 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopulation-based Evaluation in Repeated Rock-Paper-Scissors as a Benchmark for Multiagent Reinforcement Learning
Mar 02, 2023



Progress in fields of machine learning and adversarial planning has benefited significantly from benchmark domains, from checkers and the classic UCI data sets to Go and Diplomacy. In sequential decision-making, agent evaluation has largely been restricted to few interactions against experts, with the aim to reach some desired level of performance (e.g. beating a human professional player). We propose a benchmark for multiagent learning based on repeated play of the simple game Rock, Paper, Scissors along with a population of forty-three tournament entries, some of which are intentionally sub-optimal. We describe metrics to measure the quality of agents based both on average returns and exploitability. We then show that several RL, online learning, and language model approaches can learn good counter-strategies and generalize well, but ultimately lose to the top-performing bots, creating an opportunity for research in multiagent learning.
Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022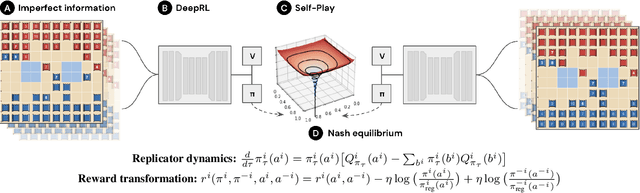
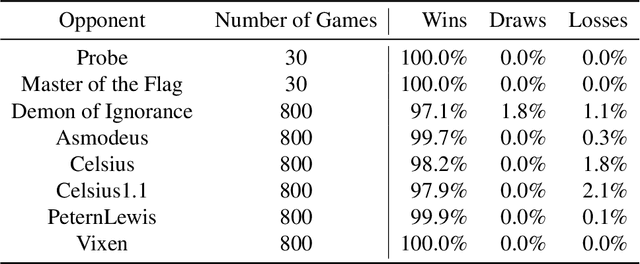
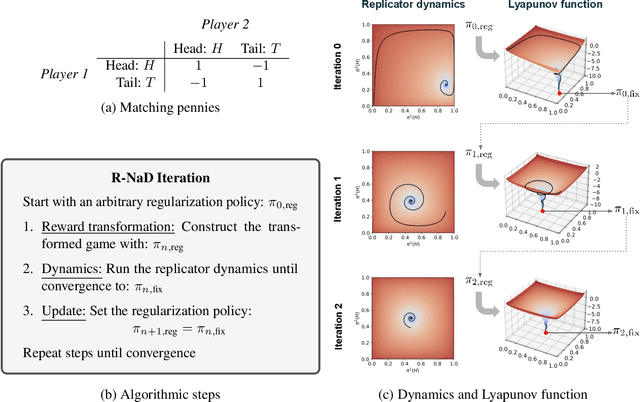

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
Player of Games
Dec 06, 2021

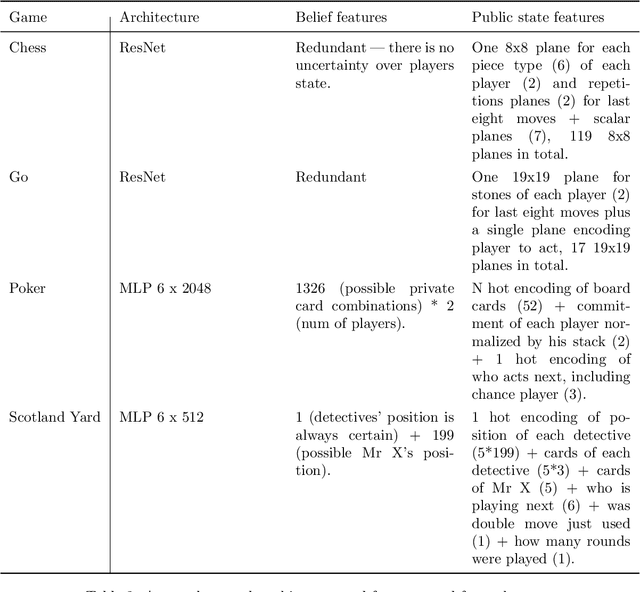
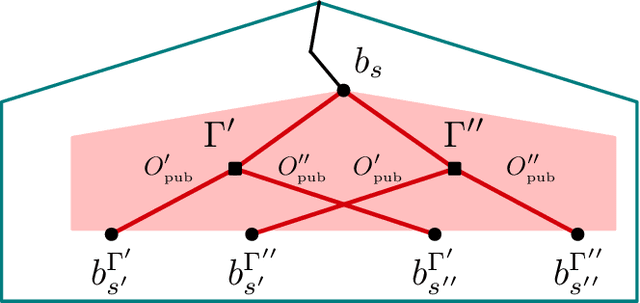
