 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperhuman AI for Generals.io Using Self-Play Reinforcement Learning
Jun 22, 2026We present a superhuman AI agent for Generals.io, a real-time strategy game that requires both long-horizon planning and short-term tactics under strong imperfect information. Trained for four days on 4x NVIDIA H200 GPUs, our agent reaches #1 on the public 1v1 leaderboard of over 5,000 human players, leading the second-ranked player by the same margin that separates second place from 25th, and beats the two top-ranked humans head-to-head with a combined 199-70 record across 269 ladder matches. A key enabler is a JAX-native simulator that reaches tens of millions of frames per second on a single GPU, roughly a 10,000x speedup over the prior simulator. On top of this, we train a vision transformer policy end-to-end by self-play with a policy-gradient loop and sparse win/loss reward, using top-advantage sample filtering and an exponential moving average of the policy parameters. Taken together, our findings highlight what matters, and what does not, once a fast simulator removes the data bottleneck.
Look-ahead Reasoning with a Learned Model in Imperfect Information Games
Oct 06, 2025Test-time reasoning significantly enhances pre-trained AI agents' performance. However, it requires an explicit environment model, often unavailable or overly complex in real-world scenarios. While MuZero enables effective model learning for search in perfect information games, extending this paradigm to imperfect information games presents substantial challenges due to more nuanced look-ahead reasoning techniques and large number of states relevant for individual decisions. This paper introduces an algorithm LAMIR that learns an abstracted model of an imperfect information game directly from the agent-environment interaction. During test time, this trained model is used to perform look-ahead reasoning. The learned abstraction limits the size of each subgame to a manageable size, making theoretically principled look-ahead reasoning tractable even in games where previous methods could not scale. We empirically demonstrate that with sufficient capacity, LAMIR learns the exact underlying game structure, and with limited capacity, it still learns a valuable abstraction, which improves game playing performance of the pre-trained agents even in large games.
Generation of Games for Opponent Model Differentiation
Nov 28, 2023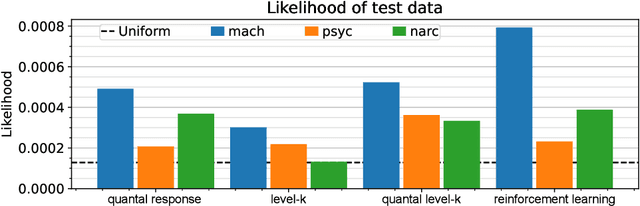

Protecting against adversarial attacks is a common multiagent problem. Attackers in the real world are predominantly human actors, and the protection methods often incorporate opponent models to improve the performance when facing humans. Previous results show that modeling human behavior can significantly improve the performance of the algorithms. However, modeling humans correctly is a complex problem, and the models are often simplified and assume humans make mistakes according to some distribution or train parameters for the whole population from which they sample. In this work, we use data gathered by psychologists who identified personality types that increase the likelihood of performing malicious acts. However, in the previous work, the tests on a handmade game could not show strategic differences between the models. We created a novel model that links its parameters to psychological traits. We optimized over parametrized games and created games in which the differences are profound. Our work can help with automatic game generation when we need a game in which some models will behave differently and to identify situations in which the models do not align.
NASimEmu: Network Attack Simulator & Emulator for Training Agents Generalizing to Novel Scenarios
May 26, 2023Current frameworks for training offensive penetration testing agents with deep reinforcement learning struggle to produce agents that perform well in real-world scenarios, due to the reality gap in simulation-based frameworks and the lack of scalability in emulation-based frameworks. Additionally, existing frameworks often use an unrealistic metric that measures the agents' performance on the training data. NASimEmu, a new framework introduced in this paper, addresses these issues by providing both a simulator and an emulator with a shared interface. This approach allows agents to be trained in simulation and deployed in the emulator, thus verifying the realism of the used abstraction. Our framework promotes the development of general agents that can transfer to novel scenarios unseen during their training. For the simulation part, we adopt an existing simulator NASim and enhance its realism. The emulator is implemented with industry-level tools, such as Vagrant, VirtualBox, and Metasploit. Experiments demonstrate that a simulation-trained agent can be deployed in emulation, and we show how to use the framework to train a general agent that transfers into novel, structurally different scenarios. NASimEmu is available as open-source.
