 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Successor Representation for Robust Transfer
Feb 13, 2026The successor representation (SR) provides a powerful framework for decoupling predictive dynamics from rewards, enabling rapid generalisation across reward configurations. However, the classical SR is limited by its inherent policy dependence: policies change due to ongoing learning, environmental non-stationarities, and changes in task demands, making established predictive representations obsolete. Furthermore, in topologically complex environments, SRs suffer from spectral diffusion, leading to dense and overlapping features that scale poorly. Here we propose the Hierarchical Successor Representation (HSR) for overcoming these limitations. By incorporating temporal abstractions into the construction of predictive representations, HSR learns stable state features which are robust to task-induced policy changes. Applying non-negative matrix factorisation (NMF) to the HSR yields a sparse, low-rank state representation that facilitates highly sample-efficient transfer to novel tasks in multi-compartmental environments. Further analysis reveals that HSR-NMF discovers interpretable topological structures, providing a policy-agnostic hierarchical map that effectively bridges model-free optimality and model-based flexibility. Beyond providing a useful basis for task-transfer, we show that HSR's temporally extended predictive structure can also be leveraged to drive efficient exploration, effectively scaling to large, procedurally generated environments.
Successor-Predecessor Intrinsic Exploration
May 24, 2023Exploration is essential in reinforcement learning, particularly in environments where external rewards are sparse. Here we focus on exploration with intrinsic rewards, where the agent transiently augments the external rewards with self-generated intrinsic rewards. Although the study of intrinsic rewards has a long history, existing methods focus on composing the intrinsic reward based on measures of future prospects of states, ignoring the information contained in the retrospective structure of transition sequences. Here we argue that the agent can utilise retrospective information to generate explorative behaviour with structure-awareness, facilitating efficient exploration based on global instead of local information. We propose Successor-Predecessor Intrinsic Exploration (SPIE), an exploration algorithm based on a novel intrinsic reward combining prospective and retrospective information. We show that SPIE yields more efficient and ethologically plausible exploratory behaviour in environments with sparse rewards and bottleneck states than competing methods. We also implement SPIE in deep reinforcement learning agents, and show that the resulting agent achieves stronger empirical performance than existing methods on sparse-reward Atari games.
Unsupervised representational learning with recognition-parametrised probabilistic models
Sep 13, 2022
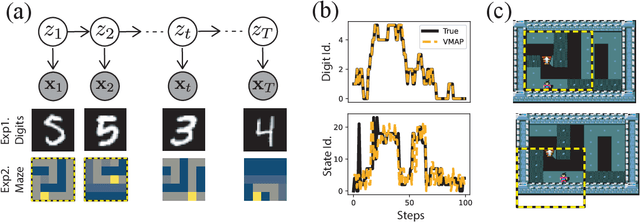

We introduce a new approach to probabilistic unsupervised learning based on the recognition-parametrised model (RPM): a normalised semi-parametric hypothesis class for joint distributions over observed and latent variables. Under the key assumption that observations are conditionally independent given the latents, RPMs directly encode the "recognition" process, parametrising both the prior distribution on the latents and their conditional distributions given observations. This recognition model is paired with non-parametric descriptions of the marginal distribution of each observed variable. Thus, the focus is on learning a good latent representation that captures dependence between the measurements. The RPM permits exact maximum likelihood learning in settings with discrete latents and a tractable prior, even when the mapping between continuous observations and the latents is expressed through a flexible model such as a neural network. We develop effective approximations for the case of continuous latent variables with tractable priors. Unlike the approximations necessary in dual-parametrised models such as Helmholtz machines and variational autoencoders, these RPM approximations introduce only minor bias, which may often vanish asymptotically. Furthermore, where the prior on latents is intractable the RPM may be combined effectively with standard probabilistic techniques such as variational Bayes. We demonstrate the model in high dimensional data settings, including a form of weakly supervised learning on MNIST digits and the discovery of latent maps from sensory observations. The RPM provides an effective way to discover, represent and reason probabilistically about the latent structure underlying observational data, functions which are critical to both animal and artificial intelligence.
