 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo-regret Learning in Repeated First-Price Auctions with Budget Constraints
May 29, 2022
Recently the online advertising market has exhibited a gradual shift from second-price auctions to first-price auctions. Although there has been a line of works concerning online bidding strategies in first-price auctions, it still remains open how to handle budget constraints in the problem. In the present paper, we initiate the study for a buyer with budgets to learn online bidding strategies in repeated first-price auctions. We propose an RL-based bidding algorithm against the optimal non-anticipating strategy under stationary competition. Our algorithm obtains $\widetilde O(\sqrt T)$-regret if the bids are all revealed at the end of each round. With the restriction that the buyer only sees the winning bid after each round, our modified algorithm obtains $\widetilde O(T^{\frac{7}{12}})$-regret by techniques developed from survival analysis. Our analysis extends to the more general scenario where the buyer has any bounded instantaneous utility function with regrets of the same order.
On the Convergence of Fictitious Play: A Decomposition Approach
May 03, 2022
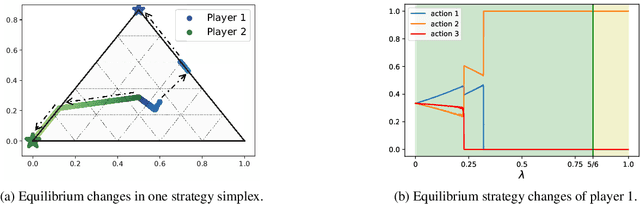
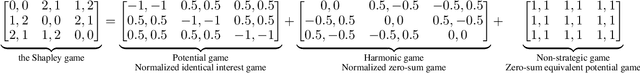

Fictitious play (FP) is one of the most fundamental game-theoretical learning frameworks for computing Nash equilibrium in $n$-player games, which builds the foundation for modern multi-agent learning algorithms. Although FP has provable convergence guarantees on zero-sum games and potential games, many real-world problems are often a mixture of both and the convergence property of FP has not been fully studied yet. In this paper, we extend the convergence results of FP to the combinations of such games and beyond. Specifically, we derive new conditions for FP to converge by leveraging game decomposition techniques. We further develop a linear relationship unifying cooperation and competition in the sense that these two classes of games are mutually transferable. Finally, we analyze a non-convergent example of FP, the Shapley game, and develop sufficient conditions for FP to converge.
Cost-Effective Incentive Allocation via Structured Counterfactual Inference
Feb 07, 2019
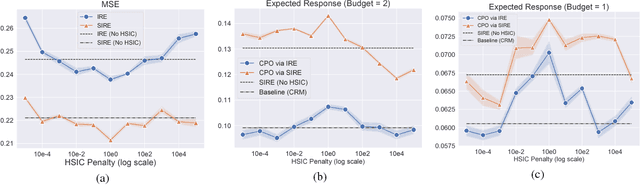
We address a practical problem ubiquitous in modern industry, in which a mediator tries to learn a policy for allocating strategic financial incentives for customers in a marketing campaign and observes only bandit feedback. In contrast to traditional policy optimization frameworks, we rely on a specific assumption for the reward structure and we incorporate budget constraints. We develop a new two-step method for solving this constrained counterfactual policy optimization problem. First, we cast the reward estimation problem as a domain adaptation problem with supplementary structure. Subsequently, the estimators are used for optimizing the policy with constraints. We establish theoretical error bounds for our estimation procedure and we empirically show that the approach leads to significant improvement on both synthetic and real datasets.
