 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlayer of Games
Dec 06, 2021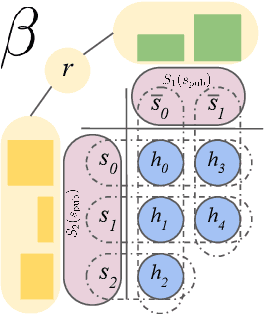

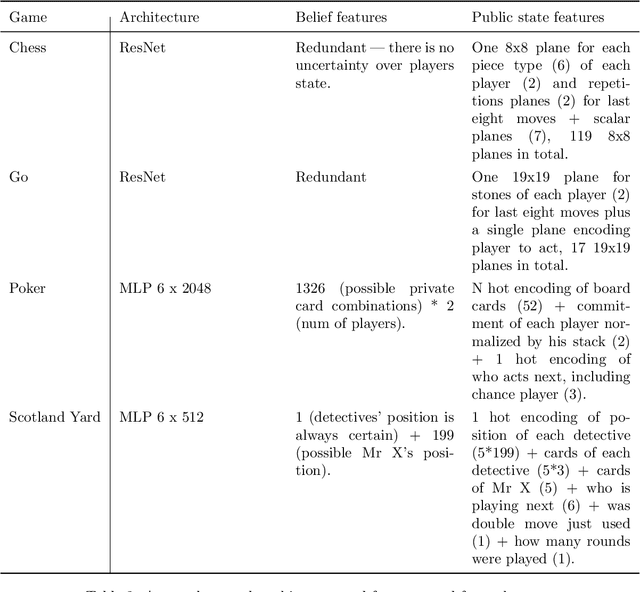
Games have a long history of serving as a benchmark for progress in artificial intelligence. Recently, approaches using search and learning have shown strong performance across a set of perfect information games, and approaches using game-theoretic reasoning and learning have shown strong performance for specific imperfect information poker variants. We introduce Player of Games, a general-purpose algorithm that unifies previous approaches, combining guided search, self-play learning, and game-theoretic reasoning. Player of Games is the first algorithm to achieve strong empirical performance in large perfect and imperfect information games -- an important step towards truly general algorithms for arbitrary environments. We prove that Player of Games is sound, converging to perfect play as available computation time and approximation capacity increases. Player of Games reaches strong performance in chess and Go, beats the strongest openly available agent in heads-up no-limit Texas hold'em poker (Slumbot), and defeats the state-of-the-art agent in Scotland Yard, an imperfect information game that illustrates the value of guided search, learning, and game-theoretic reasoning.
Variance Reduction in Monte Carlo Counterfactual Regret Minimization (VR-MCCFR) for Extensive Form Games using Baselines
Sep 09, 2018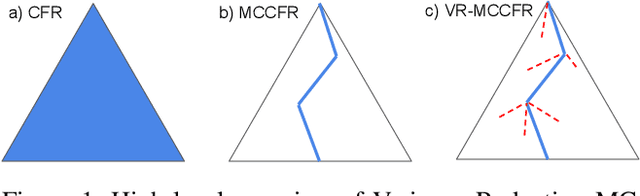
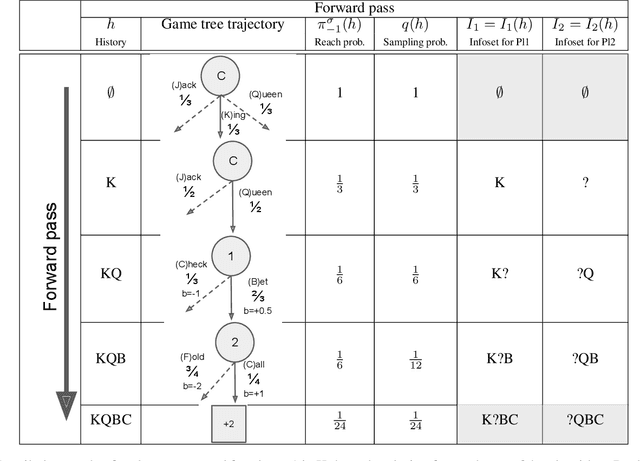
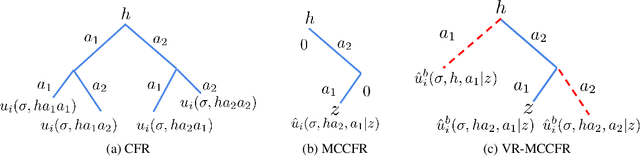
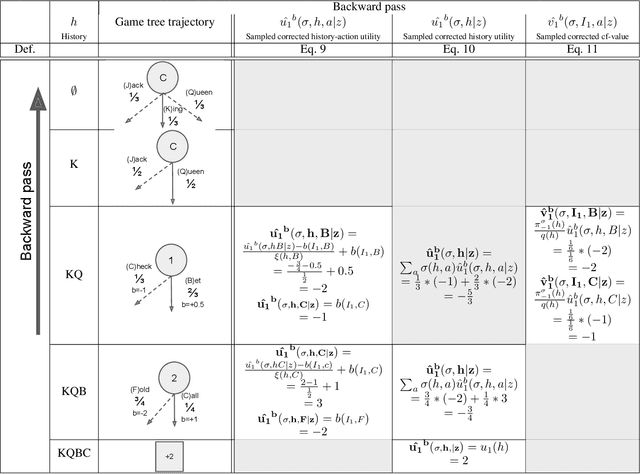
Learning strategies for imperfect information games from samples of interaction is a challenging problem. A common method for this setting, Monte Carlo Counterfactual Regret Minimization (MCCFR), can have slow long-term convergence rates due to high variance. In this paper, we introduce a variance reduction technique (VR-MCCFR) that applies to any sampling variant of MCCFR. Using this technique, per-iteration estimated values and updates are reformulated as a function of sampled values and state-action