Games have a long history of serving as a benchmark for progress in artificial intelligence. Recently, approaches using search and learning have shown strong performance across a set of perfect information games, and approaches using game-theoretic reasoning and learning have shown strong performance for specific imperfect information poker variants. We introduce Player of Games, a general-purpose algorithm that unifies previous approaches, combining guided search, self-play learning, and game-theoretic reasoning. Player of Games is the first algorithm to achieve strong empirical performance in large perfect and imperfect information games -- an important step towards truly general algorithms for arbitrary environments. We prove that Player of Games is sound, converging to perfect play as available computation time and approximation capacity increases. Player of Games reaches strong performance in chess and Go, beats the strongest openly available agent in heads-up no-limit Texas hold'em poker (Slumbot), and defeats the state-of-the-art agent in Scotland Yard, an imperfect information game that illustrates the value of guided search, learning, and game-theoretic reasoning.
Solving Common-Payoff Games with Approximate Policy Iteration
Jan 11, 2021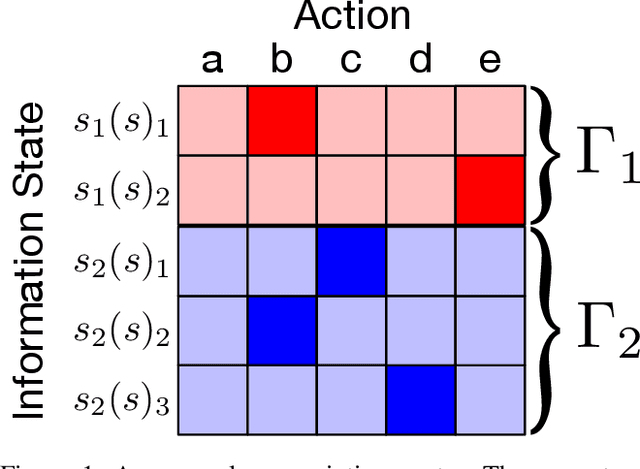
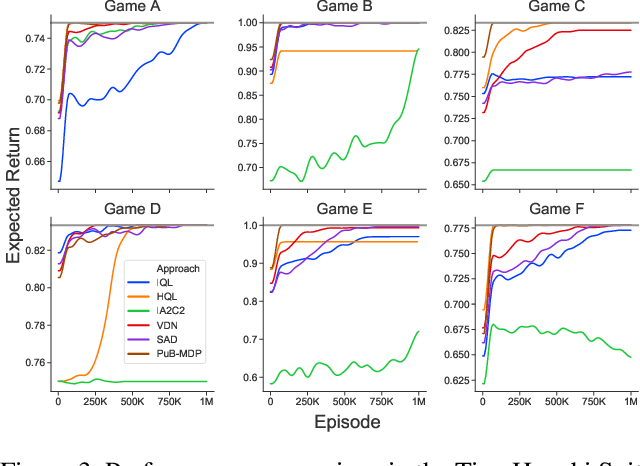
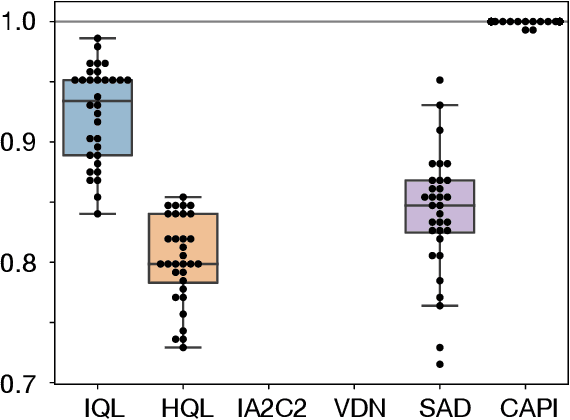
For artificially intelligent learning systems to have widespread applicability in real-world settings, it is important that they be able to operate decentrally. Unfortunately, decentralized control is difficult -- computing even an epsilon-optimal joint policy is a NEXP complete