 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory of Appropriateness That Accounts for Norms of Rationality
Mar 14, 2026We propose a society-first theory of normative appropriateness where individuals, modeled as pre-trained actors with cognitive architectures analogous to Large Language Models (LLMs), generate behavior via predictive pattern completion. Our theory posits that individuals act by completing distributed symbolic patterns based on context, answering questions such as "What does a person such as I do in a situation such as this?". This sense-making mechanism provides a parsimonious account of the key features of human norms: their context-dependence, arbitrariness, automaticity, dynamism, and their support from social sanctioning. It challenges rational-choice theories of social norms by accounting for their key features without needing to exogenously posit scalar rewards or preference relations. By distinguishing between explicit norms, which we associate with in-context adaptation, and implicit norms, which we associate with long-term memory, the theory reconceptualizes several foundational ideas in cognitive science. In particular, it gives an alternative account to the data traditionally seen as supporting dual-process models, and it flips the role of rationality, allowing us to construe it as adherence to culturally-contingent justification standards.
Simulation Streams: A Programming Paradigm for Controlling Large Language Models and Building Complex Systems with Generative AI
Jan 30, 2025



We introduce Simulation Streams, a programming paradigm designed to efficiently control and leverage Large Language Models (LLMs) for complex, dynamic simulations and agentic workflows. Our primary goal is to create a minimally interfering framework that harnesses the agentic abilities of LLMs while addressing their limitations in maintaining consistency, selectively ignoring/including information, and enforcing strict world rules. Simulation Streams achieves this through a state-based approach where variables are modified in sequential steps by "operators," producing output on a recurring format and adhering to consistent rules for state variables. This approach focus the LLMs on defined tasks, while aiming to have the context stream remain "in-distribution". The approach incorporates an Entity-Component-System (ECS) architecture to write programs in a more intuitive manner, facilitating reuse of workflows across different components and entities. This ECS approach enhances the modularity of the output stream, allowing for complex, multi-entity simulations while maintaining format consistency, information control, and rule enforcement. It is supported by a custom editor that aids in creating, running, and analyzing simulations. We demonstrate the versatility of simulation streams through an illustrative example of an ongoing market economy simulation, a social simulation of three characters playing a game of catch in a park and a suite of classical reinforcement learning benchmark tasks. These examples showcase Simulation Streams' ability to handle complex, evolving scenarios over 100s-1000s of iterations, facilitate comparisons between different agent workflows and models, and maintain consistency and continued interesting developments in LLM-driven simulations.
A theory of appropriateness with applications to generative artificial intelligence
Dec 26, 2024

What is appropriateness? Humans navigate a multi-scale mosaic of interlocking notions of what is appropriate for different situations. We act one way with our friends, another with our family, and yet another in the office. Likewise for AI, appropriate behavior for a comedy-writing assistant is not the same as appropriate behavior for a customer-service representative. What determines which actions are appropriate in which contexts? And what causes these standards to change over time? Since all judgments of AI appropriateness are ultimately made by humans, we need to understand how appropriateness guides human decision making in order to properly evaluate AI decision making and improve it. This paper presents a theory of appropriateness: how it functions in human society, how it may be implemented in the brain, and what it means for responsible deployment of generative AI technology.
A Review of Cooperation in Multi-agent Learning
Dec 08, 2023
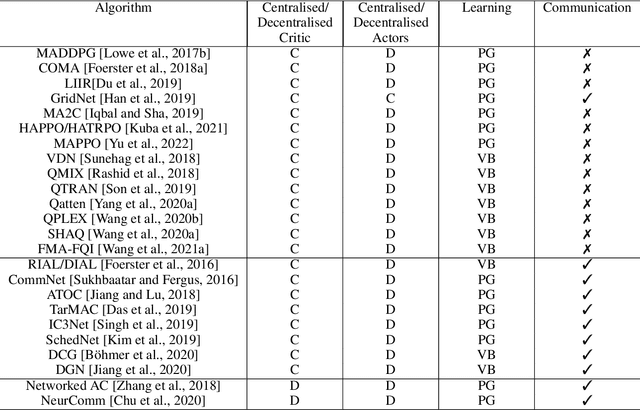

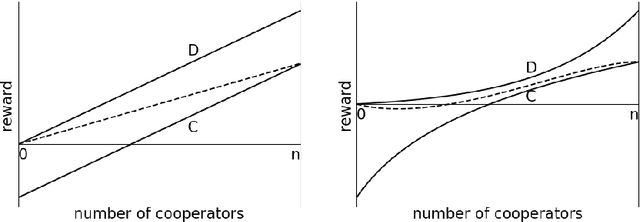
Cooperation in multi-agent learning (MAL) is a topic at the intersection of numerous disciplines, including game theory, economics, social sciences, and evolutionary biology. Research in this area aims to understand both how agents can coordinate effectively when goals are aligned and how they may cooperate in settings where gains from working together are possible but possibilities for conflict abound. In this paper we provide an overview of the fundamental concepts, problem settings and algorithms of multi-agent learning. This encompasses reinforcement learning, multi-agent sequential decision-making, challenges associated with multi-agent cooperation, and a comprehensive review of recent progress, along with an evaluation of relevant metrics. Finally we discuss open challenges in the field with the aim of inspiring new avenues for research.