baselines, similar to their use in policy gradient reinforcement learning. The new formulation allows estimates to be bootstrapped from other estimates within the same episode, propagating the benefits of baselines along the sampled trajectory; the estimates remain unbiased even when bootstrapping from other estimates. Finally, we show that given a perfect baseline, the variance of the value estimates can be reduced to zero. Experimental evaluation shows that VR-MCCFR brings an order of magnitude speedup, while the empirical variance decreases by three orders of magnitude. The decreased variance allows for the first time CFR+ to be used with sampling, increasing the speedup to two orders of magnitude.
A Boo(n) for Evaluating Architecture Performance
Jul 23, 2018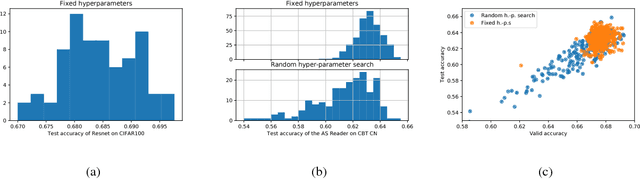

We point out important problems with the common practice of using the best single model performance for comparing deep learning architectures, and we propose a method that corrects these flaws. Each time a model is trained, one gets a different result due to random factors in the training process, which include random parameter initialization and random data shuffling. Reporting the best single model performance does not appropriately address this stochasticity. We propose a normalized expected best-out-of-$n$ performance ($\text{Boo}_n$) as a way to correct these problems.
* ICML 2018
Knowledge Base Completion: Baselines Strike Back
May 30, 2017
Many papers have been published on the knowledge base completion task in the past few years. Most of these introduce novel architectures for relation learning that are evaluated on standard datasets such as FB15k and WN18. This paper shows that the accuracy of almost all models published on the FB15k can be outperformed by an appropriately tuned baseline - our reimplementation of the DistMult model. Our findings cast doubt on the claim that the performance improvements of recent models are due to architectural changes as opposed to hyper-parameter tuning or different training objectives. This should prompt future research to re-consider how the performance of models is evaluated and reported.
