 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Texual Emotion Analysis with Deep Coupled Video and Danmu Neural Networks
Paper and Code
Nov 19, 2018
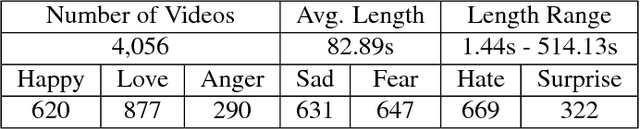
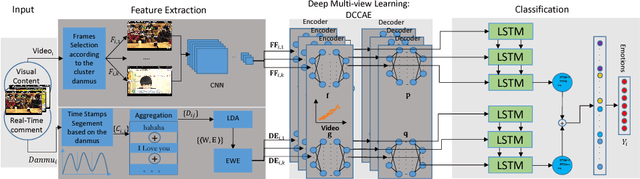
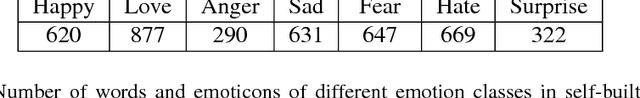
User emotion analysis toward videos is to automatically recognize the general emotional status of viewers from the multimedia content embedded in the online video stream. Existing works fall in two categories: 1) visual-based methods, which focus on visual content and extract a specific set of features of videos. However, it is generally hard to learn a mapping function from low-level video pixels to high-level emotion space due to great intra-class variance. 2) textual-based methods, which focus on the investigation of user-generated comments associated with videos. The learned word representations by traditional linguistic approaches typically lack emotion information and the global comments usually reflect viewers' high-level understandings rather than instantaneous emotions. To address these limitations, in this paper, we propose to jointly utilize video content and user-generated texts simultaneously for emotion analysis. In particular, we introduce exploiting a new type of user-generated texts, i.e., "danmu", which are real-time comments floating on the video and contain rich information to convey viewers' emotional opinions. To enhance the emotion discriminativeness of words in textual feature extraction, we propose Emotional Word Embedding (EWE) to learn text representations by jointly considering their semantics and emotions. Afterwards, we propose a novel visual-textual emotion analysis model with Deep Coupled Video and Danmu Neural networks (DCVDN), in which visual and textual features are synchronously extracted and fused to form a comprehensive representation by deep-canonically-correlated-autoencoder-based multi-view learning. Through extensive experiments on a self-crawled real-world video-danmu dataset, we prove that DCVDN significantly outperforms the state-of-the-art baselines.