A Policy Gradient Method with Variance Reduction for Uplift Modeling
Nov 26, 2018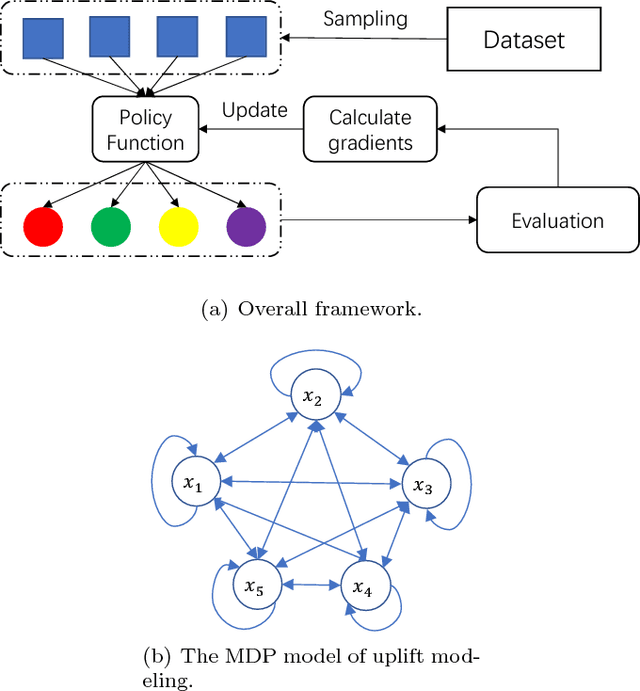

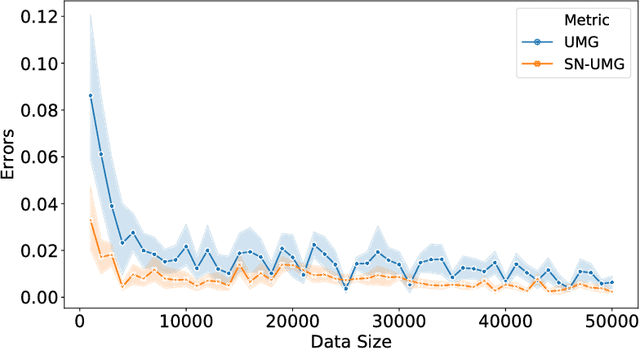
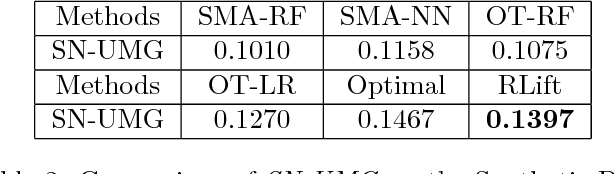
Uplift modeling aims to directly model the incremental impact of a treatment on an individual response. It has been widely and successfully used in healthcare analytics and business operations, where one tries to measure the net effect of a new medicine on patients or to understand the impact of a marketing campaign on company revenue. In this work, we address the problem from a new angle and reformulate it as a Markov Decision Process (MDP). This new formulation allows us to handle the lack of explicit labels, to deal with any number of actions (in comparison to the normal two action uplift modeling), and to apply it to applications with responses of general types, which is a challenging task for previous methods. Furthermore, we also design an unbiased metric for more accurate offline evaluation of uplift effects, set up a better reward function for the policy gradient method to solve the problem and adopt some action-based baselines to reduce variance. We conducted extensive experiments on both a synthetic dataset and real-world scenarios, and showed that our method can achieve significant improvement over previous methods.
Visual-Texual Emotion Analysis with Deep Coupled Video and Danmu Neural Networks
Nov 19, 2018
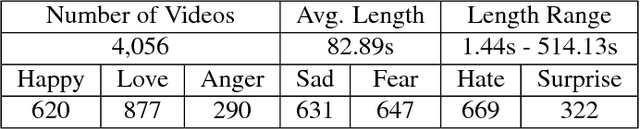
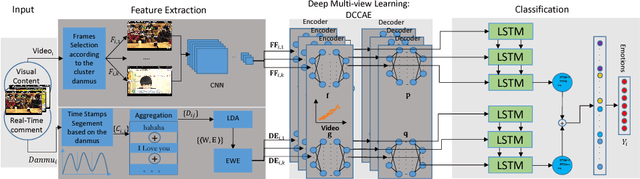
User emotion analysis toward videos is to automatically recognize the general emotional status of viewers from the multimedia content embedded in the online video stream. Existing works fall in two categories: 1) visual-based methods, which focus on visual content and extract a specific set of features of videos. However, it is generally hard to learn a mapping function from low-level video pixels to high-level emotion space due to great intra-class variance. 2) textual-based methods, which focus on the investigation of user-generated comments associated with videos. The learned word representations by traditional linguistic approaches typically lack emotion information and the global comments usually reflect viewers' high-level understandings rather than instantaneous emotions. To address these limitations, in this paper, we propose to jointly utilize video content and user-generated texts simultaneously for emotion analysis. In particular, we introduce exploiting a new type of user-generated texts, i.e., "danmu", which are real-time comments floating on the video and contain rich information to convey viewers' emotional opinions. To enhance the emotion discriminativeness of words in textual feature extraction, we propose Emotional Word Embedding (EWE) to learn text representations by jointly considering their semantics and emotions. Afterwards, we propose a novel visual-textual emotion analysis model with Deep Coupled Video and Danmu Neural networks (DCVDN), in which visual and textual features are synchronously extracted and fused to form a comprehensive representation by deep-canonically-correlated-autoencoder-based multi-view learning. Through extensive experiments on a self-crawled real-world video-danmu dataset, we prove that DCVDN significantly outperforms the state-of-the-art baselines.