Explaining Classifiers Trained on Raw Hierarchical Multiple-Instance Data
Aug 04, 2022
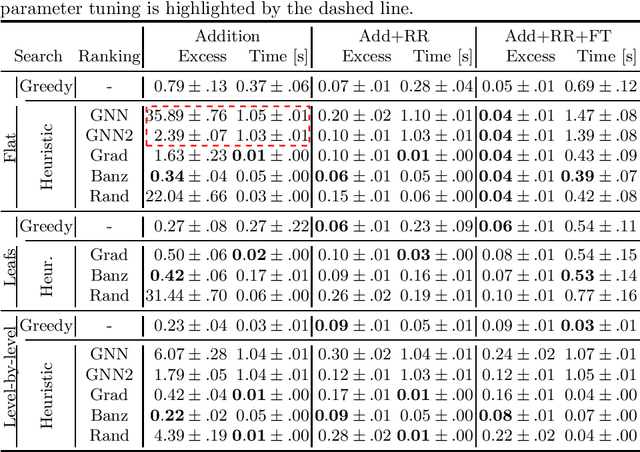

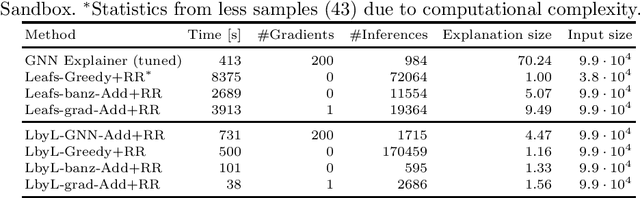
Learning from raw data input, thus limiting the need for feature engineering, is a component of many successful applications of machine learning methods in various domains. While many problems naturally translate into a vector representation directly usable in standard classifiers, a number of data sources have the natural form of structured data interchange formats (e.g., security logs in JSON/XML format). Existing methods, such as in Hierarchical Multiple Instance Learning (HMIL), allow learning from such data in their raw form. However, the explanation of the classifiers trained on raw structured data remains largely unexplored. By treating these models as sub-set selections problems, we demonstrate how interpretable explanations, with favourable properties, can be generated using computationally efficient algorithms. We compare to an explanation technique adopted from graph neural networks showing an order of magnitude speed-up and higher-quality explanations.
Fast Algorithms for Poker Require Modelling it as a Sequential Bayesian Game
Dec 20, 2021

Many recent results in imperfect information games were only formulated for, or evaluated on, poker and poker-like games such as liar's dice. We argue that sequential Bayesian games constitute a natural class of games for generalizing these results. In particular, this model allows for an elegant formulation of the counterfactual regret minimization algorithm, called public-state CFR (PS-CFR), which naturally lends itself to an efficient implementation. Empirically, solving a poker subgame with 10^7 states by public-state CFR takes 3 minutes and 700 MB while a comparable version of vanilla CFR takes 5.5 hours and 20 GB. Additionally, the public-state formulation of CFR opens up the possibility for exploiting domain-specific assumptions, leading to a quadratic reduction in asymptotic complexity (and a further empirical speedup) over vanilla CFR in poker and other domains. Overall, this