 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Hanabi Challenge: A New Frontier for AI Research
Feb 01, 2019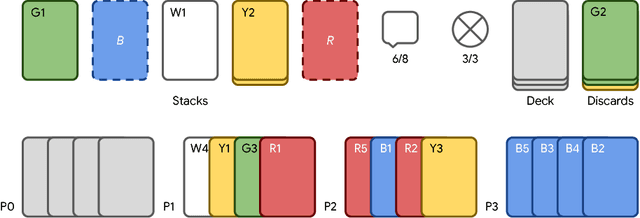
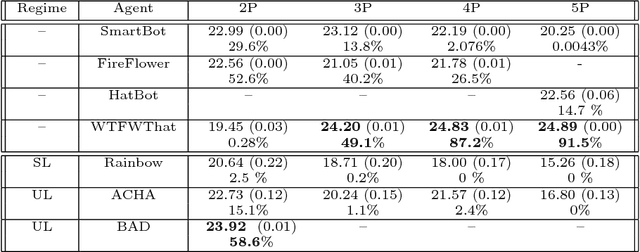
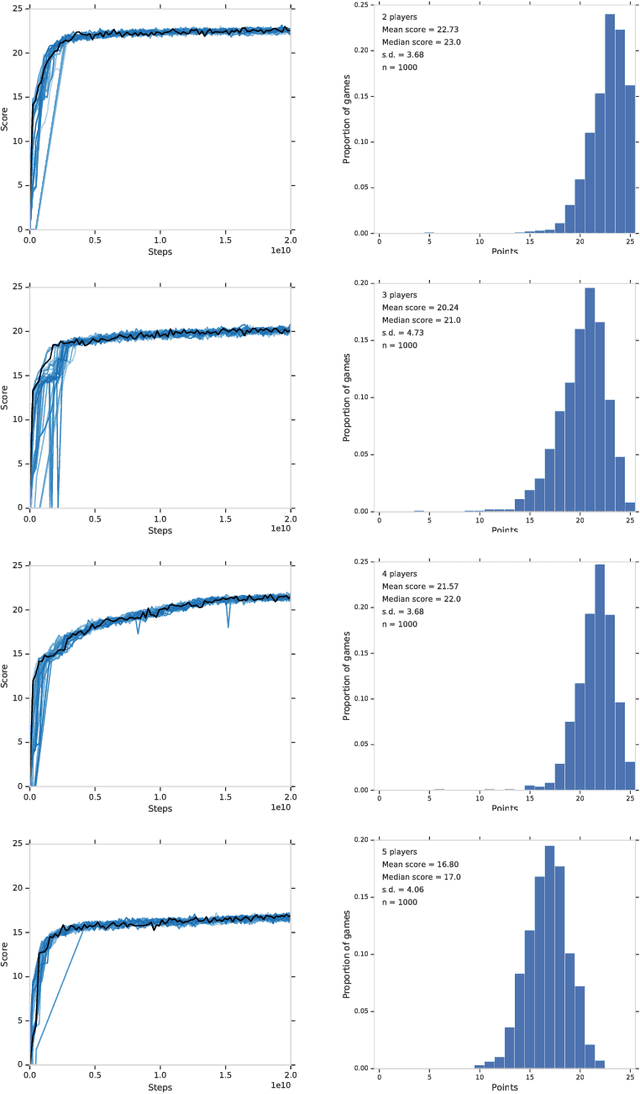
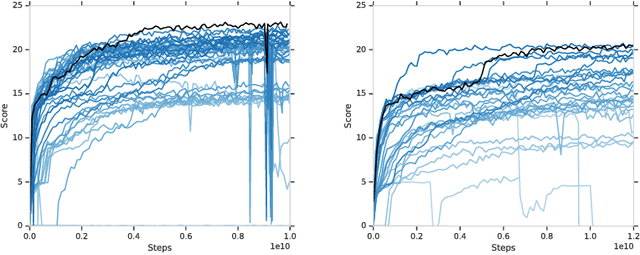
From the early days of computing, games have been important testbeds for studying how well machines can do sophisticated decision making. In recent years, machine learning has made dramatic advances with artificial agents reaching superhuman performance in challenge domains like Go, Atari, and some variants of poker. As with their predecessors of chess, checkers, and backgammon, these game domains have driven research by providing sophisticated yet well-defined challenges for artificial intelligence practitioners. We continue this tradition by proposing the game of Hanabi as a new challenge domain with novel problems that arise from its combination of purely cooperative gameplay and imperfect information in a two to five player setting. In particular, we argue that Hanabi elevates reasoning about the beliefs and intentions of other agents to the foreground. We believe developing novel techniques capable of imbuing artificial agents with such theory of mind will not only be crucial for their success in Hanabi, but also in broader collaborative efforts, and especially those with human partners. To facilitate future research, we introduce the open-source Hanabi Learning Environment, propose an experimental framework for the research community to evaluate algorithmic advances, and assess the performance of current state-of-the-art techniques.
