 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Pooled Latent-Space Steganalysis Applied to Generative Steganography, with a Fix
Oct 14, 2025Steganographic schemes dedicated to generated images modify the seed vector in the latent space to embed a message, whereas most steganalysis methods attempt to detect the embedding in the image space. This paper proposes to perform steganalysis in the latent space by modeling the statistical distribution of the norm of the latent vector. Specifically, we analyze the practical security of a scheme proposed by Hu et. al. for latent diffusion models, which is both robust and practically undetectable when steganalysis is performed on generated images. We show that after embedding, the Stego (latent) vector is distributed on a hypersphere while the Cover vector is i.i.d. Gaussian. By going from the image space to the latent space, we show that it is possible to model the norm of the vector in the latent space under the Cover or Stego hypothesis as Gaussian distributions with different variances. A Likelihood Ratio Test is then derived to perform pooled steganalysis. The impact of the potential knowledge of the prompt and the number of diffusion steps, is also studied. Additionally, we also show how, by randomly sampling the norm of the latent vector before generation, the initial Stego scheme becomes undetectable in the latent space.
Pick the Largest Margin for Robust Detection of Splicing
Sep 05, 2024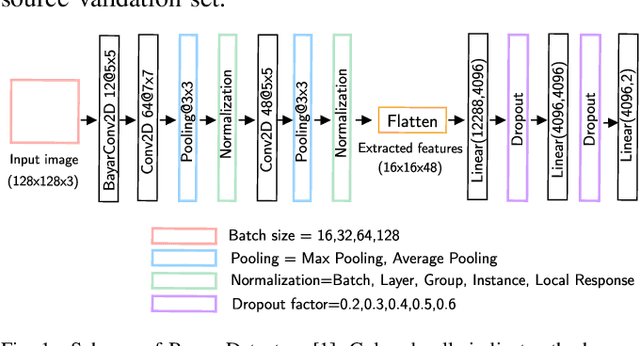
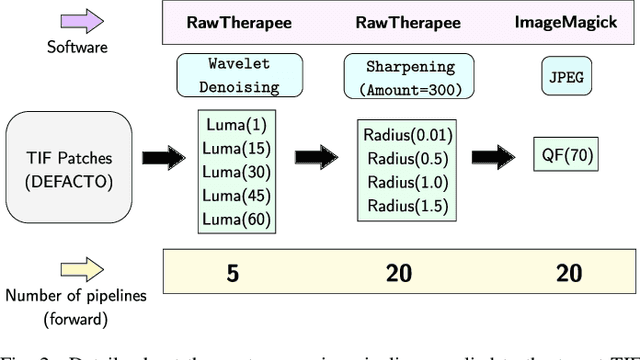
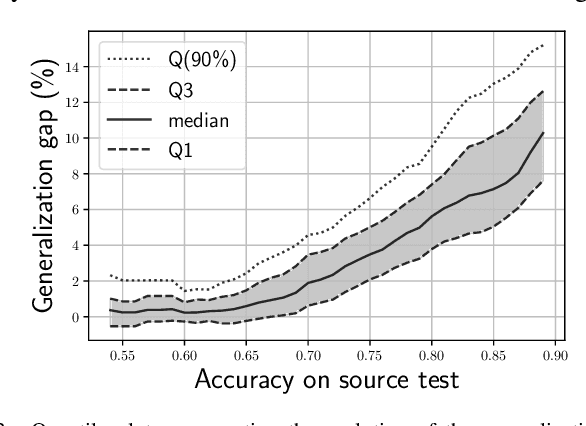
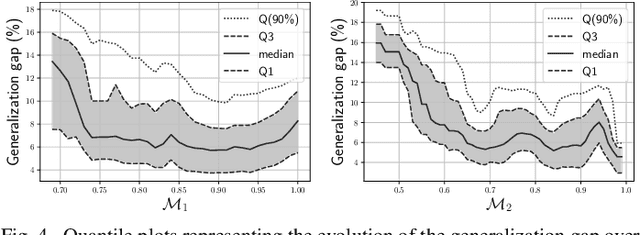
Despite advancements in splicing detection, practitioners still struggle to fully leverage forensic tools from the literature due to a critical issue: deep learning-based detectors are extremely sensitive to their trained instances. Simple post-processing applied to evaluation images can easily decrease their performances, leading to a lack of confidence in splicing detectors for operational contexts. In this study, we show that a deep splicing detector behaves differently against unknown post-processes for different learned weights, even if it achieves similar performances on a test set from the same distribution as its training one. We connect this observation to the fact that different learnings create different latent spaces separating training samples differently. Our experiments reveal a strong correlation between the distributions of latent margins and the ability of the detector to generalize to post-processed images. We thus provide to the practitioner a way to build deep detectors that are more robust than others against post-processing operations, suggesting to train their architecture under different conditions and picking the one maximizing the latent space margin.
