 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNASimEmu: Network Attack Simulator & Emulator for Training Agents Generalizing to Novel Scenarios
May 26, 2023Current frameworks for training offensive penetration testing agents with deep reinforcement learning struggle to produce agents that perform well in real-world scenarios, due to the reality gap in simulation-based frameworks and the lack of scalability in emulation-based frameworks. Additionally, existing frameworks often use an unrealistic metric that measures the agents' performance on the training data. NASimEmu, a new framework introduced in this paper, addresses these issues by providing both a simulator and an emulator with a shared interface. This approach allows agents to be trained in simulation and deployed in the emulator, thus verifying the realism of the used abstraction. Our framework promotes the development of general agents that can transfer to novel scenarios unseen during their training. For the simulation part, we adopt an existing simulator NASim and enhance its realism. The emulator is implemented with industry-level tools, such as Vagrant, VirtualBox, and Metasploit. Experiments demonstrate that a simulation-trained agent can be deployed in emulation, and we show how to use the framework to train a general agent that transfers into novel, structurally different scenarios. NASimEmu is available as open-source.
Symbolic Relational Deep Reinforcement Learning based on Graph Neural Networks
Sep 25, 2020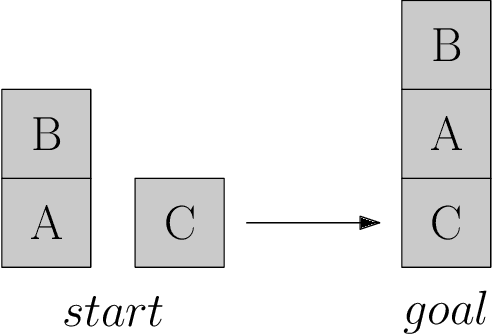
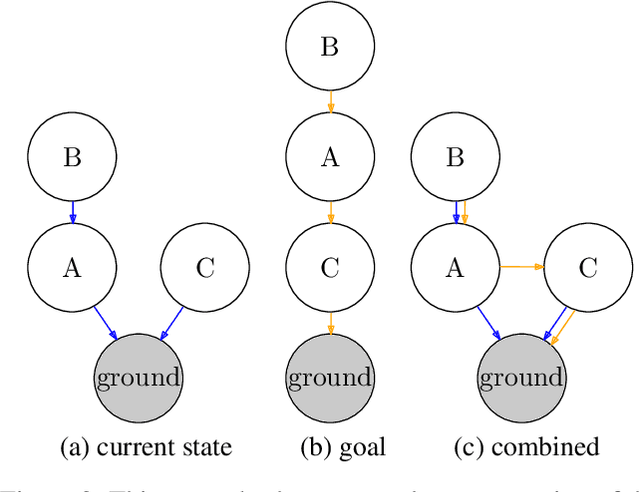
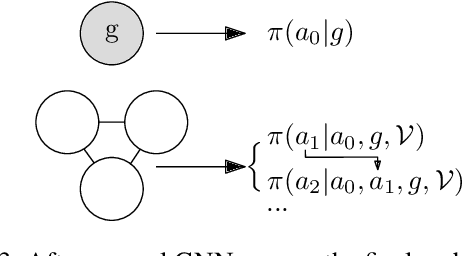
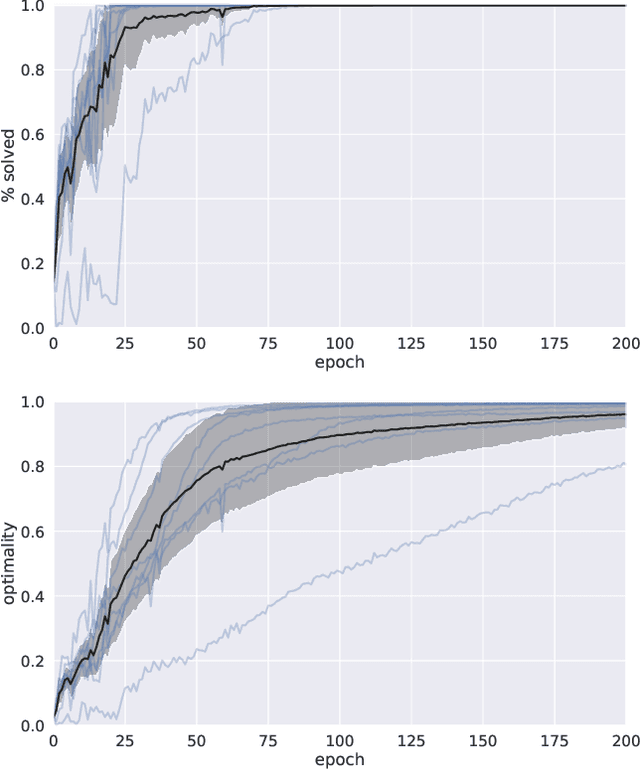
We present a novel deep reinforcement learning framework for solving relational problems. The method operates with a symbolic representation of objects, their relations and multi-parameter actions, where the objects are the parameters. Our framework, based on graph neural networks, is completely domain-independent and can be applied to any relational problem with existing symbolic-relational representation. We show how to represent relational states with arbitrary goals, multi-parameter actions and concurrent actions. We evaluate the method on a set of three domains: BlockWorld, Sokoban and SysAdmin. The method displays impressive generalization over different problem sizes (e.g., in BlockWorld, the method trained exclusively with 5 blocks still solves 78% of problems with 20 blocks) and readiness for curriculum learning.