Malthusian Reinforcement Learning
Dec 17, 2018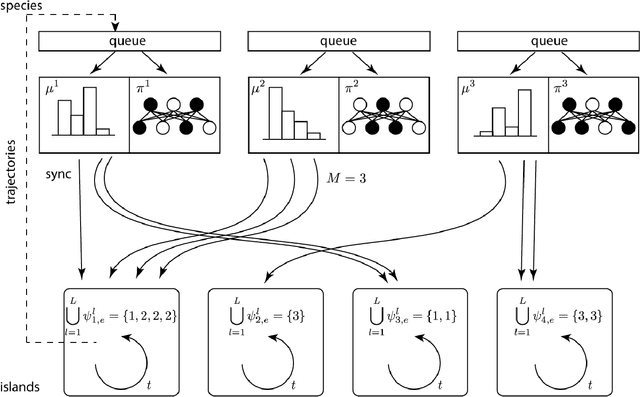
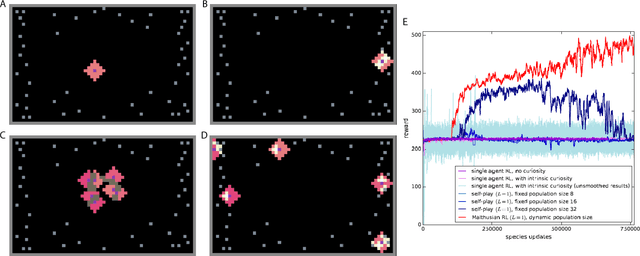
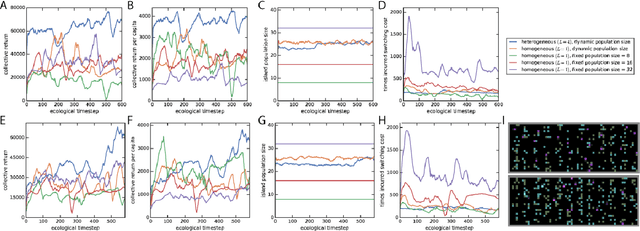
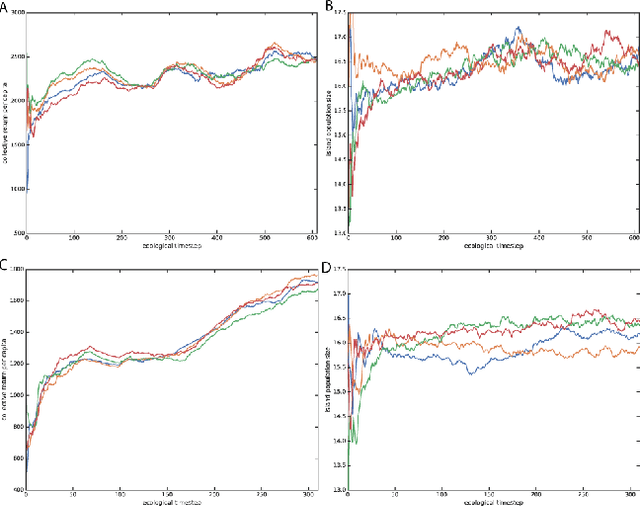
Here we explore a new algorithmic framework for multi-agent reinforcement learning, called Malthusian reinforcement learning, which extends self-play to include fitness-linked population size dynamics that drive ongoing innovation. In Malthusian RL, increases in a subpopulation's average return drive subsequent increases in its size, just as Thomas Malthus argued in 1798 was the relationship between preindustrial income levels and population growth. Malthusian reinforcement learning harnesses the competitive pressures arising from growing and shrinking population size to drive agents to explore regions of state and policy spaces that they could not otherwise reach. Furthermore, in environments where there are potential gains from specialization and division of labor, we show that Malthusian reinforcement learning is better positioned to take advantage of such synergies than algorithms based on self-play.
