. Moreover, combining it with a small KL penalty successfully prevents overoptimization at no performance cost. Overall, our results demonstrate that ensemble-based conservative optimization can effectively counter overoptimization.