Diversity Through Exclusion (DTE): Niche Identification for Reinforcement Learning through Value-Decomposition
Feb 03, 2023



Many environments contain numerous available niches of variable value, each associated with a different local optimum in the space of behaviors (policy space). In such situations it is often difficult to design a learning process capable of evading distraction by poor local optima long enough to stumble upon the best available niche. In this work we propose a generic reinforcement learning (RL) algorithm that performs better than baseline deep Q-learning algorithms in such environments with multiple variably-valued niches. The algorithm we propose consists of two parts: an agent architecture and a learning rule. The agent architecture contains multiple sub-policies. The learning rule is inspired by fitness sharing in evolutionary computation and applied in reinforcement learning using Value-Decomposition-Networks in a novel manner for a single-agent's internal population. It can concretely be understood as adding an extra loss term where one policy's experience is also used to update all the other policies in a manner that decreases their value estimates for the visited states. In particular, when one sub-policy visits a particular state frequently this decreases the value predicted for other sub-policies for going to that state. Further, we introduce an artificial chemistry inspired platform where it is easy to create tasks with multiple rewarding strategies utilizing different resources (i.e. multiple niches). We show that agents trained this way can escape poor-but-attractive local optima to instead converge to harder-to-discover higher value strategies in both the artificial chemistry environments and in simpler illustrative environments.
Melting Pot 2.0
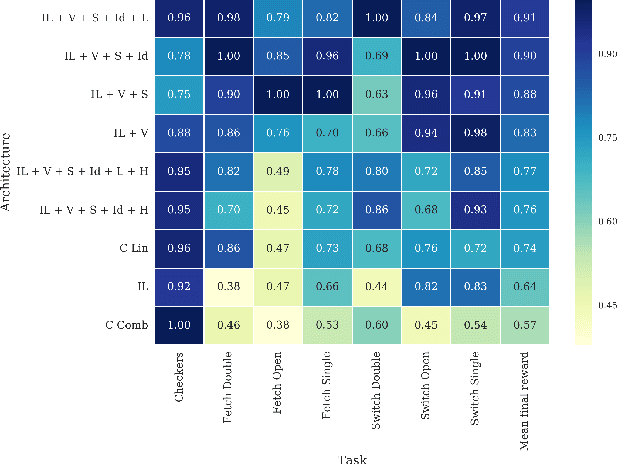
Dec 13, 2022Multi-agent artificial intelligence research promises a path to develop intelligent technologies that are more human-like and more human-compatible than those produced by "solipsistic" approaches, which do not consider interactions between agents. Melting Pot is a research tool developed to facilitate work on multi-agent artificial intelligence, and provides an evaluation protocol that measures generalization to novel social partners in a set of canonical test scenarios. Each scenario pairs a physical environment (a "substrate") with a reference set of co-players (a "background population"), to create a social situation with substantial interdependence between the individuals involved. For instance, some scenarios were inspired by institutional-economics-based accounts of natural resource management and public-good-provision dilemmas. Others were inspired by considerations from evolutionary biology, game theory, and artificial life. Melting Pot aims to cover a maximally diverse set of interdependencies and incentives. It includes the commonly-studied extreme cases of perfectly-competitive (zero-sum) motivations and perfectly-cooperative (shared-reward) motivations, but does not stop with them. As in real-life, a clear majority of scenarios in Melting Pot have mixed incentives. They are neither purely competitive nor purely cooperative and thus demand successful agents be able to navigate the resulting ambiguity. Here we describe Melting Pot 2.0, which revises and expands on Melting Pot. We also introduce support for scenarios with asymmetric roles, and explain how to integrate them into the evaluation protocol. This report also contains: (1) details of all substrates and scenarios; (2) a complete description of all baseline algorithms and results. Our intention is for it to serve as a reference for researchers using Melting Pot 2.0.