Hybrid Dialog State Tracker with ASR Features
Feb 21, 2017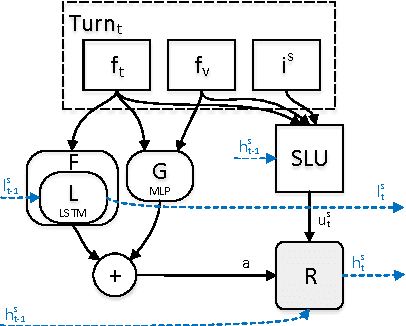
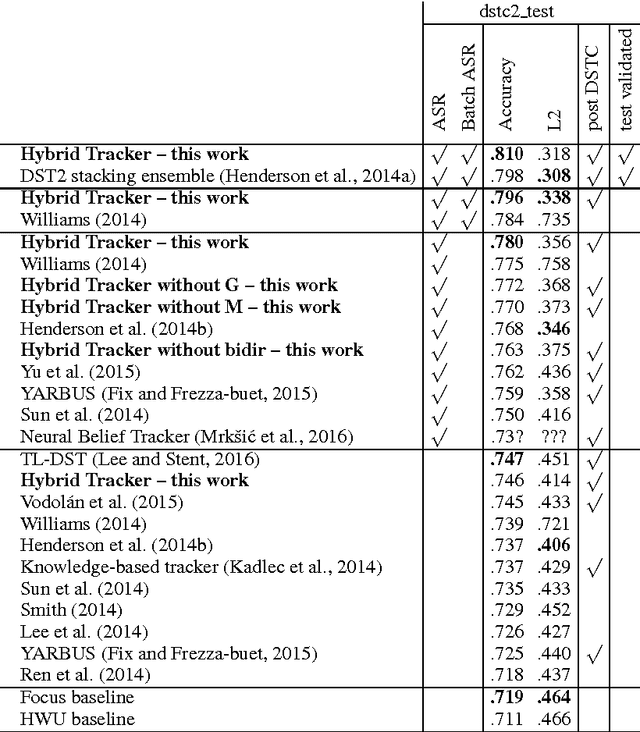
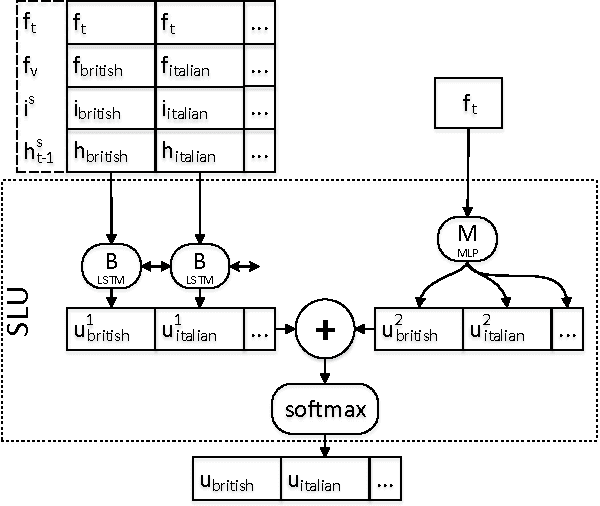
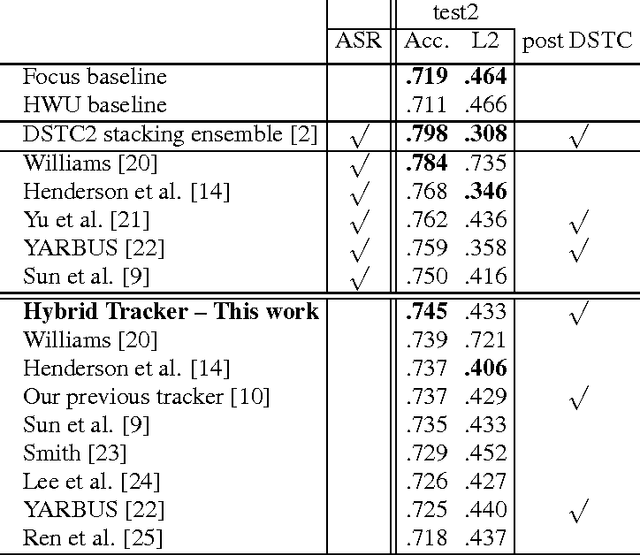
This paper presents a hybrid dialog state tracker enhanced by trainable Spoken Language Understanding (SLU) for slot-filling dialog systems. Our architecture is inspired by previously proposed neural-network-based belief-tracking systems. In addition, we extended some parts of our modular architecture with differentiable rules to allow end-to-end training. We hypothesize that these rules allow our tracker to generalize better than pure machine-learning based systems. For evaluation, we used the Dialog State Tracking Challenge (DSTC) 2 dataset - a popular belief tracking testbed with dialogs from restaurant information system. To our knowledge, our hybrid tracker sets a new state-of-the-art result in three out of four categories within the DSTC2.
Embracing data abundance: BookTest Dataset for Reading Comprehension
Oct 04, 2016
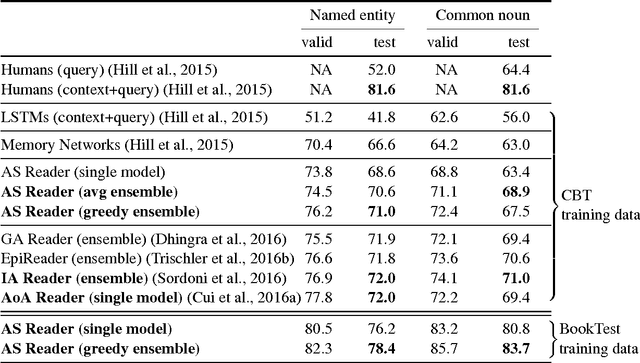

There is a practically unlimited amount of natural language data available. Still, recent work in text comprehension has focused on datasets which are small relative to current computing possibilities. This article is making a case for the community to move to larger data and as a step in that direction it is proposing the BookTest, a new dataset similar to the popular Children's Book Test (CBT), however more than 60 times larger. We show that training on the new data improves the accuracy of our Attention-Sum Reader model on the original CBT test data by a much larger margin than many recent attempts to improve the model architecture. On one version of the dataset our ensemble even exceeds the human baseline provided by Facebook. We then show in our own human study that there is still space for further improvement.