Deep Reinforcement Learning with Explicitly Represented Knowledge and Variable State and Action Spaces
Nov 20, 2019
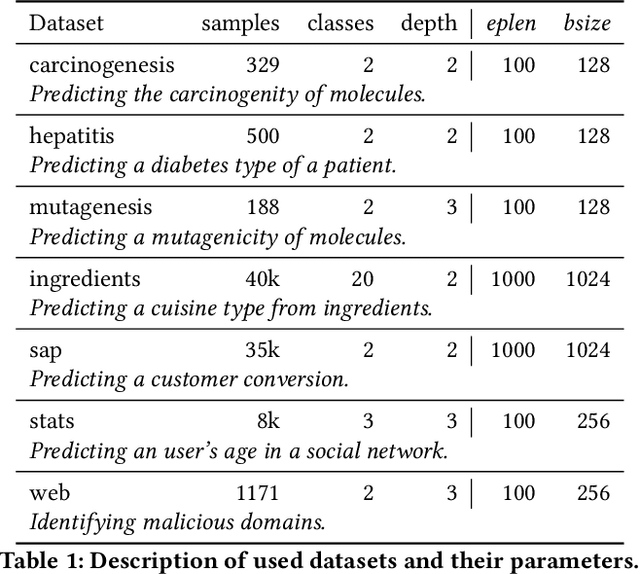
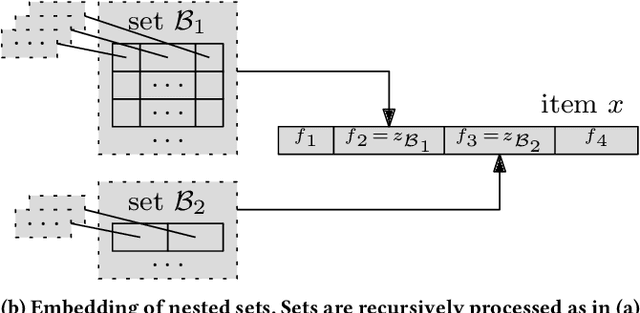
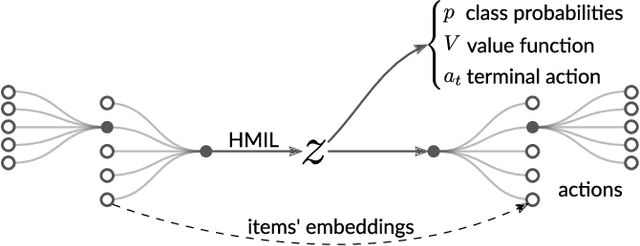
We focus on a class of real-world domains, where gathering hierarchical knowledge is required to accomplish a task. Many problems can be represented in this manner, such as network penetration testing, targeted advertising or medical diagnosis. In our formalization, the task is to sequentially request pieces of information about a sample to build the knowledge hierarchy and terminate when suitable. Any of the learned pieces of information can be further analyzed, resulting in a complex and variable action space. We present a combination of techniques in which the knowledge hierarchy is explicitly represented and given to a deep reinforcement learning algorithm as its input. To process the hierarchical input, we employ Hierarchical Multiple-Instance Learning and to cope with the complex action space, we factor it with hierarchical softmax. Our end-to-end differentiable model is trained with A2C, a standard deep reinforcement learning algorithm. We demonstrate the method in a set of seven classification domains, where the task is to achieve the best accuracy with a set budget on the amount of information retrieved. Compared to baseline algorithms, our method achieves not only better results, but also better generalization.