Scalable Evaluation of Multi-Agent Reinforcement Learning with Melting Pot
Jul 14, 2021
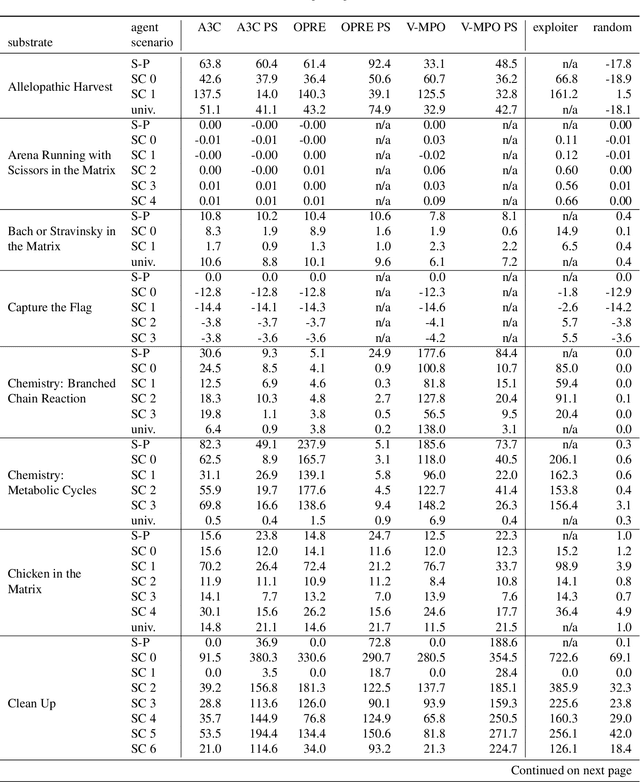
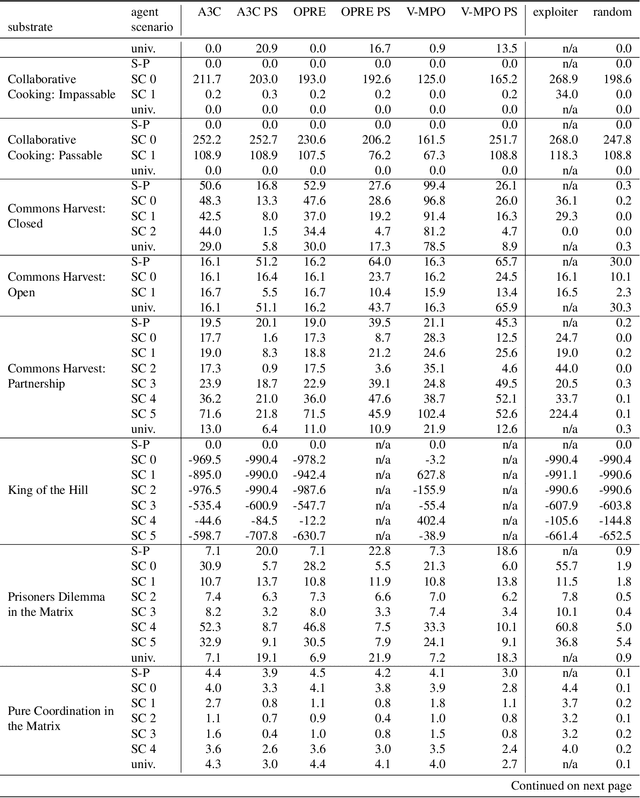
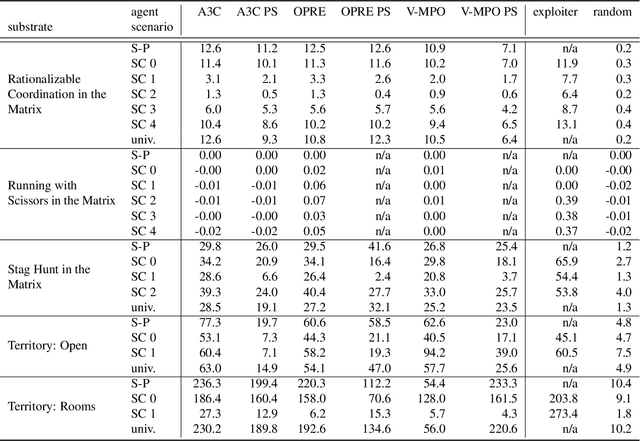
Existing evaluation suites for multi-agent reinforcement learning (MARL) do not assess generalization to novel situations as their primary objective (unlike supervised-learning benchmarks). Our contribution, Melting Pot, is a MARL evaluation suite that fills this gap, and uses reinforcement learning to reduce the human labor required to create novel test scenarios. This works because one agent's behavior constitutes (part of) another agent's environment. To demonstrate scalability, we have created over 80 unique test scenarios covering a broad range of research topics such as social dilemmas, reciprocity, resource sharing, and task partitioning. We apply these test scenarios to standard MARL training algorithms, and demonstrate how Melting Pot reveals weaknesses not apparent from training performance alone.
* Accepted to ICML 2021 and presented as a long talk; 33 pages; 9 figures
Learning to Incentivize Other Learning Agents
Jun 10, 2020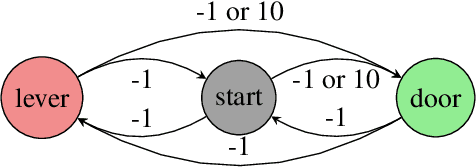

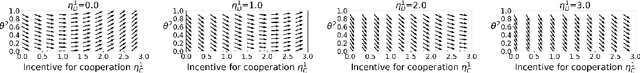
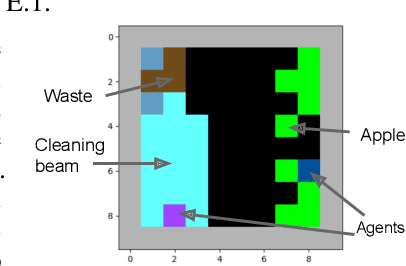
The challenge of developing powerful and general Reinforcement Learning (RL) agents has received increasing attention in recent years. Much of this effort has focused on the single-agent setting, in which an agent maximizes a predefined extrinsic reward function. However, a long-term question inevitably arises: how will such independent agents cooperate when they are continually learning and acting in a shared multi-agent environment? Observing that humans often provide incentives to influence others' behavior, we propose to equip each RL agent in a multi-agent environment with the ability to give rewards directly to other agents, using a learned incentive function. Each agent learns its own incentive function by explicitly accounting for its impact on the learning of recipients and, through them, the impact on its own extrinsic objective. We demonstrate in experiments that such agents significantly outperform standard RL and opponent-shaping agents in challenging general-sum Markov games, often by finding a near-optimal division of labor. Our work points toward more opportunities and challenges along the path to ensure the common good in a multi-agent future.