suggests that the ability to represent poker as a sequential Bayesian game played a key role in the success of CFR-based methods. Finally, we extend public-state CFR to general extensive-form games, arguing that this extension enjoys some - but not all - of the benefits of the version for sequential Bayesian games.
Complexity and Algorithms for Exploiting Quantal Opponents in Large Two-Player Games
Sep 30, 2020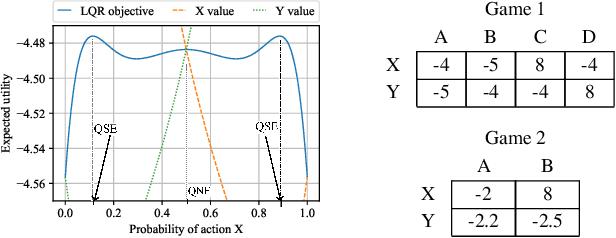
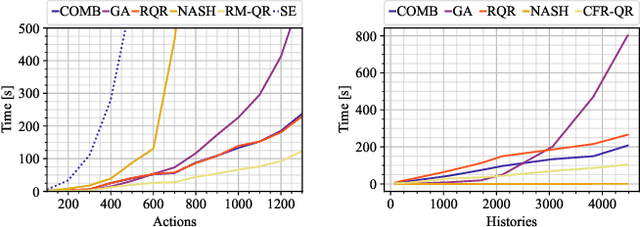
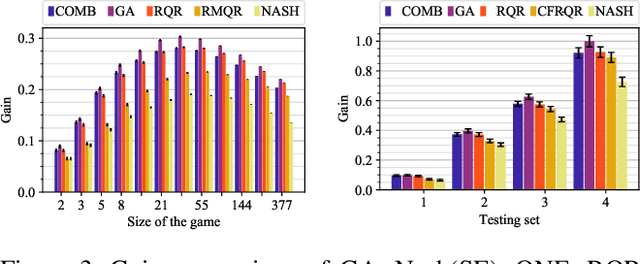
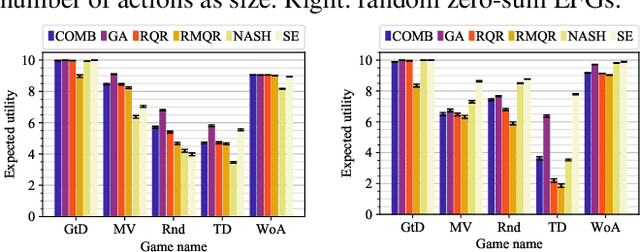
Solution concepts of traditional game theory assume entirely rational players; therefore, their ability to exploit subrational opponents is limited. One type of subrationality that describes human behavior well is the quantal response. While there exist algorithms for computing solutions against quantal opponents, they either do not scale or may provide strategies that are even worse than the entirely-rational Nash strategies. This paper aims to analyze and propose scalable algorithms for computing effective and robust strategies against a quantal opponent in normal-form and extensive-form games. Our contributions are: (1) we define two different solution concepts related to exploiting quantal opponents and analyze their properties; (2) we prove that computing these solutions is computationally hard; (3) therefore, we evaluate several heuristic approximations based on scalable counterfactual regret minimization (CFR); and (4) we identify a CFR variant that exploits the bounded opponents better than the previously used variants while being less exploitable by the worst-case perfectly-rational opponent.
Symbolic Relational Deep Reinforcement Learning based on Graph Neural Networks
Sep 25, 2020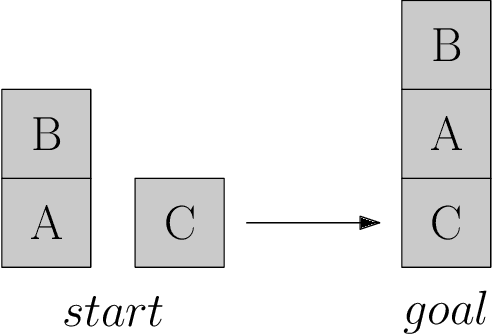
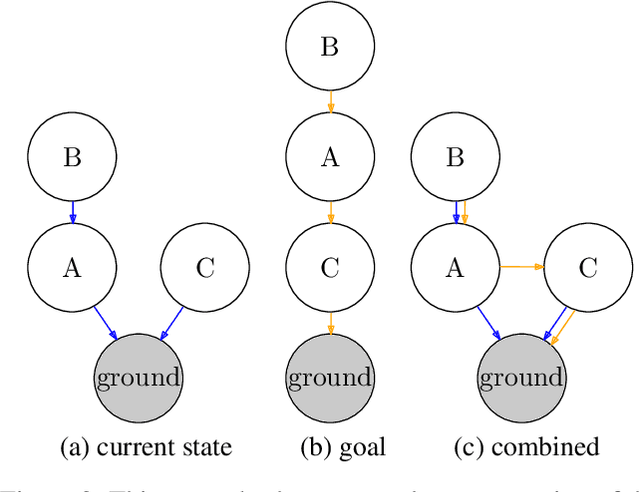
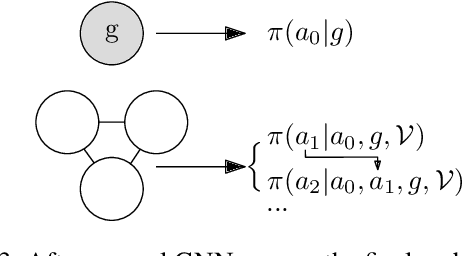
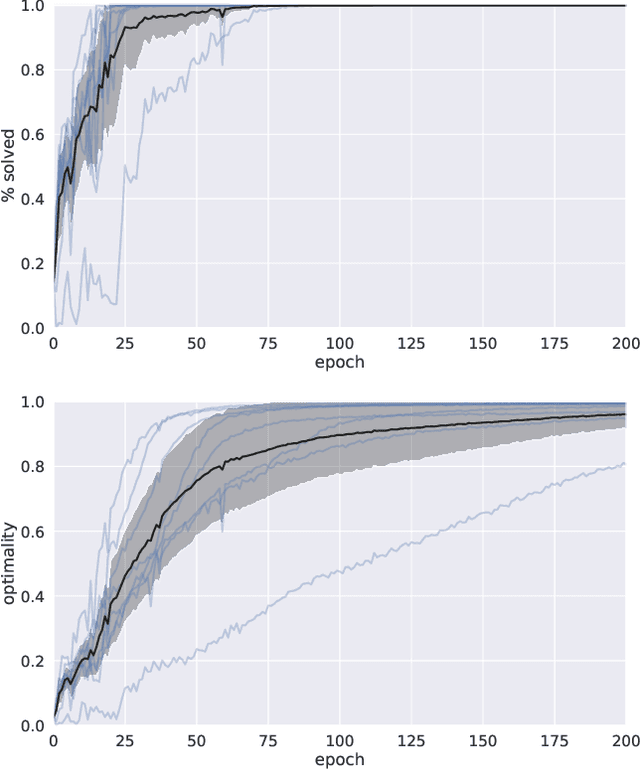