problem. Nevertheless, a recently rediscovered insight -- that a team of agents can coordinate via common knowledge -- has given rise to algorithms capable of finding optimal joint policies in small common-payoff games. The Bayesian action decoder (BAD) leverages this insight and deep reinforcement learning to scale to games as large as two-player Hanabi. However, the approximations it uses to do so prevent it from discovering optimal joint policies even in games small enough to brute force optimal solutions. This work proposes CAPI, a novel algorithm which, like BAD, combines common knowledge with deep reinforcement learning. However, unlike BAD, CAPI prioritizes the propensity to discover optimal joint policies over scalability. While this choice precludes CAPI from scaling to games as large as Hanabi, empirical results demonstrate that, on the games to which CAPI does scale, it is capable of discovering optimal joint policies even when other modern multi-agent reinforcement learning algorithms are unable to do so. Code is available at https://github.com/ssokota/capi .
Human-Agent Cooperation in Bridge Bidding
Nov 28, 2020
We introduce a human-compatible reinforcement-learning approach to a cooperative game, making use of a third-party hand-coded human-compatible bot to generate initial training data and to perform initial evaluation. Our learning approach consists of imitation learning, search, and policy iteration. Our trained agents achieve a new state-of-the-art for bridge bidding in three settings: an agent playing in partnership with a copy of itself; an agent partnering a pre-existing bot; and an agent partnering a human player.
