 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntersectional Fairness via Mixed-Integer Optimization
Jan 27, 2026The deployment of Artificial Intelligence in high-risk domains, such as finance and healthcare, necessitates models that are both fair and transparent. While regulatory frameworks, including the EU's AI Act, mandate bias mitigation, they are deliberately vague about the definition of bias. In line with existing research, we argue that true fairness requires addressing bias at the intersections of protected groups. We propose a unified framework that leverages Mixed-Integer Optimization (MIO) to train intersectionally fair and intrinsically interpretable classifiers. We prove the equivalence of two measures of intersectional fairness (MSD and SPSF) in detecting the most unfair subgroup and empirically demonstrate that our MIO-based algorithm improves performance in finding bias. We train high-performing, interpretable classifiers that bound intersectional bias below an acceptable threshold, offering a robust solution for regulated industries and beyond.
Targeted Pooled Latent-Space Steganalysis Applied to Generative Steganography, with a Fix
Oct 14, 2025Steganographic schemes dedicated to generated images modify the seed vector in the latent space to embed a message, whereas most steganalysis methods attempt to detect the embedding in the image space. This paper proposes to perform steganalysis in the latent space by modeling the statistical distribution of the norm of the latent vector. Specifically, we analyze the practical security of a scheme proposed by Hu et. al. for latent diffusion models, which is both robust and practically undetectable when steganalysis is performed on generated images. We show that after embedding, the Stego (latent) vector is distributed on a hypersphere while the Cover vector is i.i.d. Gaussian. By going from the image space to the latent space, we show that it is possible to model the norm of the vector in the latent space under the Cover or Stego hypothesis as Gaussian distributions with different variances. A Likelihood Ratio Test is then derived to perform pooled steganalysis. The impact of the potential knowledge of the prompt and the number of diffusion steps, is also studied. Additionally, we also show how, by randomly sampling the norm of the latent vector before generation, the initial Stego scheme becomes undetectable in the latent space.
Sparse Probabilistic Graph Circuits
Aug 11, 2025Deep generative models (DGMs) for graphs achieve impressively high expressive power thanks to very efficient and scalable neural networks. However, these networks contain non-linearities that prevent analytical computation of many standard probabilistic inference queries, i.e., these DGMs are considered \emph{intractable}. While recently proposed Probabilistic Graph Circuits (PGCs) address this issue by enabling \emph{tractable} probabilistic inference, they operate on dense graph representations with $\mathcal{O}(n^2)$ complexity for graphs with $n$ nodes and \emph{$m$ edges}. To address this scalability issue, we introduce Sparse PGCs, a new class of tractable generative models that operate directly on sparse graph representation, reducing the complexity to $\mathcal{O}(n + m)$, which is particularly beneficial for $m \ll n^2$. In the context of de novo drug design, we empirically demonstrate that SPGCs retain exact inference capabilities, improve memory efficiency and inference speed, and match the performance of intractable DGMs in key metrics.
Probabilistic Graph Circuits: Deep Generative Models for Tractable Probabilistic Inference over Graphs
Mar 15, 2025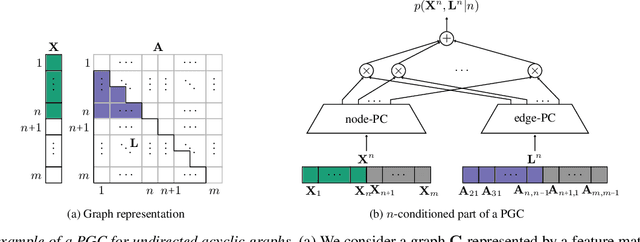
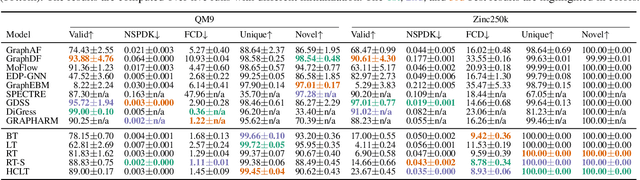
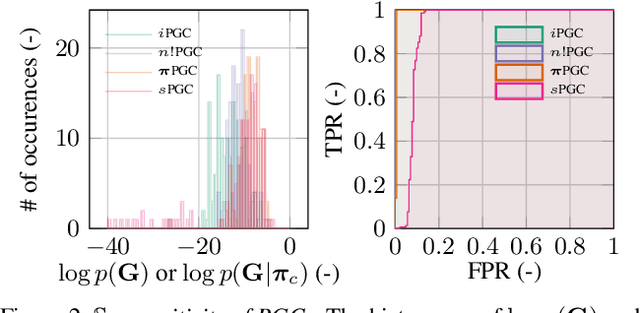
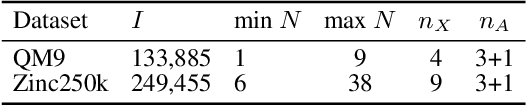
Deep generative models (DGMs) have recently demonstrated remarkable success in capturing complex probability distributions over graphs. Although their excellent performance is attributed to powerful and scalable deep neural networks, it is, at the same time, exactly the presence of these highly non-linear transformations that makes DGMs intractable. Indeed, despite representing probability distributions, intractable DGMs deny probabilistic foundations by their inability to answer even the most basic inference queries without approximations or design choices specific to a very narrow range of queries. To address this limitation, we propose probabilistic graph circuits (PGCs), a framework of tractable DGMs that provide exact and efficient probabilistic inference over (arbitrary parts of) graphs. Nonetheless, achieving both exactness and efficiency is challenging in the permutation-invariant setting of graphs. We design PGCs that are inherently invariant and satisfy these two requirements, yet at the cost of low expressive power. Therefore, we investigate two alternative strategies to achieve the invariance: the first sacrifices the efficiency, and the second sacrifices the exactness. We demonstrate that ignoring the permutation invariance can have severe consequences in anomaly detection, and that the latter approach is competitive with, and sometimes better than, existing intractable DGMs in the context of molecular graph generation.