Malthusian Reinforcement Learning
Dec 17, 2018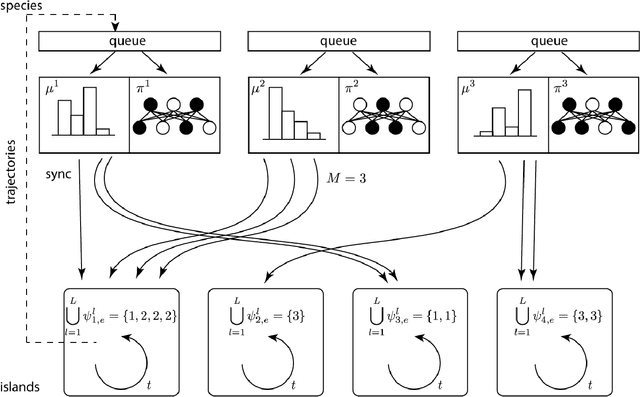
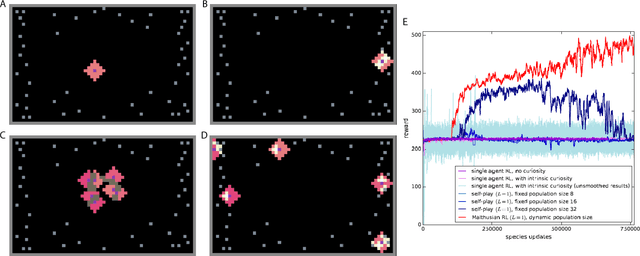
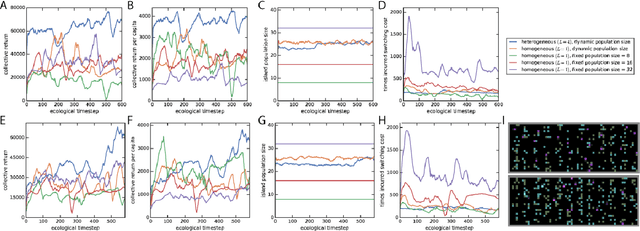
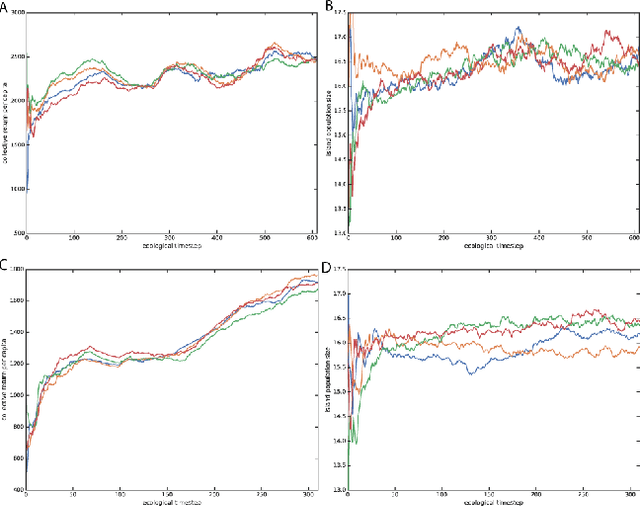
Here we explore a new algorithmic framework for multi-agent reinforcement learning, called Malthusian reinforcement learning, which extends self-play to include fitness-linked population size dynamics that drive ongoing innovation. In Malthusian RL, increases in a subpopulation's average return drive subsequent increases in its size, just as Thomas Malthus argued in 1798 was the relationship between preindustrial income levels and population growth. Malthusian reinforcement learning harnesses the competitive pressures arising from growing and shrinking population size to drive agents to explore regions of state and policy spaces that they could not otherwise reach. Furthermore, in environments where there are potential gains from specialization and division of labor, we show that Malthusian reinforcement learning is better positioned to take advantage of such synergies than algorithms based on self-play.
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Jun 16, 2017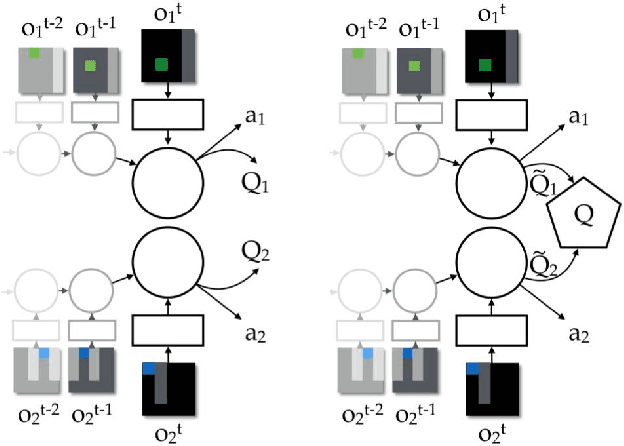
We study the problem of cooperative multi-agent reinforcement learning with a single joint reward signal. This class of learning problems is difficult because of the often large combined action and observation spaces. In the fully centralized and decentralized approaches, we find the problem of spurious rewards and a phenomenon we call the "lazy agent" problem, which arises due to partial observability. We address these problems by training individual agents with a novel value decomposition network architecture, which learns to decompose the team value function into agent-wise value functions. We perform an experimental evaluation across a range of partially-observable multi-agent domains and show that learning such value-decompositions leads to superior results, in particular when combined with weight sharing, role information and information channels.