 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction under Latent Subgroup Shifts with High-Dimensional Observations
Jun 23, 2023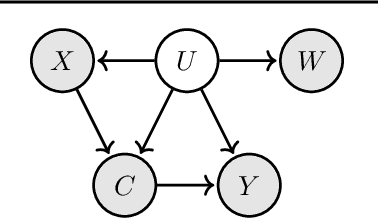
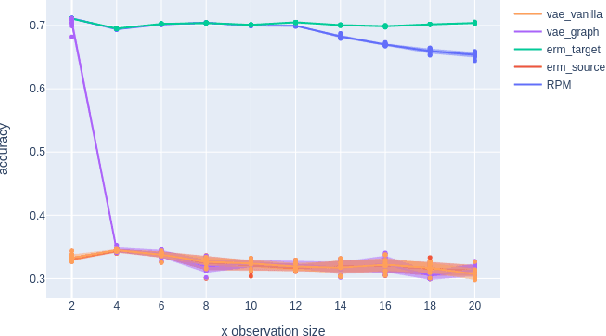
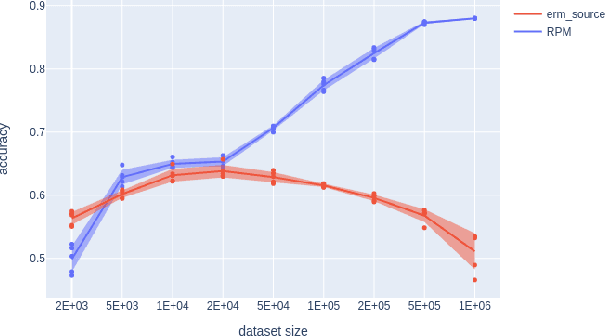
We introduce a new approach to prediction in graphical models with latent-shift adaptation, i.e., where source and target environments differ in the distribution of an unobserved confounding latent variable. Previous work has shown that as long as "concept" and "proxy" variables with appropriate dependence are observed in the source environment, the latent-associated distributional changes can be identified, and target predictions adapted accurately. However, practical estimation methods do not scale well when the observations are complex and high-dimensional, even if the confounding latent is categorical. Here we build upon a recently proposed probabilistic unsupervised learning framework, the recognition-parametrised model (RPM), to recover low-dimensional, discrete latents from image observations. Applied to the problem of latent shifts, our novel form of RPM identifies causal latent structure in the source environment, and adapts properly to predict in the target. We demonstrate results in settings where predictor and proxy are high-dimensional images, a context to which previous methods fail to scale.
Unsupervised representational learning with recognition-parametrised probabilistic models
Sep 13, 2022
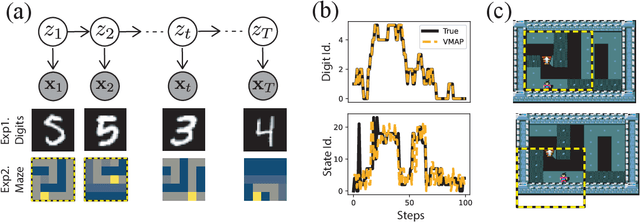

We introduce a new approach to probabilistic unsupervised learning based on the recognition-parametrised model (RPM): a normalised semi-parametric hypothesis class for joint distributions over observed and latent variables. Under the key assumption that observations are conditionally independent given the latents, RPMs directly encode the "recognition" process, parametrising both the prior distribution on the latents and their conditional distributions given observations. This recognition model is paired with non-parametric descriptions of the marginal distribution of each observed variable. Thus, the focus is on learning a good latent representation that captures dependence between the measurements. The RPM permits exact maximum likelihood learning in settings with discrete latents and a tractable prior, even when the mapping between continuous observations and the latents is expressed through a flexible model such as a neural network. We develop effective approximations for the case of continuous latent variables with tractable priors. Unlike the approximations necessary in dual-parametrised models such as Helmholtz machines and variational autoencoders, these RPM approximations introduce only minor bias, which may often vanish asymptotically. Furthermore, where the prior on latents is intractable the RPM may be combined effectively with standard probabilistic techniques such as variational Bayes. We demonstrate the model in high dimensional data settings, including a form of weakly supervised learning on MNIST digits and the discovery of latent maps from sensory observations. The RPM provides an effective way to discover, represent and reason probabilistically about the latent structure underlying observational data, functions which are critical to both animal and artificial intelligence.