Bias Detection via Maximum Subgroup Discrepancy
Feb 04, 2025



Bias evaluation is fundamental to trustworthy AI, both in terms of checking data quality and in terms of checking the outputs of AI systems. In testing data quality, for example, one may study a distance of a given dataset, viewed as a distribution, to a given ground-truth reference dataset. However, classical metrics, such as the Total Variation and the Wasserstein distances, are known to have high sample complexities and, therefore, may fail to provide meaningful distinction in many practical scenarios. In this paper, we propose a new notion of distance, the Maximum Subgroup Discrepancy (MSD). In this metric, two distributions are close if, roughly, discrepancies are low for all feature subgroups. While the number of subgroups may be exponential, we show that the sample complexity is linear in the number of features, thus making it feasible for practical applications. Moreover, we provide a practical algorithm for the evaluation of the distance, based on Mixed-integer optimization (MIO). We also note that the proposed distance is easily interpretable, thus providing clearer paths to fixing the biases once they have been identified. It also provides guarantees for all subgroups. Finally, we empirically evaluate, compare with other metrics, and demonstrate the above properties of MSD on real-world datasets.
GraphSPNs: Sum-Product Networks Benefit From Canonical Orderings
Aug 18, 2024Deep generative models have recently made a remarkable progress in capturing complex probability distributions over graphs. However, they are intractable and thus unable to answer even the most basic probabilistic inference queries without resorting to approximations. Therefore, we propose graph sum-product networks (GraphSPNs), a tractable deep generative model which provides exact and efficient inference over (arbitrary parts of) graphs. We investigate different principles to make SPNs permutation invariant. We demonstrate that GraphSPNs are able to (conditionally) generate novel and chemically valid molecular graphs, being competitive to, and sometimes even better than, existing intractable models. We find out that (Graph)SPNs benefit from ensuring the permutation invariance via canonical ordering.
Sum-Product-Set Networks: Deep Tractable Models for Tree-Structured Graphs
Aug 18, 2024
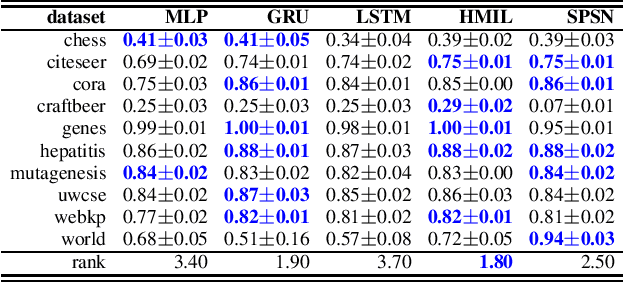

Daily internet communication relies heavily on tree-structured graphs, embodied by popular data formats such as XML and JSON. However, many recent generative (probabilistic) models utilize neural networks to learn a probability distribution over undirected cyclic graphs. This assumption of a generic graph structure brings various computational challenges, and, more importantly, the presence of non-linearities in neural networks does not permit tractable probabilistic inference. We address these problems by proposing sum-product-set networks, an extension of probabilistic circuits from unstructured tensor data to tree-structured graph data. To this end, we use random finite sets to reflect a variable number of nodes and edges in the graph and to allow for exact and efficient inference. We demonstrate that our tractable model performs comparably to various intractable models based on neural networks.
Sum-Product-Set Networks
Aug 14, 2024Daily internet communication relies heavily on tree-structured graphs, embodied by popular data formats such as XML and JSON. However, many recent generative (probabilistic) models utilize neural networks to learn a probability distribution over undirected cyclic graphs. This assumption of a generic graph structure brings various computational challenges, and, more importantly, the presence of non-linearities in neural networks does not permit tractable probabilistic inference. We address these problems by proposing sum-product-set networks, an extension of probabilistic circuits from unstructured tensor data to tree-structured graph data. To this end, we use random finite sets to reflect a variable number of nodes and edges in the graph and to allow for exact and efficient inference. We demonstrate that our tractable model performs comparably to various intractable models based on neural networks.
