 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlayer of Games
Dec 06, 2021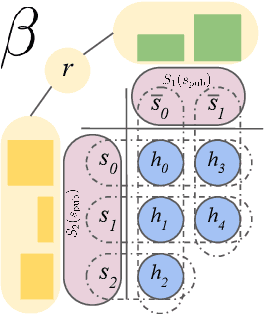

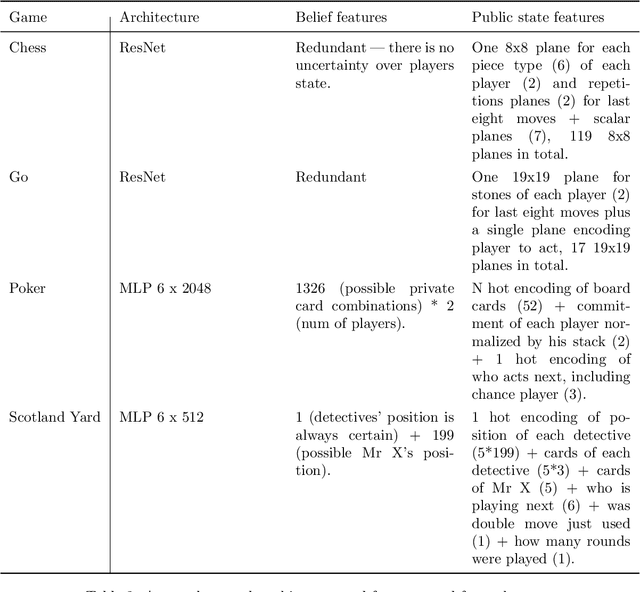
Games have a long history of serving as a benchmark for progress in artificial intelligence. Recently, approaches using search and learning have shown strong performance across a set of perfect information games, and approaches using game-theoretic reasoning and learning have shown strong performance for specific imperfect information poker variants. We introduce Player of Games, a general-purpose algorithm that unifies previous approaches, combining guided search, self-play learning, and game-theoretic reasoning. Player of Games is the first algorithm to achieve strong empirical performance in large perfect and imperfect information games -- an important step towards truly general algorithms for arbitrary environments. We prove that Player of Games is sound, converging to perfect play as available computation time and approximation capacity increases. Player of Games reaches strong performance in chess and Go, beats the strongest openly available agent in heads-up no-limit Texas hold'em poker (Slumbot), and defeats the state-of-the-art agent in Scotland Yard, an imperfect information game that illustrates the value of guided search, learning, and game-theoretic reasoning.
Human-Agent Cooperation in Bridge Bidding
Nov 28, 2020
We introduce a human-compatible reinforcement-learning approach to a cooperative game, making use of a third-party hand-coded human-compatible bot to generate initial training data and to perform initial evaluation. Our learning approach consists of imitation learning, search, and policy iteration. Our trained agents achieve a new state-of-the-art for bridge bidding in three settings: an agent playing in partnership with a copy of itself; an agent partnering a pre-existing bot; and an agent partnering a human player.
The Hanabi Challenge: A New Frontier for AI Research
Feb 01, 2019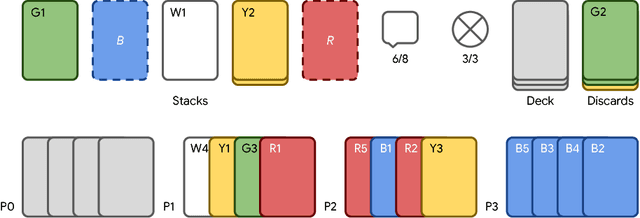
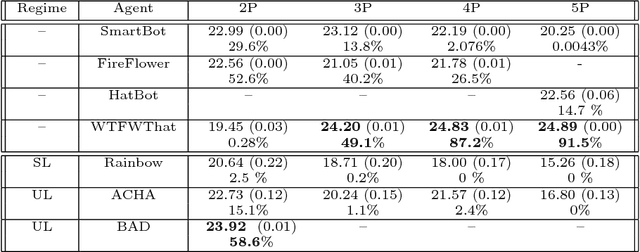
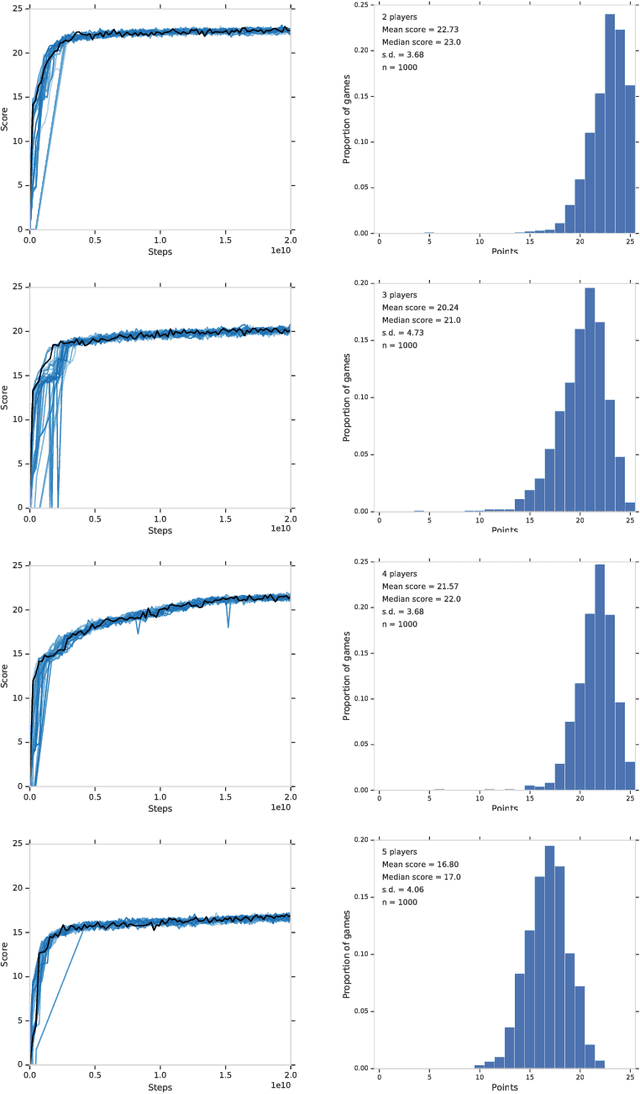
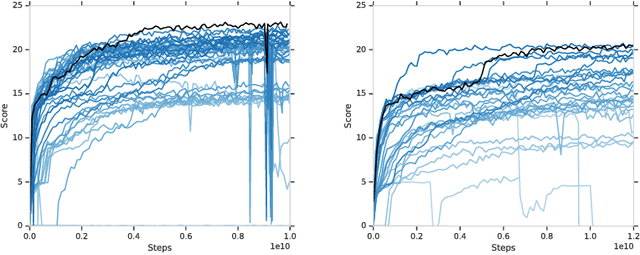