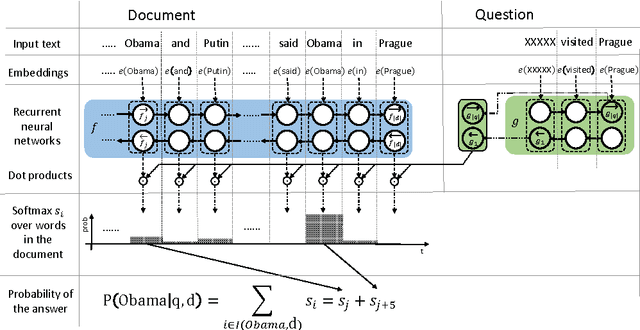
Text Understanding with the Attention Sum Reader Network
Jun 24, 2016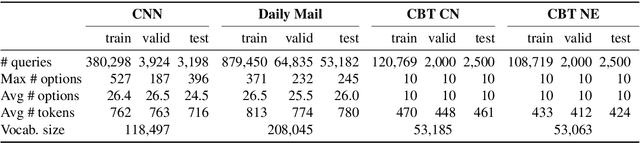
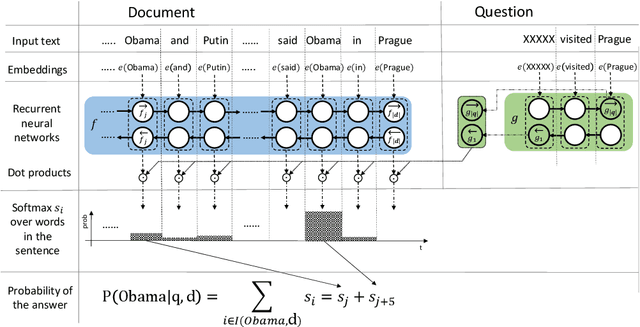
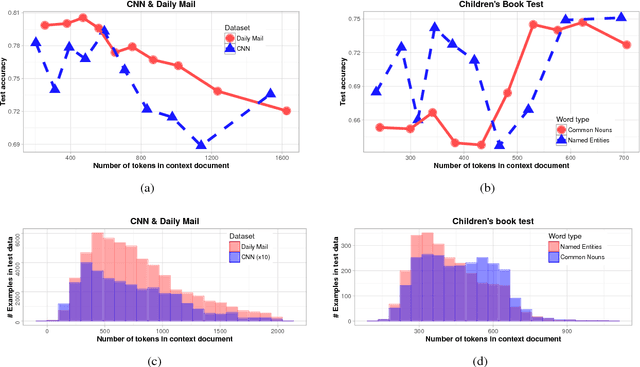
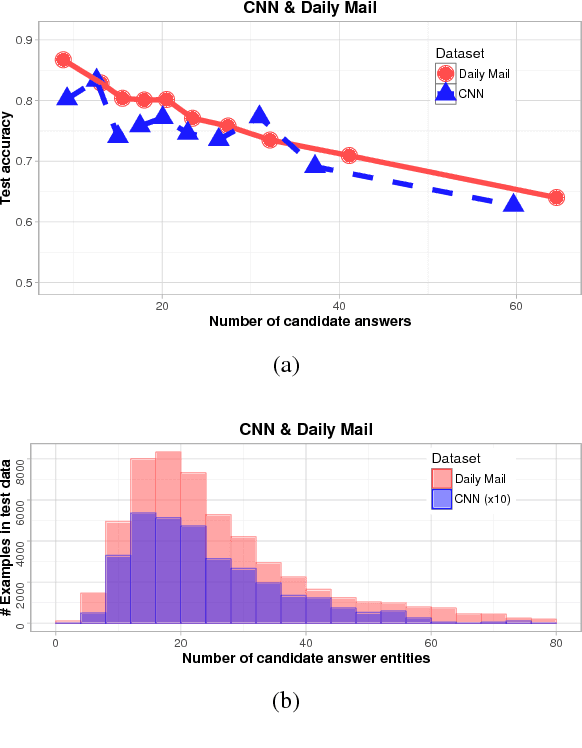
Several large cloze-style context-question-answer datasets have been introduced recently: the CNN and Daily Mail news data and the Children's Book Test. Thanks to the size of these datasets, the associated text comprehension task is well suited for deep-learning techniques that currently seem to outperform all alternative approaches. We present a new, simple model that uses attention to directly pick the answer from the context as opposed to computing the answer using a blended representation of words in the document as is usual in similar models. This makes the model particularly suitable for question-answering problems where the answer is a single word from the document. Ensemble of our models sets new state of the art on all evaluated datasets.