Bayesian Action Decoder for Deep Multi-Agent Reinforcement Learning
Nov 04, 2018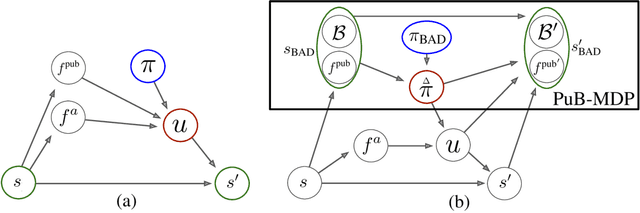
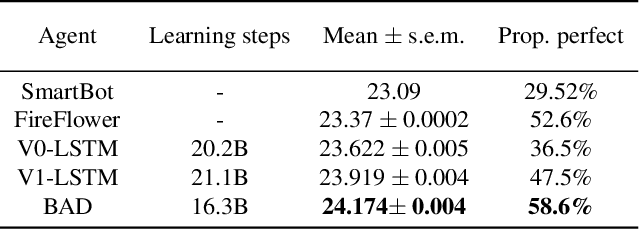
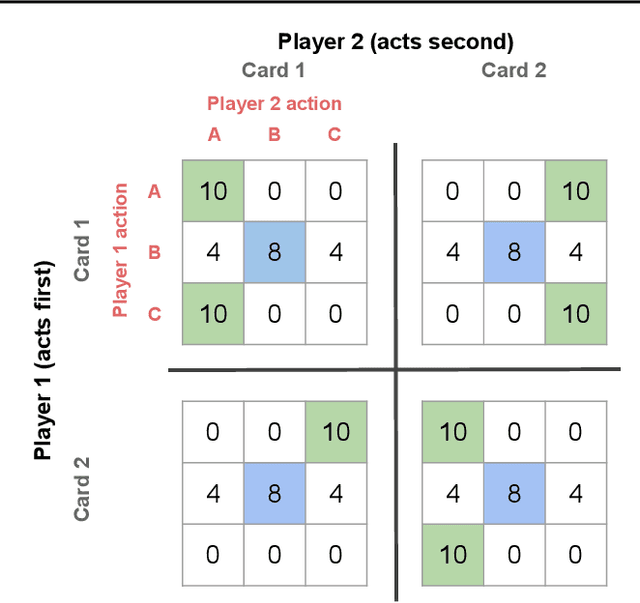
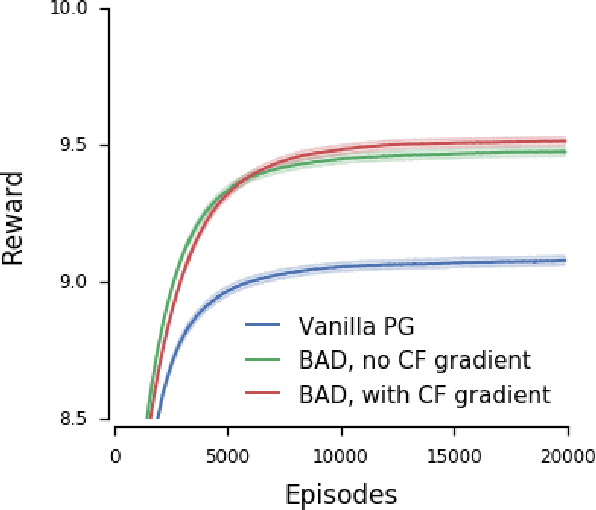
When observing the actions of others, humans carry out inferences about why the others acted as they did, and what this implies about their view of the world. Humans also use the fact that their actions will be interpreted in this manner when observed by others, allowing them to act informatively and thereby communicate efficiently with others. Although learning algorithms have recently achieved superhuman performance in a number of two-player, zero-sum games, scalable multi-agent reinforcement learning algorithms that can discover effective strategies and conventions in complex, partially observable settings have proven elusive. We present the Bayesian action decoder (BAD), a new multi-agent learning method that uses an approximate Bayesian update to obtain a public belief that conditions on the actions taken by all agents in the environment. Together with the public belief, this Bayesian update effectively defines a new Markov decision process, the public belief MDP, in which the action space consists of deterministic partial policies, parameterised by deep neural networks, that can be sampled for a given public state. It exploits the fact that an agent acting only on this public belief state can still learn to use its private information if the action space is augmented to be over partial policies mapping private information into environment actions. The Bayesian update is also closely related to the theory of mind reasoning that humans carry out when observing others' actions. We first validate BAD on a proof-of-principle two-step matrix game, where it outperforms traditional policy gradient methods. We then evaluate BAD on the challenging, cooperative partial-information card game Hanabi, where in the two-player setting the method surpasses all previously published learning and hand-coded approaches.