Dual JPEG Compatibility: a Reliable and Explainable Tool for Image Forensics
Aug 30, 2024Given a JPEG pipeline (compression or decompression), this paper shows how to find the antecedent of a 8 x 8 block. If it exists, the block is compatible with the pipeline. For unaltered images, all blocks are always compatible with the original pipeline; however, for manipulated images, this is not always the case. This article demonstrates the potential of compatibility concepts for JPEG image forensics. It presents a solution to the main challenge of finding a block antecedent in a high-dimensional space. This solution relies on a local search algorithm with restrictions on the search space. We show that inpainting, copy-move, or splicing applied after a JPEG compression can be turned into three different mismatch problems and be detected. In particular, when the image is re-compressed after the modification, we can detect the manipulation if the quality factor of the second compression is higher than the first one. Our method can pinpoint forgeries down to the JPEG block with great detection power and without False Positive. We compare our method with two state-of-the-art models on localizing inpainted forgeries after a simple or a double compression. We show that under our working assumptions, it outperforms those models for most experiments.
Blind Data Adaptation to tackle Covariate Shift in Operational Steganalysis
May 29, 2024



The proliferation of image manipulation for unethical purposes poses significant challenges in social networks. One particularly concerning method is Image Steganography, allowing individuals to hide illegal information in digital images without arousing suspicions. Such a technique pose severe security risks, making it crucial to develop effective steganalysis methods enabling to detect manipulated images for clandestine communications. Although significant advancements have been achieved with machine learning models, a critical issue remains: the disparity between the controlled datasets used to train steganalysis models against real-world datasets of forensic practitioners, undermining severely the practical effectiveness of standardized steganalysis models. In this paper, we address this issue focusing on a realistic scenario where practitioners lack crucial information about the limited target set of images under analysis, including details about their development process and even whereas it contains manipulated images or not. By leveraging geometric alignment and distribution matching of source and target residuals, we develop TADA (Target Alignment through Data Adaptation), a novel methodology enabling to emulate sources aligned with specific targets in steganalysis, which is also relevant for highly unbalanced targets. The emulator is represented by a light convolutional network trained to align distributions of image residuals. Experimental validation demonstrates the potential of our strategy over traditional methods fighting covariate shift in steganalysis.