From Poincaré Recurrence to Convergence in Imperfect Information Games: Finding Equilibrium via Regularization
Feb 19, 2020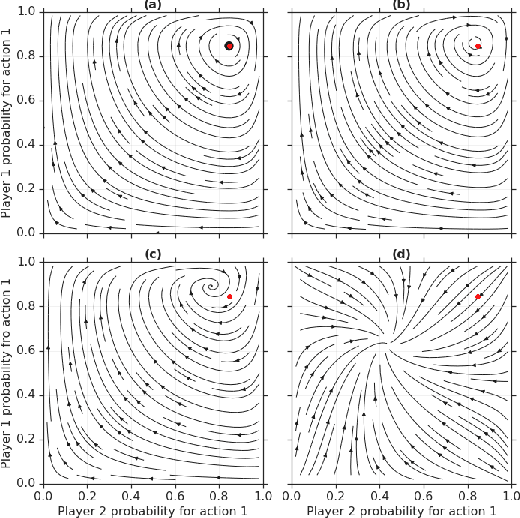
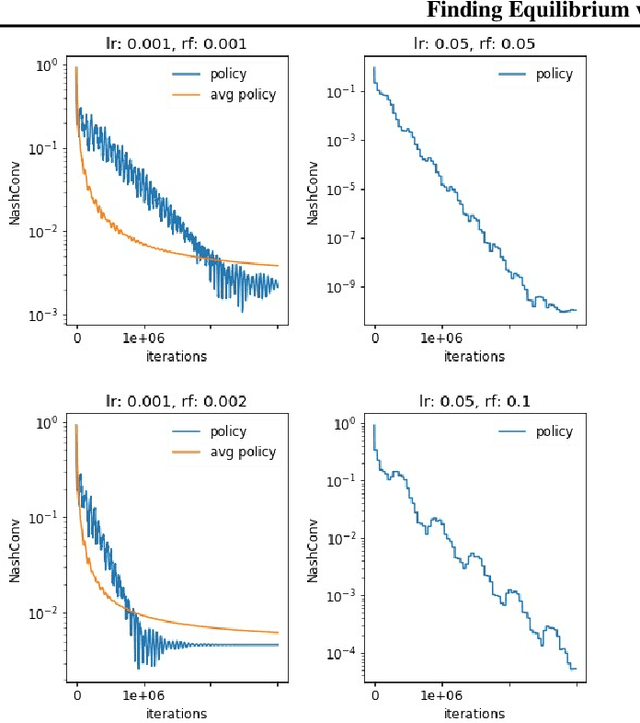
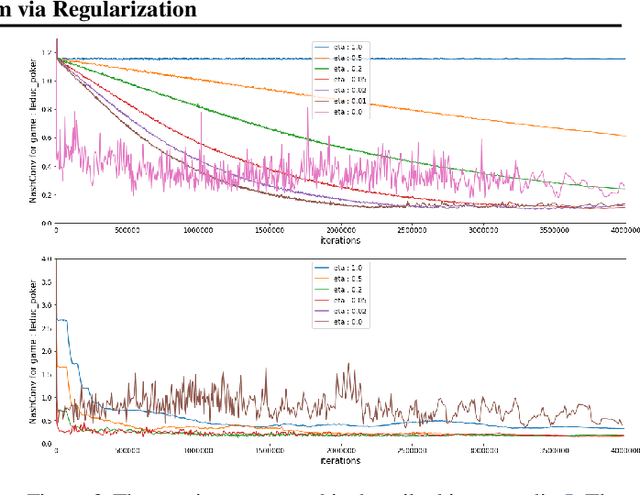

In this paper we investigate the Follow the Regularized Leader dynamics in sequential imperfect information games (IIG). We generalize existing results of Poincar\'e recurrence from normal-form games to zero-sum two-player imperfect information games and other sequential game settings. We then investigate how adapting the reward (by adding a regularization term) of the game can give strong convergence guarantees in monotone games. We continue by showing how this reward adaptation technique can be leveraged to build algorithms that converge exactly to the Nash equilibrium. Finally, we show how these insights can be directly used to build state-of-the-art model-free algorithms for zero-sum two-player Imperfect Information Games (IIG).
Rethinking Formal Models of Partially Observable Multiagent Decision Making
Jun 26, 2019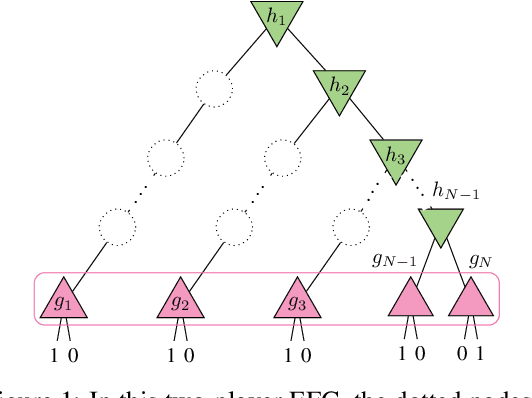
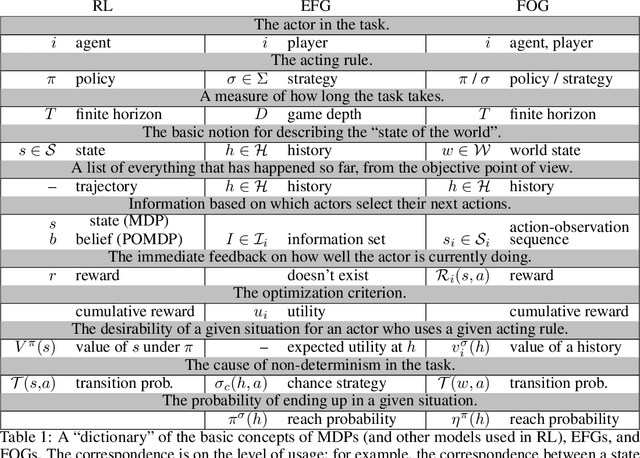
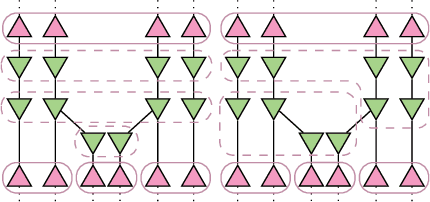
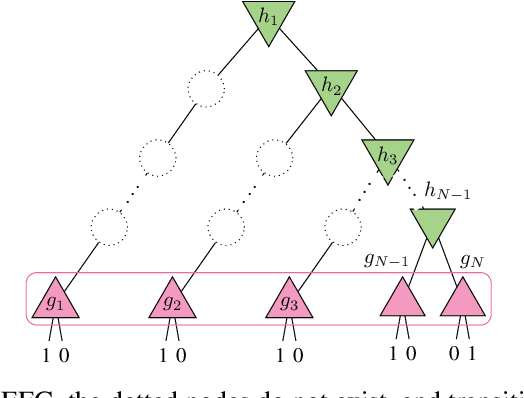
Multiagent decision-making problems in partially observable environments are usually modeled as either extensive-form games (EFGs) within the game theory community or partially observable stochastic games (POSGs) within the reinforcement learning community. While most practical problems can be modeled in both formalisms, the communities using these models are mostly distinct with little sharing of ideas or advances. The last decade has seen dramatic progress in algorithms for EFGs, mainly driven by the challenge problem of poker. We have seen computational techniques achieving super-human performance, some variants of poker are essentially solved, and there are now sound local search algorithms which were previously thought impossible. While the advances have garnered attention, the fundamental advances are not yet understood outside the EFG community. This can be largely explained by the starkly different formalisms between the game theory and reinforcement learning communities and, further, by the unsuitability of the original EFG formalism to make the ideas simple and clear. This paper aims to address these hindrances, by advocating a new unifying formalism, a variant of POSGs, which we call Factored-Observation Games (FOGs). We prove that any timeable perfect-recall EFG can be efficiently modeled as a FOG as well as relating FOGs to other existing formalisms. Additionally, a FOG explicitly identifies the public and private components of observations, which is fundamental to the recent EFG breakthroughs. We conclude by presenting the two building-blocks of these breakthroughs --- counterfactual regret minimization and public state decomposition --- in the new formalism, illustrating our goal of a simpler path for sharing recent advances between game theory and reinforcement learning community.