From the early days of computing, games have been important testbeds for studying how well machines can do sophisticated decision making. In recent years, machine learning has made dramatic advances with artificial agents reaching superhuman performance in challenge domains like Go, Atari, and some variants of poker. As with their predecessors of chess, checkers, and backgammon, these game domains have driven research by providing sophisticated yet well-defined challenges for artificial intelligence practitioners. We continue this tradition by proposing the game of Hanabi as a new challenge domain with novel problems that arise from its combination of purely cooperative gameplay and imperfect information in a two to five player setting. In particular, we argue that Hanabi elevates reasoning about the beliefs and intentions of other agents to the foreground. We believe developing novel techniques capable of imbuing artificial agents with such theory of mind will not only be crucial for their success in Hanabi, but also in broader collaborative efforts, and especially those with human partners. To facilitate future research, we introduce the open-source Hanabi Learning Environment, propose an experimental framework for the research community to evaluate algorithmic advances, and assess the performance of current state-of-the-art techniques.
DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker
Mar 03, 2017Artificial intelligence has seen several breakthroughs in recent years, with games often serving as milestones. A common feature of these games is that players have perfect information. Poker is the quintessential game of imperfect information, and a longstanding challenge problem in artificial intelligence. We introduce DeepStack, an algorithm for imperfect information settings. It combines recursive reasoning to handle information asymmetry, decomposition to focus computation on the relevant decision, and a form of intuition that is automatically learned from self-play using deep learning. In a study involving 44,000 hands of poker, DeepStack defeated with statistical significance professional poker players in heads-up no-limit Texas hold'em. The approach is theoretically sound and is shown to produce more difficult to exploit strategies than prior approaches.