Amortised Inference in Structured Generative Models with Explaining Away
Sep 12, 2022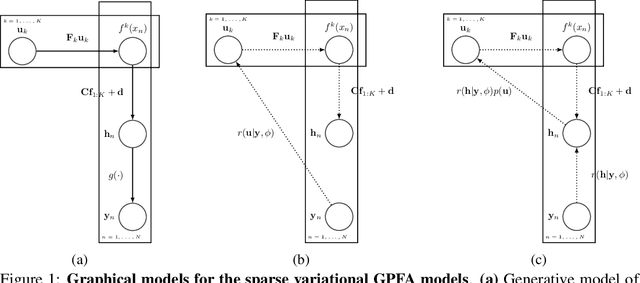
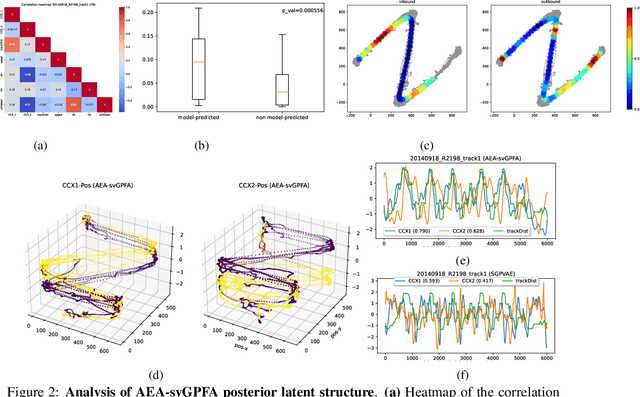
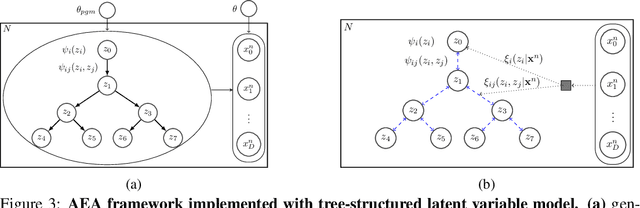
A key goal of unsupervised learning is to go beyond density estimation and sample generation to reveal the structure inherent within observed data. Such structure can be expressed in the pattern of interactions between explanatory latent variables captured through a probabilistic graphical model. Although the learning of structured graphical models has a long history, much recent work in unsupervised modelling has instead emphasised flexible deep-network-based generation, either transforming independent latent generators to model complex data or assuming that distinct observed variables are derived from different latent nodes. Here, we extend the output of amortised variational inference to incorporate structured factors over multiple variables, able to capture the observation-induced posterior dependence between latents that results from "explaining away" and thus allow complex observations to depend on multiple nodes of a structured graph. We show that appropriately parameterised factors can be combined efficiently with variational message passing in elaborate graphical structures. We instantiate the framework based on Gaussian Process Factor Analysis models, and empirically evaluate its improvement over existing methods on synthetic data with known generative processes. We then fit the structured model to high-dimensional neural spiking time-series from the hippocampus of freely moving rodents, demonstrating that the model identifies latent signals that correlate with behavioural covariates.