The Hanabi Challenge: A New Frontier for AI Research
Feb 01, 2019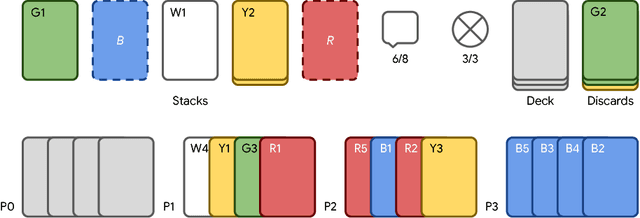
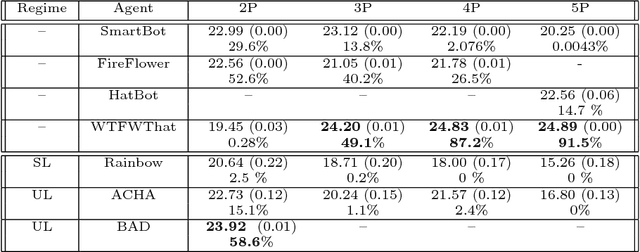
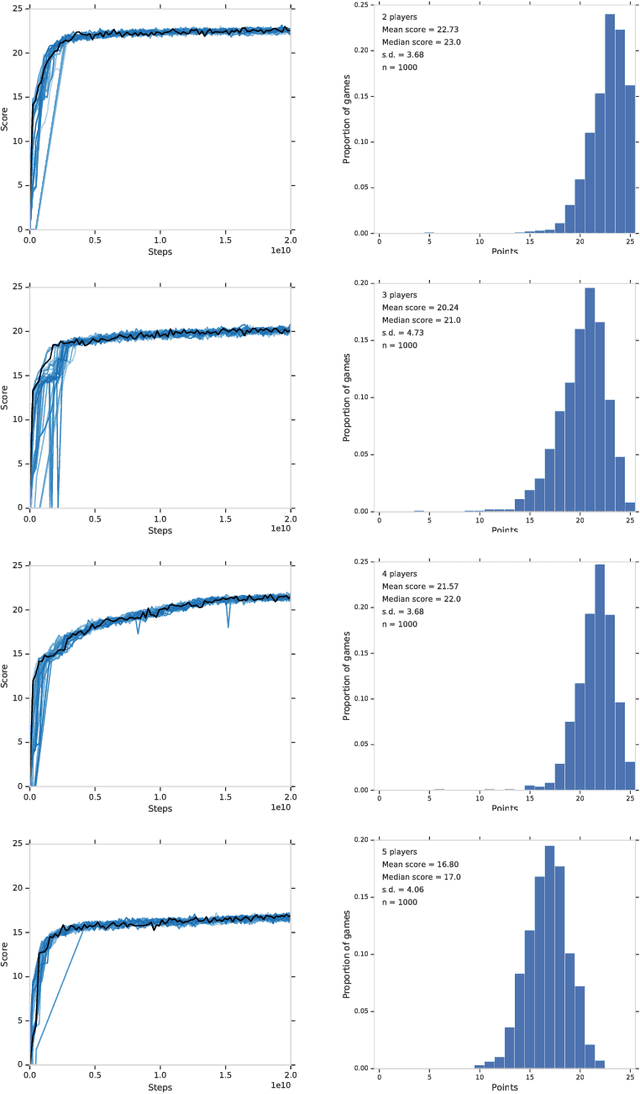
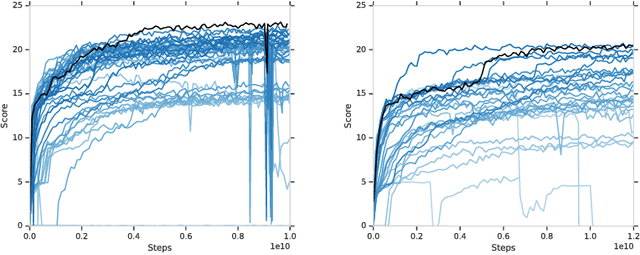
From the early days of computing, games have been important testbeds for studying how well machines can do sophisticated decision making. In recent years, machine learning has made dramatic advances with artificial agents reaching superhuman performance in challenge domains like Go, Atari, and some variants of poker. As with their predecessors of chess, checkers, and backgammon, these game domains have driven research by providing sophisticated yet well-defined challenges for artificial intelligence practitioners. We continue this tradition by proposing the game of Hanabi as a new challenge domain with novel problems that arise from its combination of purely cooperative gameplay and imperfect information in a two to five player setting. In particular, we argue that Hanabi elevates reasoning about the beliefs and intentions of other agents to the foreground. We believe developing novel techniques capable of imbuing artificial agents with such theory of mind will not only be crucial for their success in Hanabi, but also in broader collaborative efforts, and especially those with human partners. To facilitate future research, we introduce the open-source Hanabi Learning Environment, propose an experimental framework for the research community to evaluate algorithmic advances, and assess the performance of current state-of-the-art techniques.