Leveraging Data Geometry to Mitigate CSM in Steganalysis
Oct 06, 2023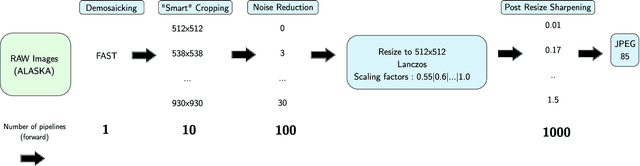
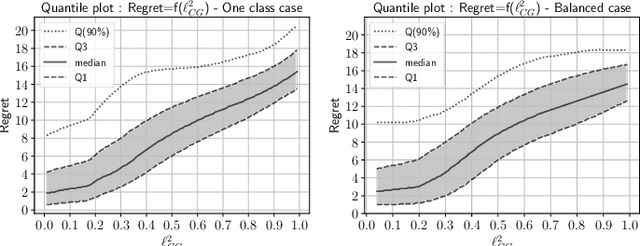
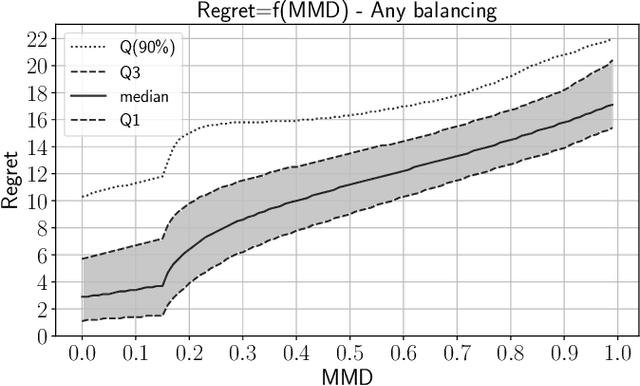
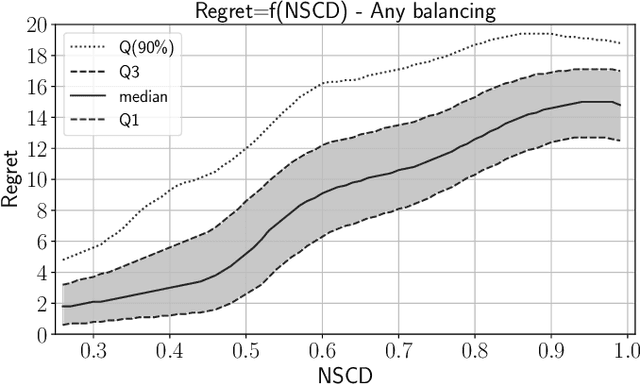
In operational scenarios, steganographers use sets of covers from various sensors and processing pipelines that differ significantly from those used by researchers to train steganalysis models. This leads to an inevitable performance gap when dealing with out-of-distribution covers, commonly referred to as Cover Source Mismatch (CSM). In this study, we consider the scenario where test images are processed using the same pipeline. However, knowledge regarding both the labels and the balance between cover and stego is missing. Our objective is to identify a training dataset that allows for maximum generalization to our target. By exploring a grid of processing pipelines fostering CSM, we discovered a geometrical metric based on the chordal distance between subspaces spanned by DCTr features, that exhibits high correlation with operational regret while being not affected by the cover-stego balance. Our contribution lies in the development of a strategy that enables the selection or derivation of customized training datasets, enhancing the overall generalization performance for a given target. Experimental validation highlights that our geometry-based optimization strategy outperforms traditional atomistic methods given reasonable assumptions. Additional resources are available at github.com/RonyAbecidan/LeveragingGeometrytoMitigateCSM.