SEREN: Knowing When to Explore and When to Exploit
May 30, 2022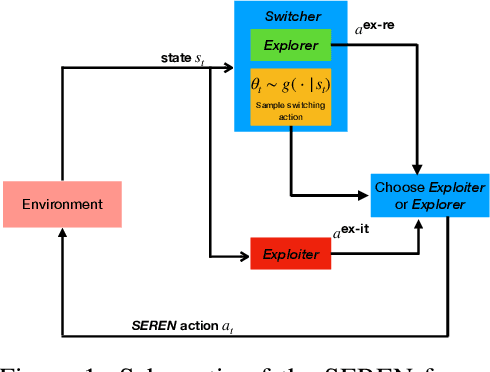
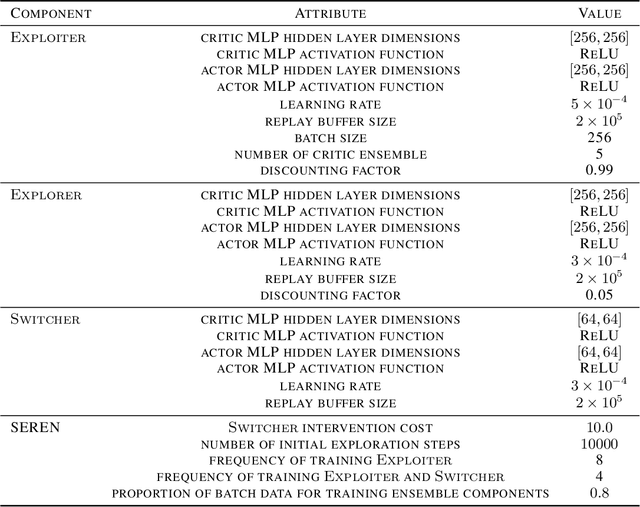
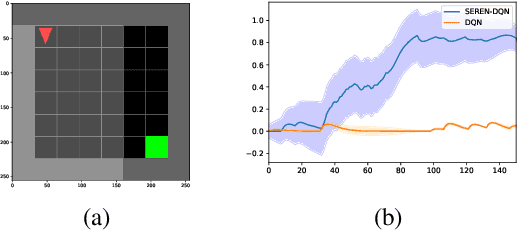
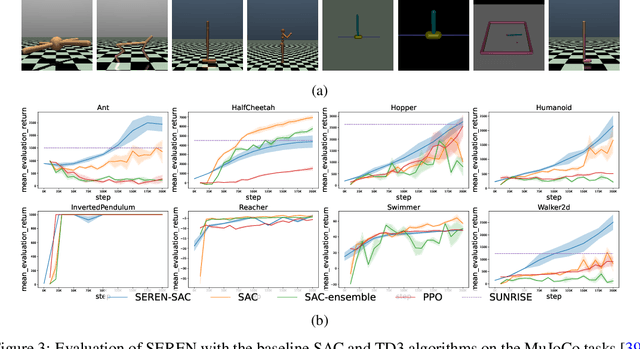
Efficient reinforcement learning (RL) involves a trade-off between "exploitative" actions that maximise expected reward and "explorative'" ones that sample unvisited states. To encourage exploration, recent approaches proposed adding stochasticity to actions, separating exploration and exploitation phases, or equating reduction in uncertainty with reward. However, these techniques do not necessarily offer entirely systematic approaches making this trade-off. Here we introduce SElective Reinforcement Exploration Network (SEREN) that poses the exploration-exploitation trade-off as a game between an RL agent -- \exploiter, which purely exploits known rewards, and another RL agent -- \switcher, which chooses at which states to activate a pure exploration policy that is trained to minimise system uncertainty and override Exploiter. Using a form of policies known as impulse control, \switcher is able to determine the best set of states to switch to the exploration policy while Exploiter is free to execute its actions everywhere else. We prove that SEREN converges quickly and induces a natural schedule towards pure exploitation. Through extensive empirical studies in both discrete (MiniGrid) and continuous (MuJoCo) control benchmarks, we show that SEREN can be readily combined with existing RL algorithms to yield significant improvement in performance relative to state-of-the-art algorithms.