We present a novel deep reinforcement learning framework for solving relational problems. The method operates with a symbolic representation of objects, their relations and multi-parameter actions, where the objects are the parameters. Our framework, based on graph neural networks, is completely domain-independent and can be applied to any relational problem with existing symbolic-relational representation. We show how to represent relational states with arbitrary goals, multi-parameter actions and concurrent actions. We evaluate the method on a set of three domains: BlockWorld, Sokoban and SysAdmin. The method displays impressive generalization over different problem sizes (e.g., in BlockWorld, the method trained exclusively with 5 blocks still solves 78% of problems with 20 blocks) and readiness for curriculum learning.
Deep Reinforcement Learning with Explicitly Represented Knowledge and Variable State and Action Spaces
Nov 20, 2019
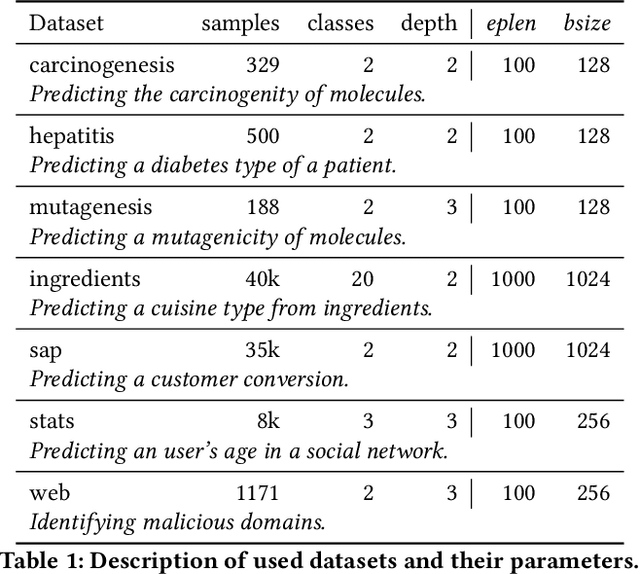
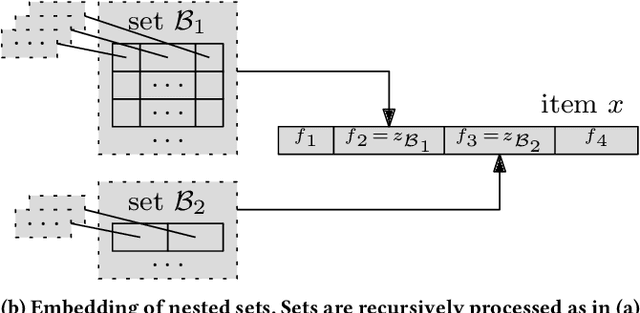
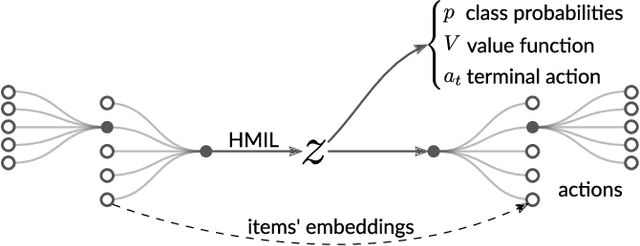
We focus on a class of real-world domains, where gathering hierarchical knowledge is required to accomplish a task. Many problems can be represented in this manner, such as network penetration testing, targeted advertising or medical diagnosis. In our formalization, the task is to sequentially request pieces of information about a sample to build the knowledge hierarchy and terminate when suitable. Any of the learned pieces of information can be further analyzed, resulting in a complex and variable action space. We present a combination of techniques in which the knowledge hierarchy is explicitly represented and given to a deep reinforcement learning algorithm as its input. To process the hierarchical input, we employ Hierarchical Multiple-Instance Learning and to cope with the complex action space, we factor it with hierarchical softmax. Our end-to-end differentiable model is trained with A2C, a standard deep reinforcement learning algorithm. We demonstrate the method in a set of seven classification domains, where the task is to achieve the best accuracy with a set budget on the amount of information retrieved. Compared to baseline algorithms, our method achieves not only better results, but also better generalization.