Hybrid Dialog State Tracker
Jan 14, 2016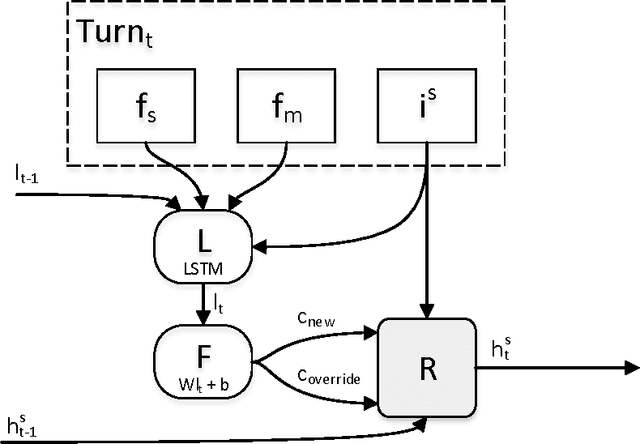
This paper presents a hybrid dialog state tracker that combines a rule based and a machine learning based approach to belief state tracking. Therefore, we call it a hybrid tracker. The machine learning in our tracker is realized by a Long Short Term Memory (LSTM) network. To our knowledge, our hybrid tracker sets a new state-of-the-art result for the Dialog State Tracking Challenge (DSTC) 2 dataset when the system uses only live SLU as its input.
Improved Deep Learning Baselines for Ubuntu Corpus Dialogs
Nov 03, 2015
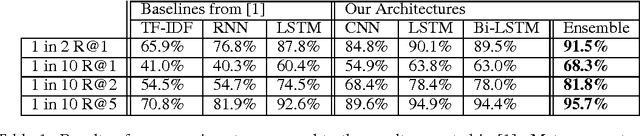
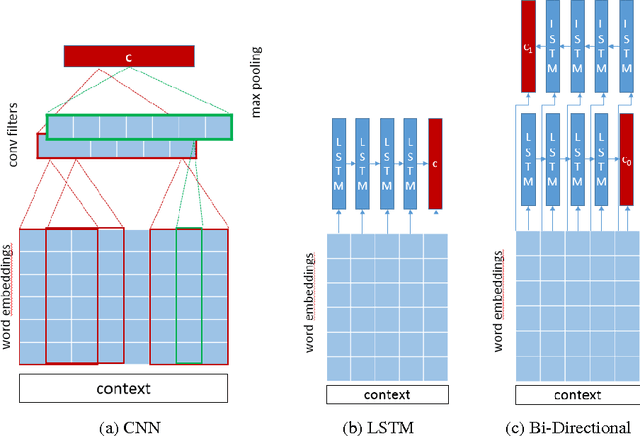
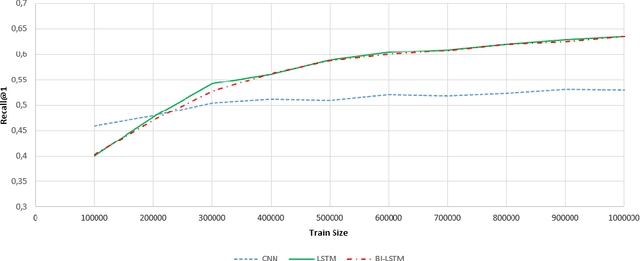
This paper presents results of our experiments for the next utterance ranking on the Ubuntu Dialog Corpus -- the largest publicly available multi-turn dialog corpus. First, we use an in-house implementation of previously reported models to do an independent evaluation using the same data. Second, we evaluate the performances of various LSTMs, Bi-LSTMs and CNNs on the dataset. Third, we create an ensemble by averaging predictions of multiple models. The ensemble further improves the performance and it achieves a state-of-the-art result for the next utterance ranking on this dataset. Finally, we discuss our future plans using this corpus.