Learning State Representations via Retracing in Reinforcement Learning
Nov 24, 2021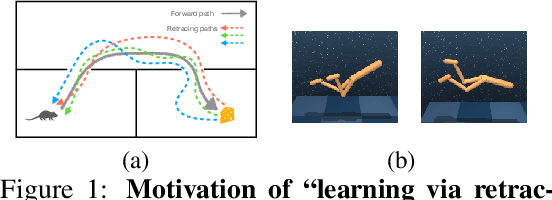
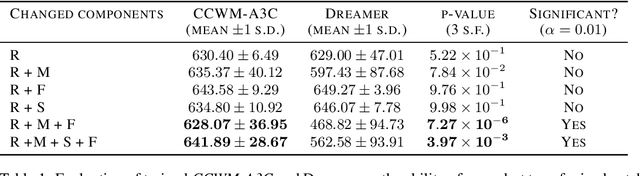
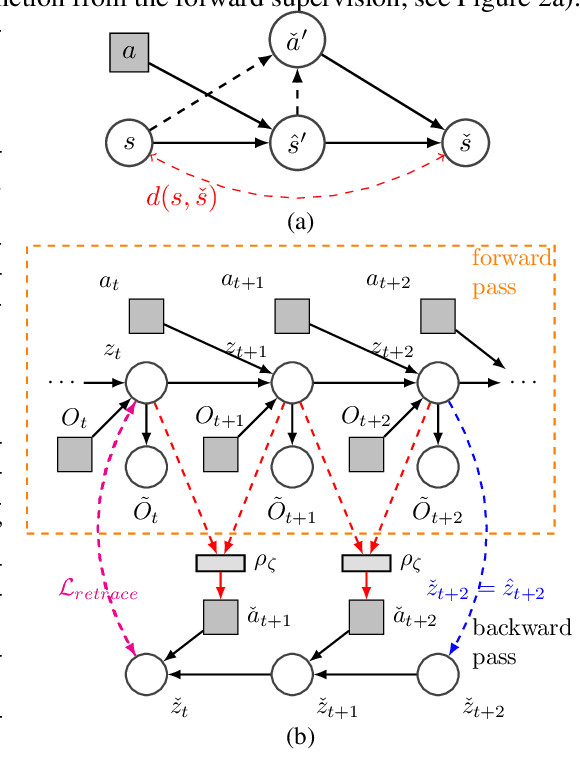
We propose learning via retracing, a novel self-supervised approach for learning the state representation (and the associated dynamics model) for reinforcement learning tasks. In addition to the predictive (reconstruction) supervision in the forward direction, we propose to include `"retraced" transitions for representation/model learning, by enforcing the cycle-consistency constraint between the original and retraced states, hence improve upon the sample efficiency of learning. Moreover, learning via retracing explicitly propagates information about future transitions backward for inferring previous states, thus facilitates stronger representation learning. We introduce Cycle-Consistency World Model (CCWM), a concrete instantiation of learning via retracing implemented under existing model-based reinforcement learning framework. Additionally we propose a novel adaptive "truncation" mechanism for counteracting the negative impacts brought by the "irreversible" transitions such that learning via retracing can be maximally effective. Through extensive empirical studies on continuous control benchmarks, we demonstrates that CCWM achieves state-of-the-art performance in terms of sample efficiency and asymptotic performance.
DESTA: A Framework for Safe Reinforcement Learning with Markov Games of Intervention
Oct 27, 2021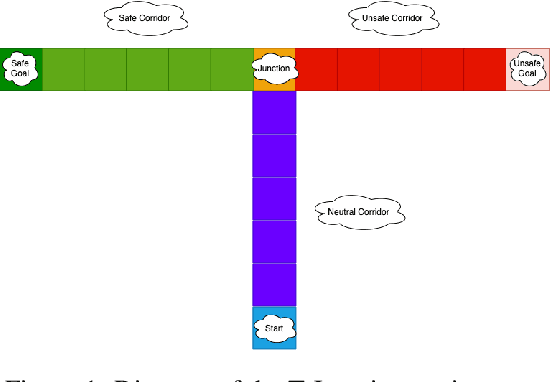
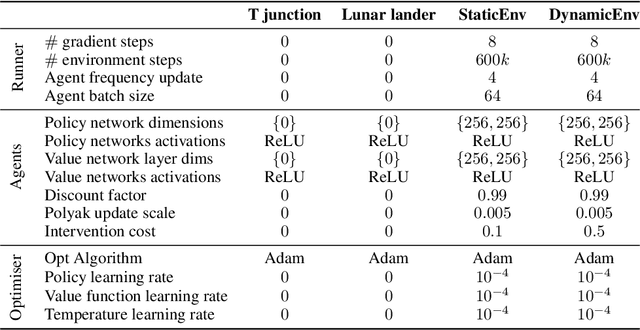
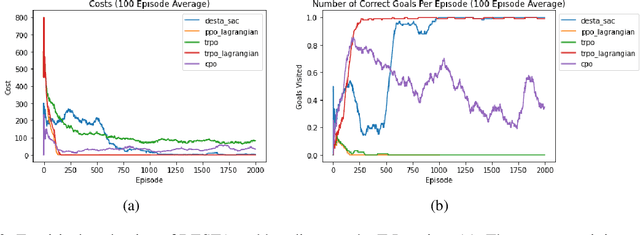

Exploring in an unknown system can place an agent in dangerous situations, exposing to potentially catastrophic hazards. Many current approaches for tackling safe learning in reinforcement learning (RL) lead to a trade-off between safe exploration and fulfilling the task. Though these methods possibly incur fewer safety violations, they often also lead to reduced task performance. In this paper, we take the first step in introducing a generation of RL solvers that learn to minimise safety violations while maximising the task reward to the extend that can be tolerated by safe policies. Our approach uses a new two-player framework for safe RL called Distributive Exploration Safety Training Algorithm (DESTA). The core of DESTA is a novel game between two RL agents: SAFETY AGENT that is delegated the task of minimising