Bayesian Action Decoder for Deep Multi-Agent Reinforcement Learning
Nov 04, 2018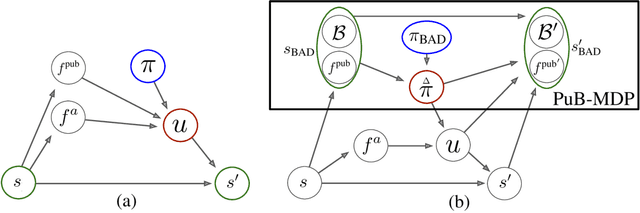
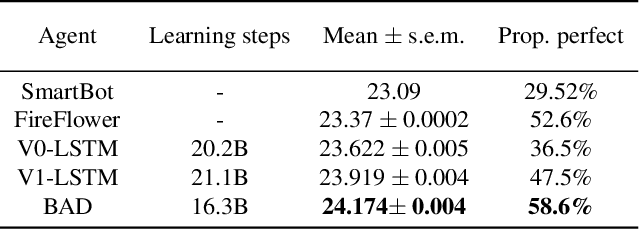
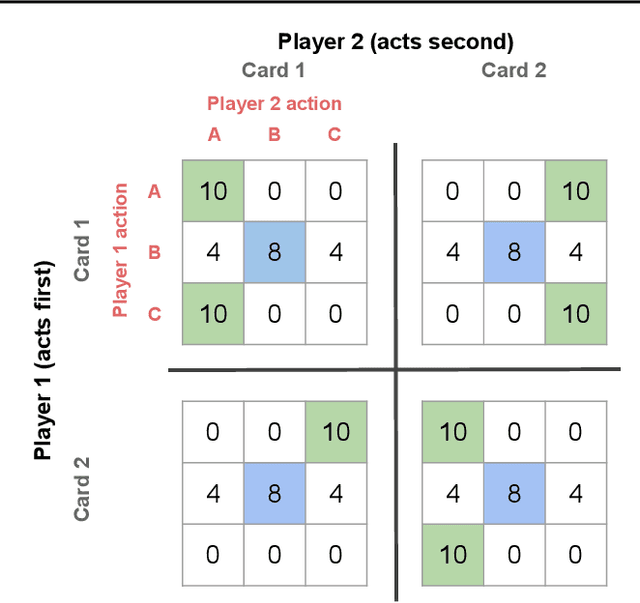
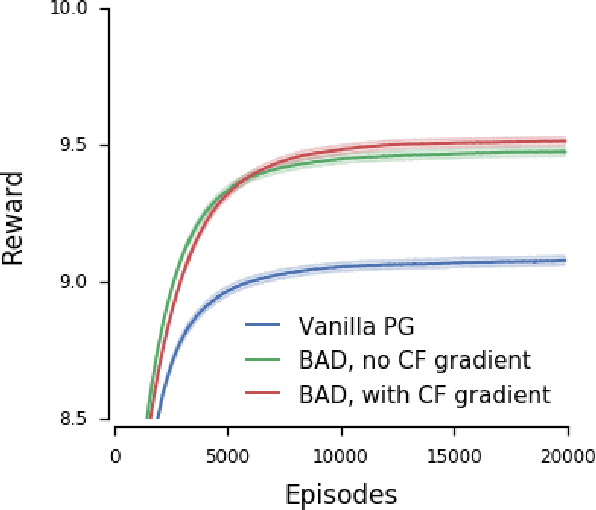
When observing the actions of others, humans carry out inferences about why the others acted as they did, and what this implies about their view of the world. Humans also use the fact that their actions will be interpreted in this manner when observed by others, allowing them to act informatively and thereby communicate efficiently with others. Although learning algorithms have recently achieved superhuman performance in a number of two-player, zero-sum games, scalable multi-agent reinforcement learning algorithms that can discover effective strategies and conventions in complex, partially observable settings have proven elusive. We present the Bayesian action decoder (BAD), a new multi-agent learning method that uses an approximate Bayesian update to obtain a public belief that conditions on the actions taken by all agents in the environment. Together with the public belief, this Bayesian update effectively defines a new Markov decision process, the public belief MDP, in which the action space consists of deterministic partial policies, parameterised by deep neural networks, that can be sampled for a given public state. It exploits the fact that an agent acting only on this public belief state can still learn to use its private information if the action space is augmented to be over partial policies mapping private information into environment actions. The Bayesian update is also closely related to the theory of mind reasoning that humans carry out when observing others' actions. We first validate BAD on a proof-of-principle two-step matrix game, where it outperforms traditional policy gradient methods. We then evaluate BAD on the challenging, cooperative partial-information card game Hanabi, where in the two-player setting the method surpasses all previously published learning and hand-coded approaches.