Side-Informed Steganography for JPEG Images by Modeling Decompressed Images
Nov 09, 2022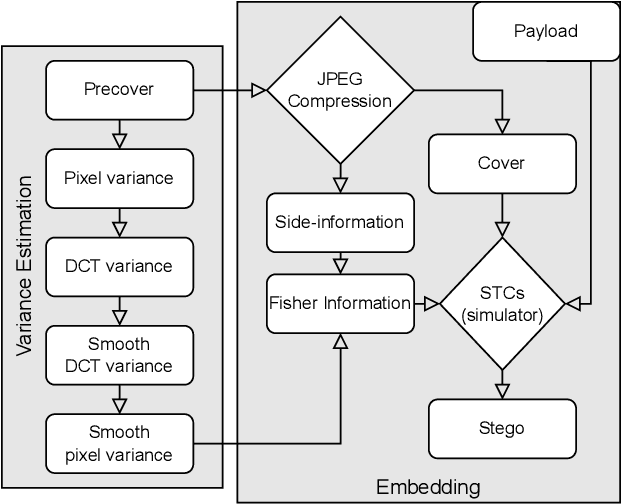
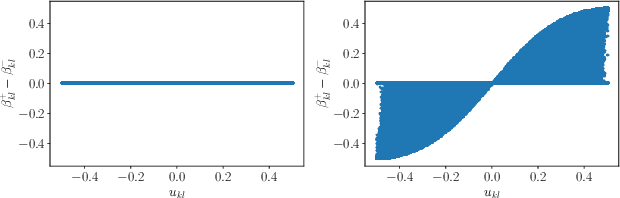
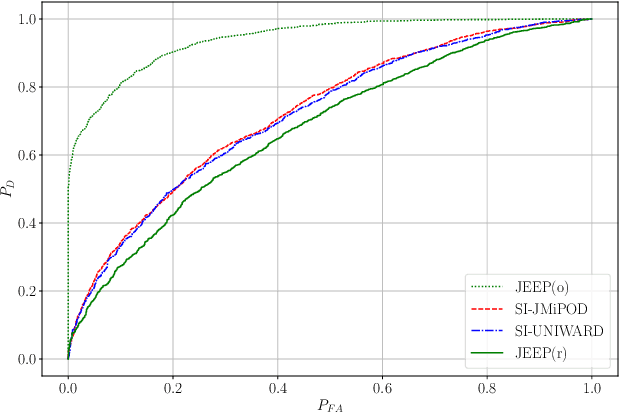
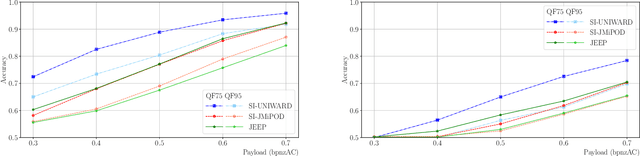
Side-informed steganography has always been among the most secure approaches in the field. However, a majority of existing methods for JPEG images use the side information, here the rounding error, in a heuristic way. For the first time, we show that the usefulness of the rounding error comes from its covariance with the embedding changes. Unfortunately, this covariance between continuous and discrete variables is not analytically available. An estimate of the covariance is proposed, which allows to model steganography as a change in the variance of DCT coefficients. Since steganalysis today is best performed in the spatial domain, we derive a likelihood ratio test to preserve a model of a decompressed JPEG image. The proposed method then bounds the power of this test by minimizing the Kullback-Leibler divergence between the cover and stego distributions. We experimentally demonstrate in two popular datasets that it achieves state-of-the-art performance against deep learning detectors. Moreover, by considering a different pixel variance estimator for images compressed with Quality Factor 100, even greater improvements are obtained.
Errorless Robust JPEG Steganography using Outputs of JPEG Coders
Nov 09, 2022Robust steganography is a technique of hiding secret messages in images so that the message can be recovered after additional image processing. One of the most popular processing operations is JPEG recompression. Unfortunately, most of today's steganographic methods addressing this issue only provide a probabilistic guarantee of recovering the secret and are consequently not errorless. That is unacceptable since even a single unexpected change can make the whole message unreadable if it is encrypted. We propose to create a robust set of DCT coefficients by inspecting their behavior during recompression, which requires access to the targeted JPEG compressor. This is done by dividing the DCT coefficients into 64 non-overlapping lattices because one embedding change can potentially affect many other coefficients from the same DCT block during recompression. The robustness is then combined with standard steganographic costs creating a lattice embedding scheme robust against JPEG recompression. Through experiments, we show that the size of the robust set and the scheme's security depends on the ordering of lattices during embedding. We verify the validity of the proposed method with three typical JPEG compressors and benchmark its security for various embedding payloads, three different ways of ordering the lattices, and a range of Quality Factors. Finally, this method is errorless by construction, meaning the embedded message will always be readable.