safety violations and TASK AGENT whose goal is to maximise the reward set by the environment task. SAFETY AGENT can selectively take control of the system at any given point to prevent safety violations while TASK AGENT is free to execute its actions at all other states. This framework enables SAFETY AGENT to learn to take actions that minimise future safety violations (during and after training) by performing safe actions at certain states while TASK AGENT performs actions that maximise the task performance everywhere else. We demonstrate DESTA's ability to tackle challenging tasks and compare against state-of-the-art RL methods in Safety Gym Benchmarks which simulate real-world physical systems and OpenAI's Lunar Lander.
Prediction with directed transitions: complex eigenstructure, grid cells and phase coding
Jun 05, 2020
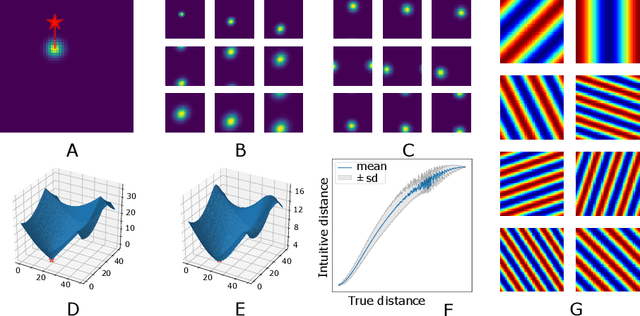
Markovian tasks can be characterised by a state space and a transition matrix. In mammals, the firing of populations of place or grid cells in the hippocampal formation are thought to represent the probability distribution over state space. Grid firing patterns are suggested to be eigenvectors of a transition matrix reflecting diffusion across states, allowing simple prediction of future state distributions, by replacing matrix multiplication with elementwise multiplication by eigenvalues. Here we extend this analysis to any translation-invariant directed transition structure (displacement and diffusion), showing that a single set of eigenvectors supports prediction via displacement-specific eigenvalues. This unifies the prediction framework with traditional models of grid cells firing driven by self-motion to perform path integration. We show that the complex eigenstructure of directed transitions corresponds to the Discrete Fourier Transform, the eigenvalues encode displacement via the Fourier Shift Theorem, and the Fourier components are analogous to "velocity-controlled oscillators" in oscillatory interference models. The resulting model supports computationally efficient prediction with directed transitions in spatial and non-spatial tasks and provides an explanation for theta phase precession and path integration in grid cell firing. We also discuss the efficient generalisation of our approach to deal with local changes in transition structure and its contribution to behavioural policy via a "sense of direction" corresponding to prediction of the effects of fixed ratios of actions.