Variance Reduction in Monte Carlo Counterfactual Regret Minimization (VR-MCCFR) for Extensive Form Games using Baselines
Sep 09, 2018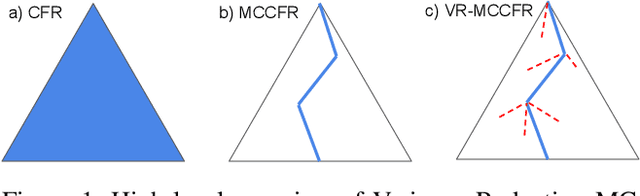
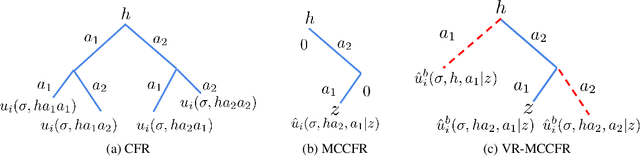
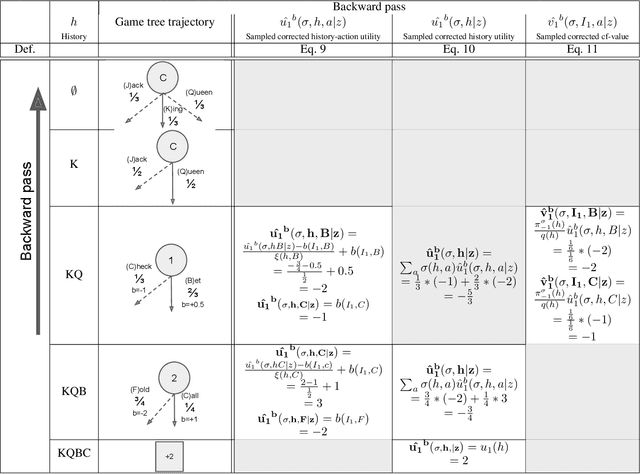
Learning strategies for imperfect information games from samples of interaction is a challenging problem. A common method for this setting, Monte Carlo Counterfactual Regret Minimization (MCCFR), can have slow long-term convergence rates due to high variance. In this paper, we introduce a variance reduction technique (VR-MCCFR) that applies to any sampling variant of MCCFR. Using this technique, per-iteration estimated values and updates are reformulated as a function of sampled values and state-action baselines, similar to their use in policy gradient reinforcement learning. The new formulation allows estimates to be bootstrapped from other estimates within the same episode, propagating the benefits of baselines along the sampled trajectory; the estimates remain unbiased even when bootstrapping from other estimates. Finally, we show that given a perfect baseline, the variance of the value estimates can be reduced to zero. Experimental evaluation shows that VR-MCCFR brings an order of magnitude speedup, while the empirical variance decreases by three orders of magnitude. The decreased variance allows for the first time CFR+ to be used with sampling, increasing the speedup to two orders of magnitude.