Inequity aversion improves cooperation in intertemporal social dilemmas
Sep 27, 2018
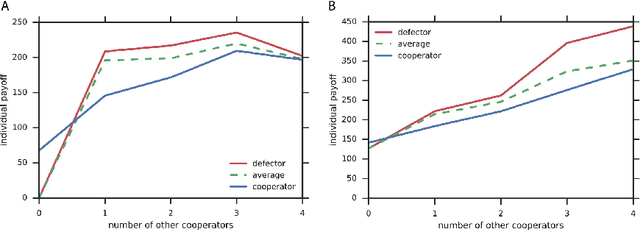
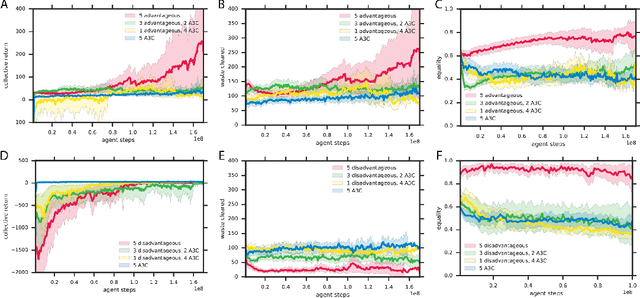
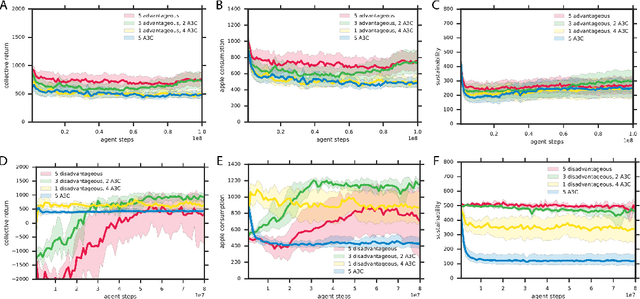
Groups of humans are often able to find ways to cooperate with one another in complex, temporally extended social dilemmas. Models based on behavioral economics are only able to explain this phenomenon for unrealistic stateless matrix games. Recently, multi-agent reinforcement learning has been applied to generalize social dilemma problems to temporally and spatially extended Markov games. However, this has not yet generated an agent that learns to cooperate in social dilemmas as humans do. A key insight is that many, but not all, human individuals have inequity averse social preferences. This promotes a particular resolution of the matrix game social dilemma wherein inequity-averse individuals are personally pro-social and punish defectors. Here we extend this idea to Markov games and show that it promotes cooperation in several types of sequential social dilemma, via a profitable interaction with policy learnability. In particular, we find that inequity aversion improves temporal credit assignment for the important class of intertemporal social dilemmas. These results help explain how large-scale cooperation may emerge and persist.