Using Set Covering to Generate Databases for Holistic Steganalysis
Nov 07, 2022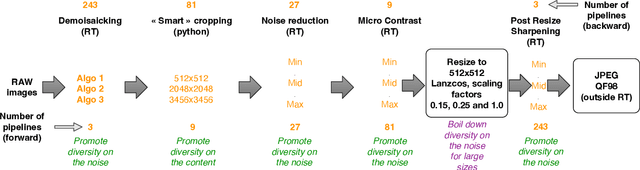
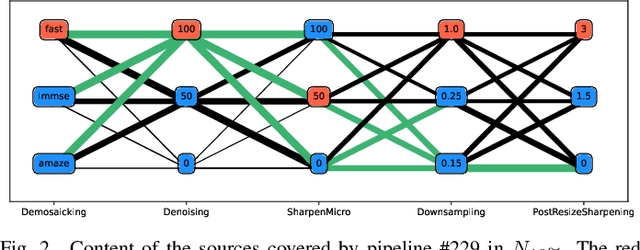
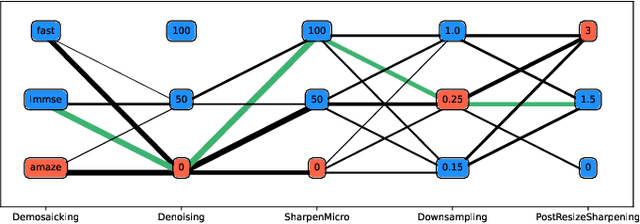
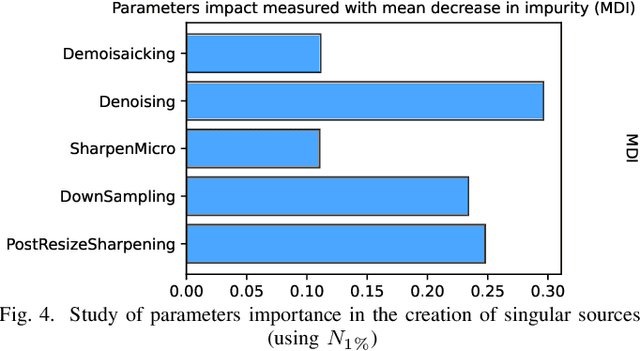
Within an operational framework, covers used by a steganographer are likely to come from different sensors and different processing pipelines than the ones used by researchers for training their steganalysis models. Thus, a performance gap is unavoidable when it comes to out-of-distributions covers, an extremely frequent scenario called Cover Source Mismatch (CSM). Here, we explore a grid of processing pipelines to study the origins of CSM, to better understand it, and to better tackle it. A set-covering greedy algorithm is used to select representative pipelines minimizing the maximum regret between the representative and the pipelines within the set. Our main contribution is a methodology for generating relevant bases able to tackle operational CSM. Experimental validation highlights that, for a given number of training samples, our set covering selection is a better strategy than selecting random pipelines or using all the available pipelines. Our analysis also shows that parameters as denoising, sharpening, and downsampling are very important to foster diversity. Finally, different benchmarks for classical and wild databases show the good generalization property of the extracted databases. Additional resources are available at github.com/RonyAbecidan/HolisticSteganalysisWithSetCovering.
Combining Forensics and Privacy Requirements for Digital Images
Mar 05, 2021



This paper proposes to study the impact of image selective encryption on both forensics and privacy preserving mechanisms. The proposed selective encryption scheme works independently on each bitplane by encrypting the s most significant bits of each pixel. We show that this mechanism can be used to increase privacy by mitigating image recognition tasks. In order to guarantee a trade-off between forensics analysis and privacy, the signal of interest used for forensics purposes is extracted from the 8--s least significant bits of the protected image. We show on the CASIA2 database that good tampering detection capabilities can be achieved for s $\in$ {3,. .. , 5} with an accuracy above 80% using SRMQ1 features, while preventing class recognition tasks using CNN with an accuracy smaller than 50%.