Classification with Costly Features as a Sequential Decision-Making Problem
Sep 05, 2019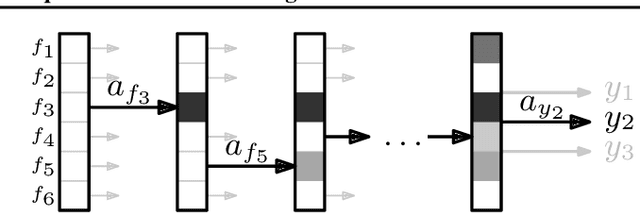
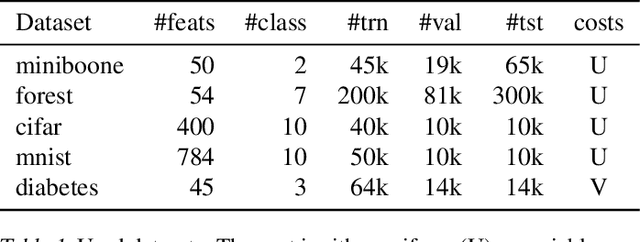
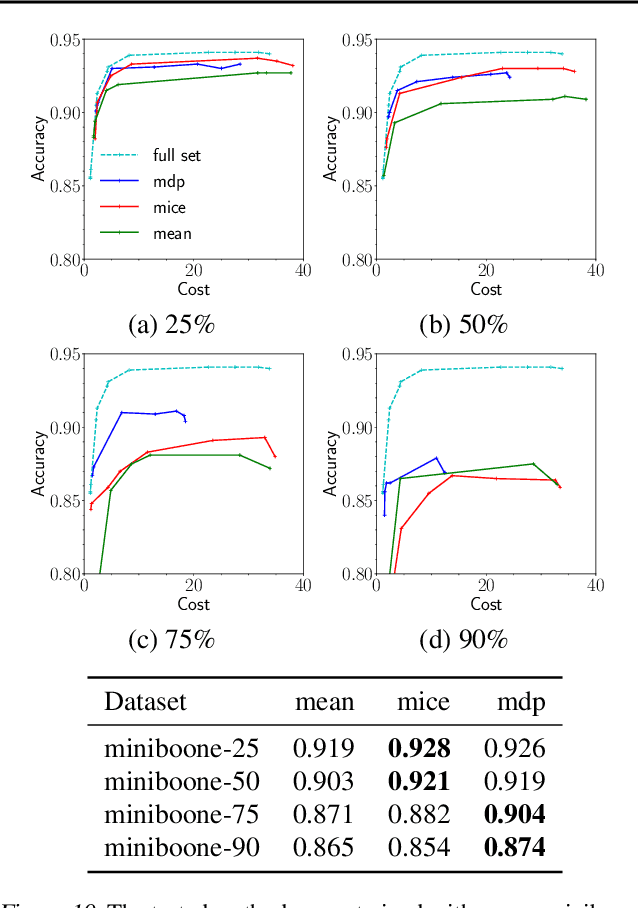
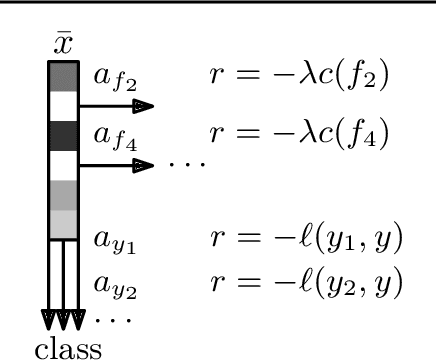
This work focuses on a specific classification problem, where the information about a sample is not readily available, but has to be acquired for a cost, and there is a per-sample budget. Inspired by real-world use-cases, we analyze average and hard variations of a directly specified budget. We postulate the problem in its explicit formulation and then convert it into an equivalent MDP, that can be solved with deep reinforcement learning. Also, we evaluate a real-world inspired setting with sparse training dataset with missing features. The presented method performs robustly well in all settings across several distinct datasets, outperforming other prior-art algorithms. The method is flexible, as showcased with all mentioned modifications and can be improved with any domain independent advancement in RL.