Human-level performance in first-person multiplayer games with population-based deep reinforcement learning
Jul 03, 2018Recent progress in artificial intelligence through reinforcement learning (RL) has shown great success on increasingly complex single-agent environments and two-player turn-based games. However, the real-world contains multiple agents, each learning and acting independently to cooperate and compete with other agents, and environments reflecting this degree of complexity remain an open challenge. In this work, we demonstrate for the first time that an agent can achieve human-level in a popular 3D multiplayer first-person video game, Quake III Arena Capture the Flag, using only pixels and game points as input. These results were achieved by a novel two-tier optimisation process in which a population of independent RL agents are trained concurrently from thousands of parallel matches with agents playing in teams together and against each other on randomly generated environments. Each agent in the population learns its own internal reward signal to complement the sparse delayed reward from winning, and selects actions using a novel temporally hierarchical representation that enables the agent to reason at multiple timescales. During game-play, these agents display human-like behaviours such as navigating, following, and defending based on a rich learned representation that is shown to encode high-level game knowledge. In an extensive tournament-style evaluation the trained agents exceeded the win-rate of strong human players both as teammates and opponents, and proved far stronger than existing state-of-the-art agents. These results demonstrate a significant jump in the capabilities of artificial agents, bringing us closer to the goal of human-level intelligence.
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
Jun 28, 2018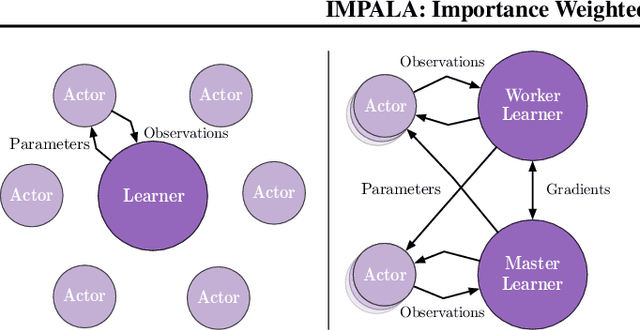
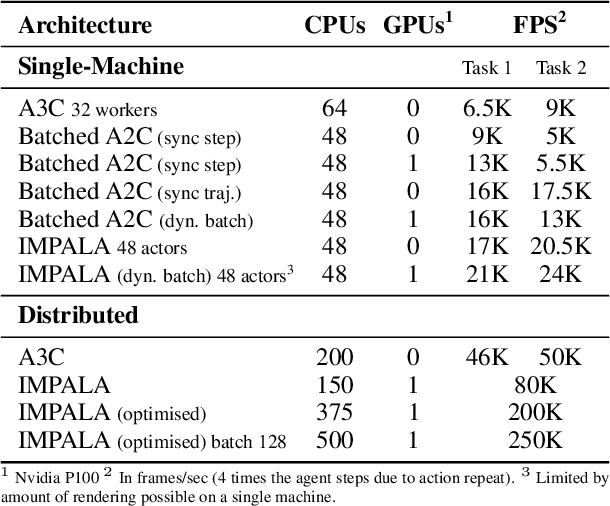
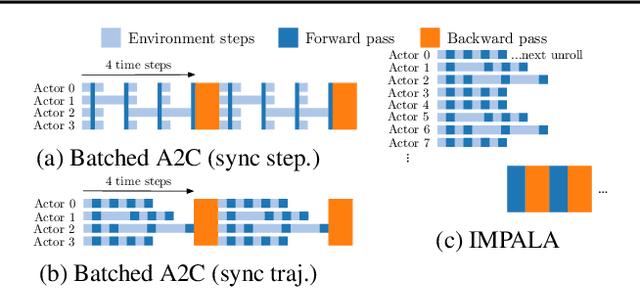
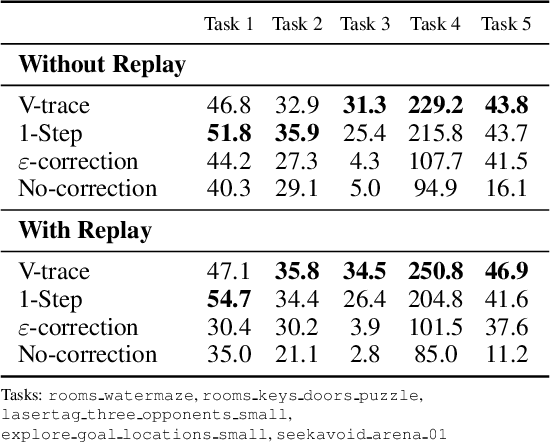
In this work we aim to solve a large collection of tasks using a single reinforcement learning agent with a single set of parameters. A key challenge is to handle the increased amount of data and extended training time. We have developed a new distributed agent IMPALA (Importance Weighted Actor-Learner Architecture) that not only uses resources more efficiently in single-machine training but also scales to thousands of machines without sacrificing data efficiency or resource utilisation. We achieve stable learning at high throughput by combining decoupled acting and learning with a novel off-policy correction method called V-trace. We demonstrate the effectiveness of IMPALA for multi-task reinforcement learning on DMLab-30 (a set of 30 tasks from the DeepMind Lab environment (Beattie et al., 2016)) and Atari-57 (all available Atari games in Arcade Learning Environment (Bellemare et al., 2013a)). Our results show that IMPALA is able to achieve better performance than previous agents with less data, and crucially exhibits positive transfer between tasks as a result of its multi-task approach.
