 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Arena: Trace Tournaments When Verifiable Rewards Fall Short
Jun 08, 2026Reinforcement learning with verifiable rewards (RLVR) has become a leading paradigm for improving the reasoning ability of large language models through outcome-based supervision. However, verifiable rewards frequently become uninformative at the group level: when all sampled traces of a given prompt receive identical rewards, group-relative advantage estimation provides no gradient signal, even though the traces may differ substantially in reasoning quality. We propose Reasoning Arena, an adaptive training framework that routes such non-diverse reward groups to a judge system instead of discarding them. Beyond examining the final answer, Reasoning Arena constructs trace tournaments, where reasoning traces are compared head-to-head to expose finer-grained preferences within the group, converting reasoning quality into rich relative reward signals. To make reward estimation efficient, rather than exhaustively comparing every pair, each new trace is evaluated against a small, dynamically updated pool of previously generated traces as anchors to efficiently establish a relative ranking. We then fit a Bradley-Terry model on the incomplete comparison graph, enabling scalable RL integration without quadratic pairwise comparisons. Empirical results demonstrate that Reasoning Arena consistently outperforms the RLVR baseline by 7.6% on average in competition mathematics and coding benchmarks. By converting otherwise wasted zero-advantage samples into useful gradient updates, our method accelerates training by 27% to 41%, saving nearly 50% of generation compute, and substantially improves overall reasoning performance.
Instruction Tuning With Loss Over Instructions
May 23, 2024Instruction tuning plays a crucial role in shaping the outputs of language models (LMs) to desired styles. In this work, we propose a simple yet effective method, Instruction Modelling (IM), which trains LMs by applying a loss function to the instruction and prompt part rather than solely to the output part. Through experiments across 21 diverse benchmarks, we show that, in many scenarios, IM can effectively improve the LM performance on both NLP tasks (e.g., MMLU, TruthfulQA, and HumanEval) and open-ended generation benchmarks (e.g., MT-Bench and AlpacaEval). Remarkably, in the most advantageous case, IM boosts model performance on AlpacaEval 1.0 by over 100%. We identify two key factors influencing the effectiveness of IM: (1) The ratio between instruction length and output length in the training data; and (2) The number of training examples. We observe that IM is especially beneficial when trained on datasets with lengthy instructions paired with brief outputs, or under the Superficial Alignment Hypothesis (SAH) where a small amount of training examples are used for instruction tuning. Further analysis substantiates our hypothesis that the improvement can be attributed to reduced overfitting to instruction tuning datasets. Our work provides practical guidance for instruction tuning LMs, especially in low-resource scenarios.
Bayesian Reward Models for LLM Alignment
Feb 20, 2024


To ensure that large language model (LLM) responses are helpful and non-toxic, we usually fine-tune a reward model on human preference data. We then select policy responses with high rewards (best-of-n sampling) or further optimize the policy to produce responses with high rewards (reinforcement learning from human feedback). However, this process is vulnerable to reward overoptimization or hacking, in which the responses selected have high rewards due to errors in the reward model rather than a genuine preference. This is especially problematic as the prompt or response diverges from the training data. It should be possible to mitigate these issues by training a Bayesian reward model, which signals higher uncertainty further from the training data distribution. Therefore, we trained Bayesian reward models using Laplace-LoRA (Yang et al., 2024) and found that the resulting uncertainty estimates can successfully mitigate reward overoptimization in best-of-n sampling.
Bayesian low-rank adaptation for large language models
Aug 28, 2023


Parameter-efficient fine-tuning (PEFT) has emerged as a new paradigm for cost-efficient fine-tuning of large language models (LLMs), with low-rank adaptation (LoRA) being a widely adopted choice. However, fine-tuned LLMs often become overconfident especially when fine-tuned on small datasets. Bayesian methods, with their inherent ability to estimate uncertainty, serve as potent tools to mitigate overconfidence and enhance calibration. In this work, we introduce Laplace-LoRA, a straightforward yet effective Bayesian method, which applies the Laplace approximation to the LoRA parameters and, considerably boosts the calibration of fine-tuned LLMs.
MONGOOSE: Path-wise Smooth Bayesian Optimisation via Meta-learning
Feb 22, 2023