Latent Dirichlet Allocation for Internet Price War
Aug 23, 2018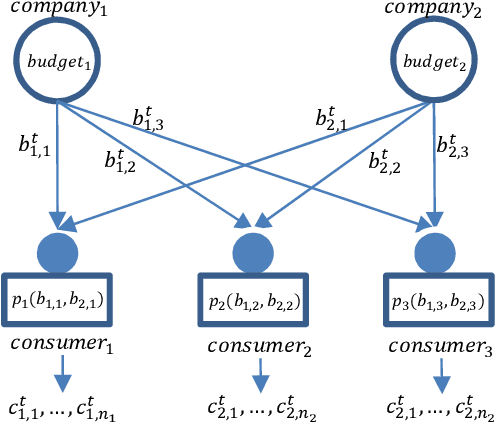
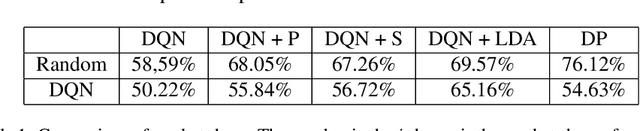
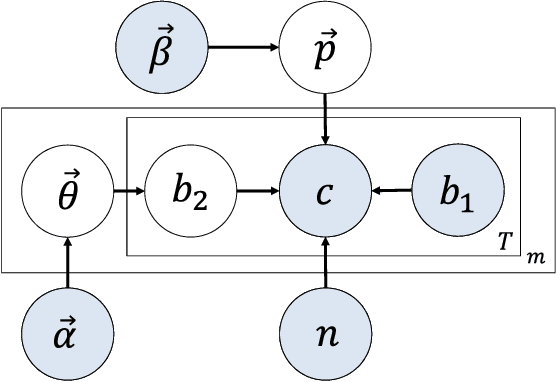

Internet market makers are always facing intense competitive environment, where personalized price reductions or discounted coupons are provided for attracting more customers. Participants in such a price war scenario have to invest a lot to catch up with other competitors. However, such a huge cost of money may not always lead to an improvement of market share. This is mainly due to a lack of information about others' strategies or customers' willingness when participants develop their strategies. In order to obtain this hidden information through observable data, we study the relationship between companies and customers in the Internet price war. Theoretically, we provide a formalization of the problem as a stochastic game with imperfect and incomplete information. Then we develop a variant of Latent Dirichlet Allocation (LDA) to infer latent variables under the current market environment, which represents the preferences of customers and strategies of competitors. To our best knowledge, it is the first time that LDA is applied to game scenario. We conduct simulated experiments where our LDA model exhibits a significant improvement on finding strategies in the Internet price war by including all available market information of the market maker's competitors. And the model is applied to an open dataset for real business. Through comparisons on the likelihood of prediction for users' behavior and distribution distance between inferred opponent's strategy and the real one, our model is shown to be able to provide a better understanding for the market environment. Our work marks a successful learning method to infer latent information in the environment of price war by the LDA modeling, and sets an example for related competitive applications to follow.