Blind Data Adaptation to tackle Covariate Shift in Operational Steganalysis
May 29, 2024



The proliferation of image manipulation for unethical purposes poses significant challenges in social networks. One particularly concerning method is Image Steganography, allowing individuals to hide illegal information in digital images without arousing suspicions. Such a technique pose severe security risks, making it crucial to develop effective steganalysis methods enabling to detect manipulated images for clandestine communications. Although significant advancements have been achieved with machine learning models, a critical issue remains: the disparity between the controlled datasets used to train steganalysis models against real-world datasets of forensic practitioners, undermining severely the practical effectiveness of standardized steganalysis models. In this paper, we address this issue focusing on a realistic scenario where practitioners lack crucial information about the limited target set of images under analysis, including details about their development process and even whereas it contains manipulated images or not. By leveraging geometric alignment and distribution matching of source and target residuals, we develop TADA (Target Alignment through Data Adaptation), a novel methodology enabling to emulate sources aligned with specific targets in steganalysis, which is also relevant for highly unbalanced targets. The emulator is represented by a light convolutional network trained to align distributions of image residuals. Experimental validation demonstrates the potential of our strategy over traditional methods fighting covariate shift in steganalysis.
Leveraging Data Geometry to Mitigate CSM in Steganalysis
Oct 06, 2023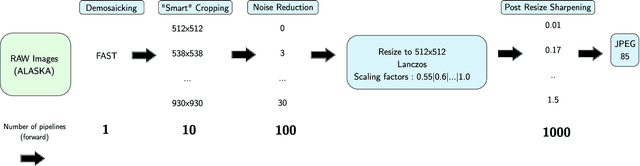
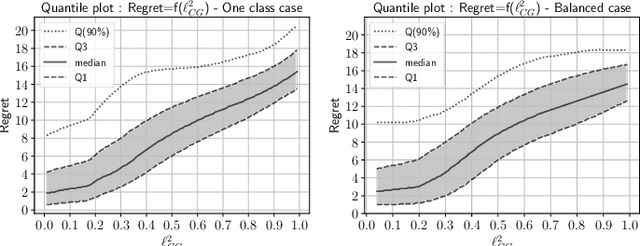
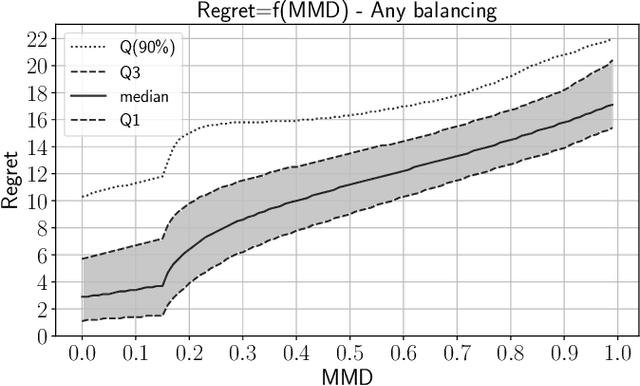
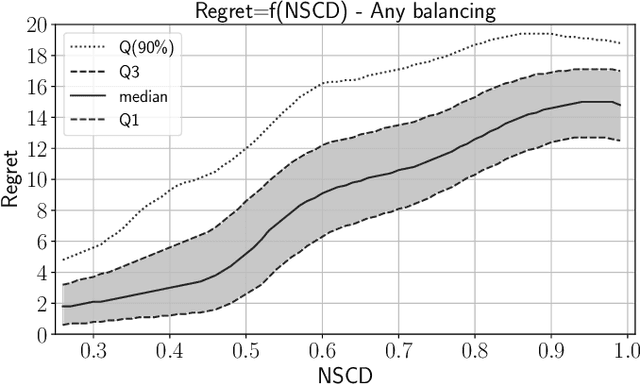
In operational scenarios, steganographers use sets of covers from various sensors and processing pipelines that differ significantly from those used by researchers to train steganalysis models. This leads to an inevitable performance gap when dealing with out-of-distribution covers, commonly referred to as Cover Source Mismatch (CSM). In this study, we consider the scenario where test images are processed using the same pipeline. However, knowledge regarding both the labels and the balance between cover and stego is missing. Our objective is to identify a training dataset that allows for maximum generalization to our target. By exploring a grid of processing pipelines fostering CSM, we discovered a geometrical metric based on the chordal distance between subspaces spanned by DCTr features, that exhibits high correlation with operational regret while being not affected by the cover-stego balance. Our contribution lies in the development of a strategy that enables the selection or derivation of customized training datasets, enhancing the overall generalization performance for a given target. Experimental validation highlights that our geometry-based optimization strategy outperforms traditional atomistic methods given reasonable assumptions. Additional resources are available at github.com/RonyAbecidan/LeveragingGeometrytoMitigateCSM.