In Bayesian optimisation, we often seek to minimise the black-box objective functions that arise in real-world physical systems. A primary contributor to the cost of evaluating such black-box objective functions is often the effort required to prepare the system for measurement. We consider a common scenario where preparation costs grow as the distance between successive evaluations increases. In this setting, smooth optimisation trajectories are preferred and the jumpy paths produced by the standard myopic (i.e.\ one-step-optimal) Bayesian optimisation methods are sub-optimal. Our algorithm, MONGOOSE, uses a meta-learnt parametric policy to generate smooth optimisation trajectories, achieving performance gains over existing methods when optimising functions with large movement costs.
Deep kernel processes
Oct 04, 2020
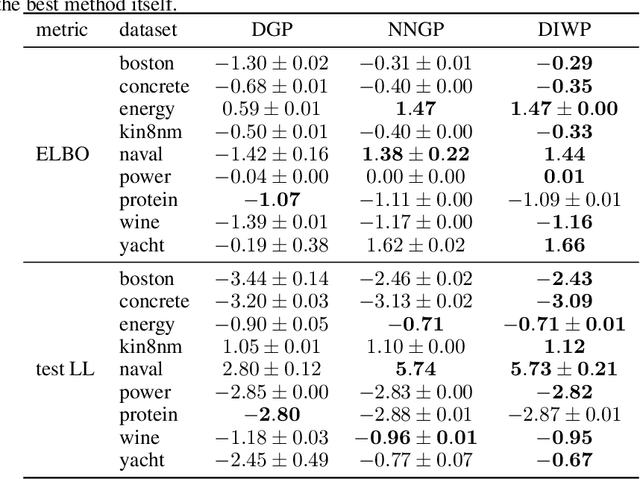
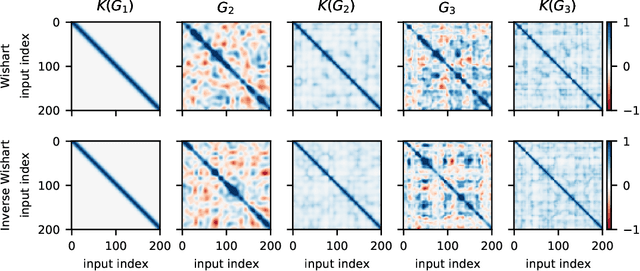
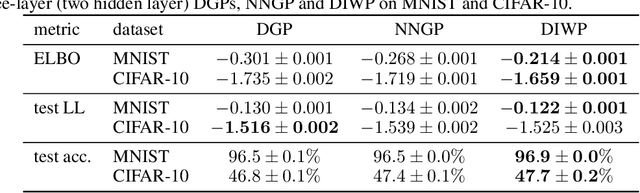
We define deep kernel processes in which positive definite Gram matrices are progressively transformed by nonlinear kernel functions and by sampling from (inverse) Wishart distributions. Remarkably, we find that deep Gaussian processes (DGPs), Bayesian neural networks (BNNs), infinite BNNs, and infinite BNNs with bottlenecks can all be written as deep kernel processes. For DGPs the equivalence arises because the Gram matrix formed by the inner product of features is Wishart distributed, and as we show, standard isotropic kernels can be written entirely in terms of this Gram matrix -- we do not need knowledge of the underlying features. We define a tractable deep kernel process, the deep inverse Wishart process, and give a doubly-stochastic inducing-point variational inference scheme that operates on the Gram matrices, not on the features, as in DGPs. We show that the deep inverse Wishart process gives superior performance to DGPs and infinite BNNs on standard fully-connected baselines.