 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInequity aversion improves cooperation in intertemporal social dilemmas
Sep 27, 2018
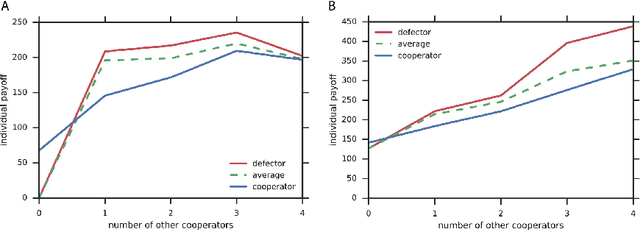
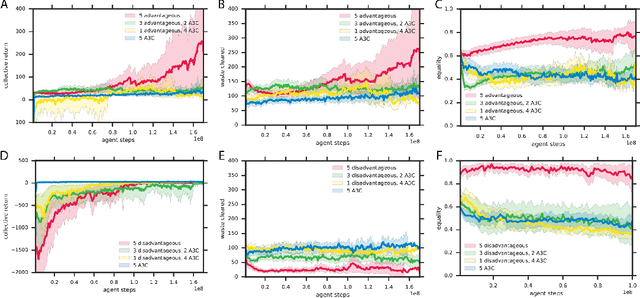
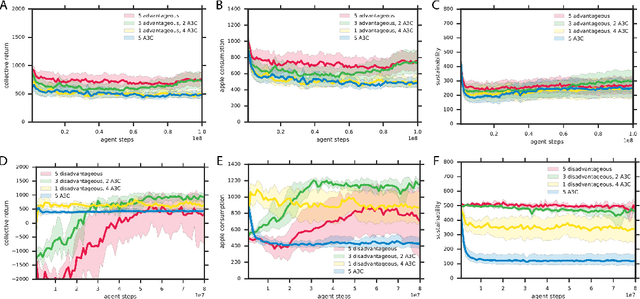
Groups of humans are often able to find ways to cooperate with one another in complex, temporally extended social dilemmas. Models based on behavioral economics are only able to explain this phenomenon for unrealistic stateless matrix games. Recently, multi-agent reinforcement learning has been applied to generalize social dilemma problems to temporally and spatially extended Markov games. However, this has not yet generated an agent that learns to cooperate in social dilemmas as humans do. A key insight is that many, but not all, human individuals have inequity averse social preferences. This promotes a particular resolution of the matrix game social dilemma wherein inequity-averse individuals are personally pro-social and punish defectors. Here we extend this idea to Markov games and show that it promotes cooperation in several types of sequential social dilemma, via a profitable interaction with policy learnability. In particular, we find that inequity aversion improves temporal credit assignment for the important class of intertemporal social dilemmas. These results help explain how large-scale cooperation may emerge and persist.
Psychlab: A Psychology Laboratory for Deep Reinforcement Learning Agents
Feb 04, 2018


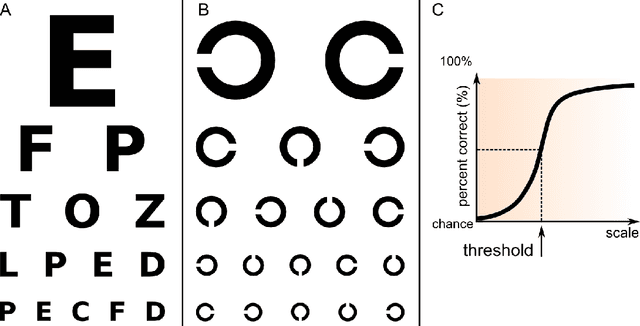
Psychlab is a simulated psychology laboratory inside the first-person 3D game world of DeepMind Lab (Beattie et al. 2016). Psychlab enables implementations of classical laboratory psychological experiments so that they work with both human and artificial agents. Psychlab has a simple and flexible API that enables users to easily create their own tasks. As examples, we are releasing Psychlab implementations of several classical experimental paradigms including visual search, change detection, random dot motion discrimination, and multiple object tracking. We also contribute a study of the visual psychophysics of a specific state-of-the-art deep reinforcement learning agent: UNREAL (Jaderberg et al. 2016). This study leads to the surprising conclusion that UNREAL learns more quickly about larger target stimuli than it does about smaller stimuli. In turn, this insight motivates a specific improvement in the form of a simple model of foveal vision that turns out to significantly boost UNREAL's performance, both on Psychlab tasks, and on standard DeepMind Lab tasks. By open-sourcing Psychlab we hope to facilitate a range of future such studies that simultaneously advance deep reinforcement learning and improve its links with cognitive science.