Population Based Training of Neural Networks
Nov 28, 2017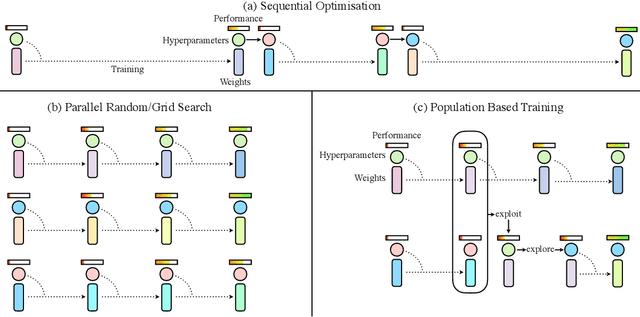

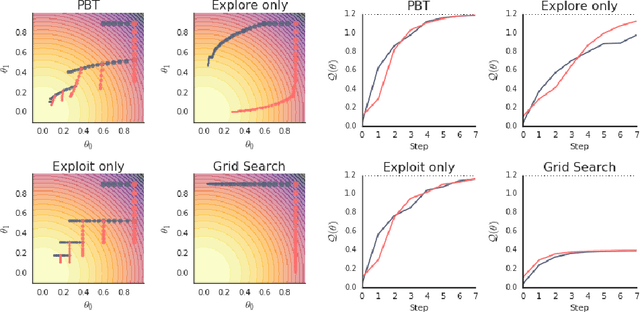
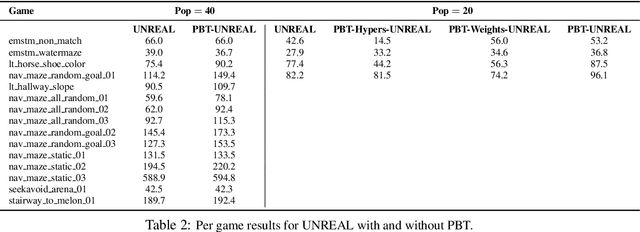
Neural networks dominate the modern machine learning landscape, but their training and success still suffer from sensitivity to empirical choices of hyperparameters such as model architecture, loss function, and optimisation algorithm. In this work we present \emph{Population Based Training (PBT)}, a simple asynchronous optimisation algorithm which effectively utilises a fixed computational budget to jointly optimise a population of models and their hyperparameters to maximise performance. Importantly, PBT discovers a schedule of hyperparameter settings rather than following the generally sub-optimal strategy of trying to find a single fixed set to use for the whole course of training. With just a small modification to a typical distributed hyperparameter training framework, our method allows robust and reliable training of models. We demonstrate the effectiveness of PBT on deep reinforcement learning problems, showing faster wall-clock convergence and higher final performance of agents by optimising over a suite of hyperparameters. In addition, we show the same method can be applied to supervised learning for machine translation, where PBT is used to maximise the BLEU score directly, and also to training of Generative Adversarial Networks to maximise the Inception score of generated images. In all cases PBT results in the automatic discovery of hyperparameter schedules and model selection which results in stable training and better final performance.