Classification with Costly Features as a Sequential Decision-Making Problem
Sep 05, 2019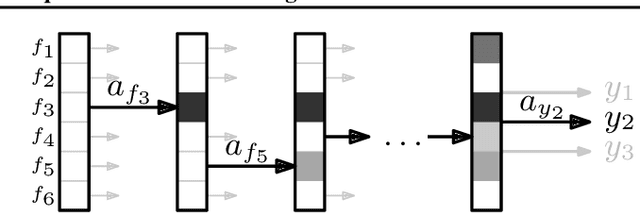
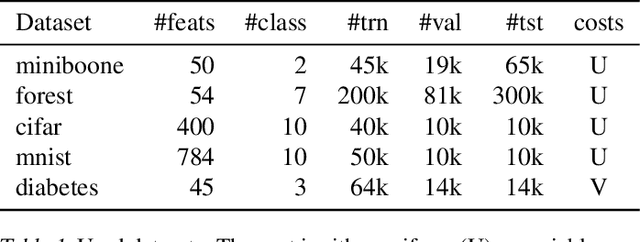
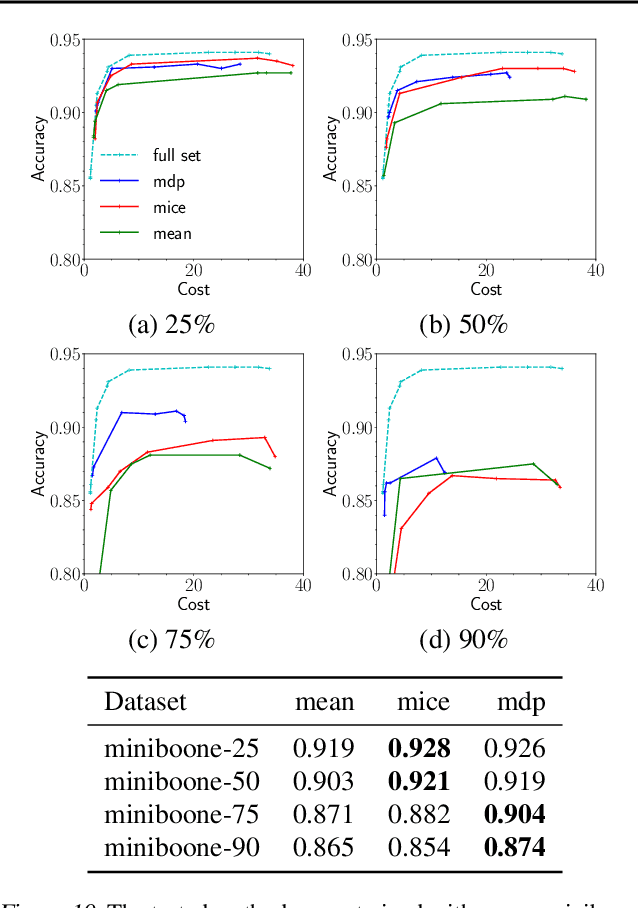
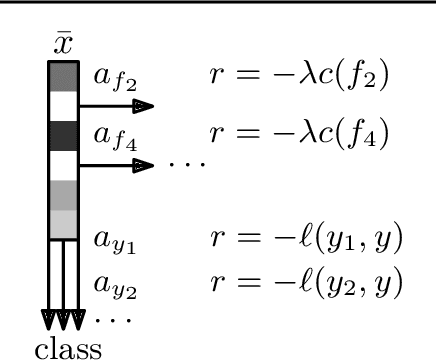
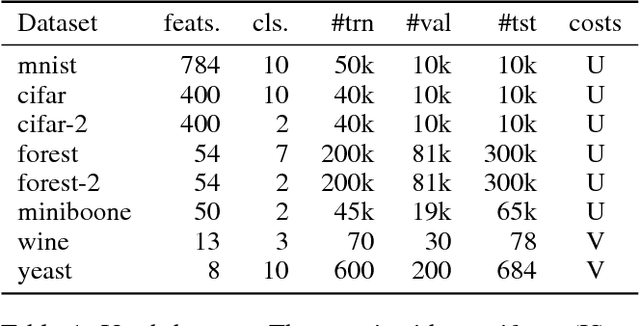
This work focuses on a specific classification problem, where the information about a sample is not readily available, but has to be acquired for a cost, and there is a per-sample budget. Inspired by real-world use-cases, we analyze average and hard variations of a directly specified budget. We postulate the problem in its explicit formulation and then convert it into an equivalent MDP, that can be solved with deep reinforcement learning. Also, we evaluate a real-world inspired setting with sparse training dataset with missing features. The presented method performs robustly well in all settings across several distinct datasets, outperforming other prior-art algorithms. The method is flexible, as showcased with all mentioned modifications and can be improved with any domain independent advancement in RL.
Classification with Costly Features using Deep Reinforcement Learning
Nov 20, 2017
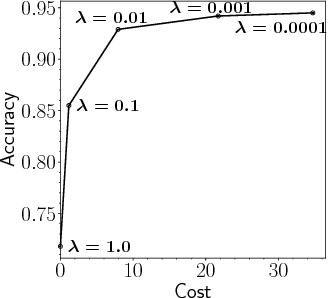
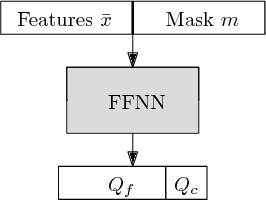
We study a classification problem where each feature can be acquired for a cost and the goal is to optimize the trade-off between classification precision and the total feature cost. We frame the problem as a sequential decision-making problem, where we classify one sample in each episode. At each step, an agent can use values of acquired features to decide whether to purchase another one or whether to classify the sample. We use vanilla Double Deep Q-learning, a standard reinforcement learning technique, to find a classification policy. We show that this generic approach outperforms Adapt-Gbrt, currently the best-performing algorithm developed specifically for classification with costly features.